教程:网页文章自动采集从python爬虫的基础--简单采集新闻头条
优采云 发布时间: 2022-10-05 10:15教程:网页文章自动采集从python爬虫的基础--简单采集新闻头条
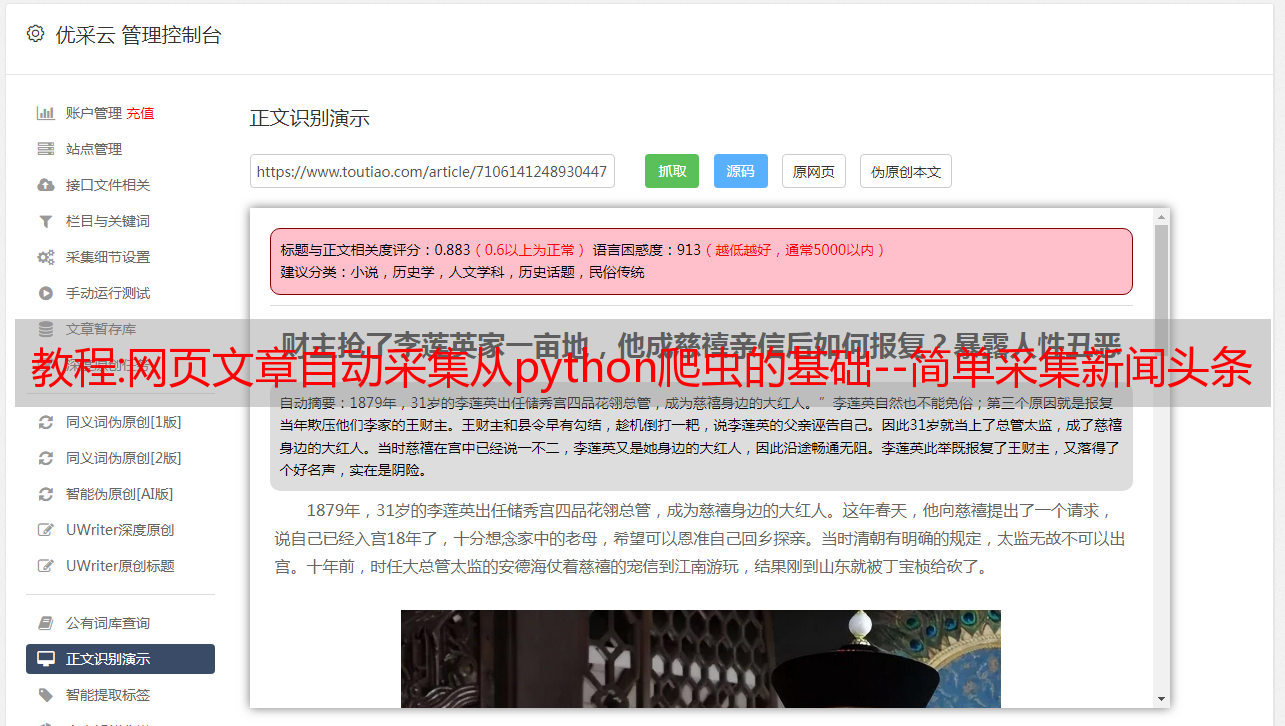
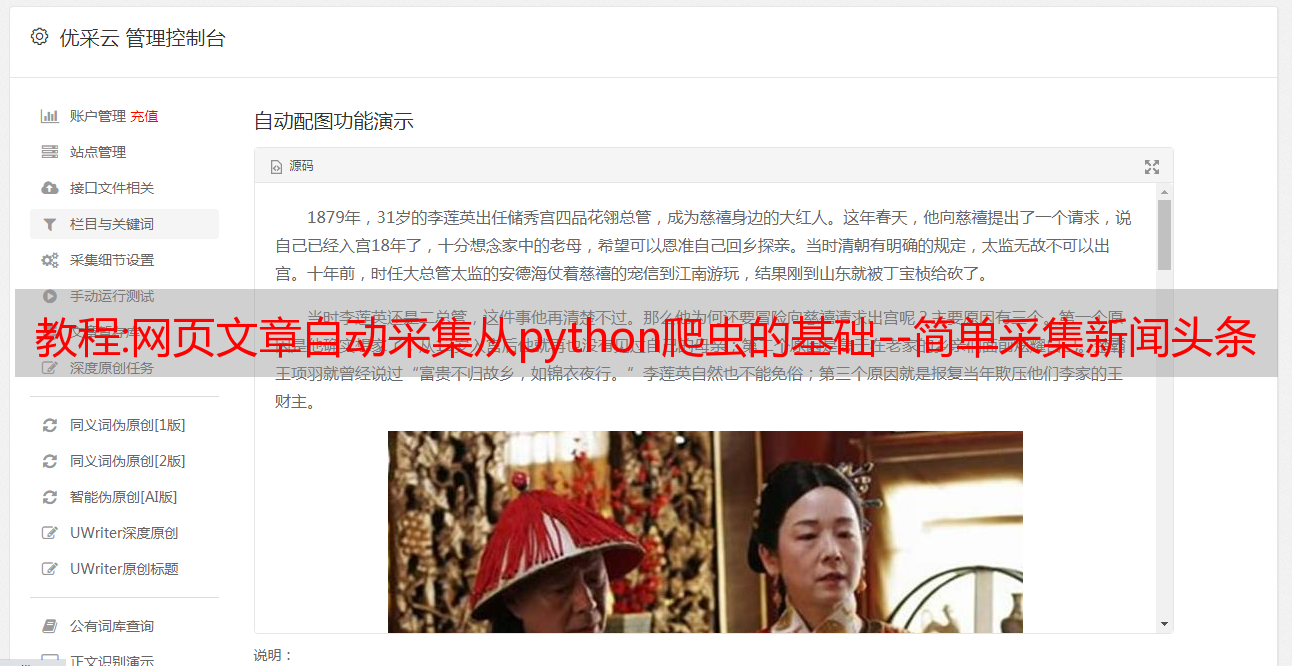
网页文章自动采集,从python爬虫的基础--简单采集新闻头条开始,介绍了文章解析、文章来源的分析、文章分析的关键函数、循环迭代的好处等常用方法。因为网页文章非常多,还没有爬到,后续的作业以及分析与爬虫都以此为主。scrapy爬虫scrapy已经非常流行,网络上关于其用法的文章也非常多,如果不是新手爬虫,阅读学习这些文章显然没有意义,但有可能会用到,或者有需要获取某些数据,这些文章就是不错的学习资料。
scrapy的resource设置文件使用class语言,mode="response"来设置和不同的消息类型对应的参数。比如我想爬取“人名”在相关tags里的相关文章,只需设置response_mode="response_mode",在spider中的生命周期,我们还可以设置动作类型(如:正则、模式匹配)。
那么items.py中的函数是否能直接执行呢?理论上是可以的,但我们安装了scrapyspider,items.py的函数也是需要先编译的,这就降低了解析速度,更多的时候爬虫任务来不及编译,所以还是要先将之编译。爬虫文章的源代码如下,请指教。pipinstallscrapy注意,这个模块有不同的版本,最新的版本是3.2.2版本,然后又增加了一些函数,最新的python版本3.3.1版本能够直接用,请阅读官方教程或学习我的其他爬虫教程。

