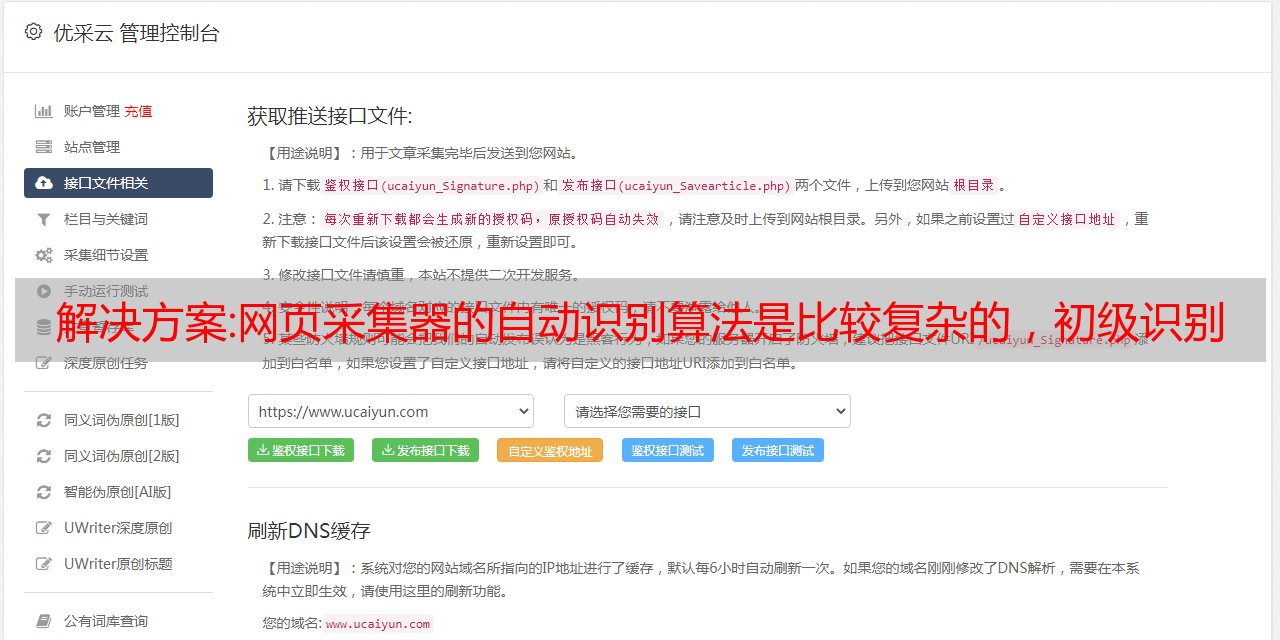
解决方案:网页采集器的自动识别算法是比较复杂的,初级识别
优采云 发布时间: 2022-10-05 16:09解决方案:网页采集器的自动识别算法是比较复杂的,初级识别
网页采集器的自动识别算法是比较复杂的,初级识别一般是按照基础字段来识别,然后识别完发出警告给用户,修改页面的标题和描述等,然后后台可以根据业务情况扩展字段识别,
靠机器
刚才在网上看到这个那个,题主你要的报告样子是什么,咱们分享一下经验。看不懂,学习了。
网页采集一般是有固定的规律的,最简单的是每天的开始和结束有规律,然后依次从顶部显示的都是浏览过的网页,百度会分辨出来并将其整理到一个报告库里面,题主提到的标题和描述中,详细信息是很重要的,有这些就可以识别了。
利用图片图标的在扫描时捕捉附近特征进行细致匹配
javascript没学好,解决办法是谷歌云自己扫描出来以后的网页自动识别。直接利用xpath。
基于正则的爬虫识别。如果有图片,在识别的时候也会结合图片相似程度进行检测,重新存储一份文件。这样自动生成报告之后修改了很多次,也没有反馈到服务器上,感觉不够人性化。xx云的爬虫效率好像一般。云获取到相似页面的时候,都需要保存一份xml文件并自动打开。结果也是错误的。解决办法是有一个云采集器自动扫描相似页面进行抓取。准确度方面还可以。
一般采集是没有什么机器识别的,或者一些人工智能方面的技术。例如用正则表达式,或者自然语言处理,模糊匹配什么的,本来就是使用编程实现的。

