超级seo外链工具 干货分享:2019年清迈SEO大会笔记(Day 1)
优采云 发布时间: 2022-10-04 22:10超级seo外链工具 干货分享:2019年清迈SEO大会笔记(Day 1)
嗨,我的名字是约翰。
连续第三年参加清迈SEO大会(回顾和合的报告),印象非常深刻。
只有开过行业会议的人才明白,举办行业会议有多难。今年,虽然只用了半天时间,但前后花了我两个多月的时间。再加上*敏*感*词*损失(接近六位数),成本之高可想而知。. 不过,也没有遗憾,毕竟还有很多无形的价值。
Matt Diggity连续三年举办清迈SEO大会,汇聚了来自五大洲的英语SEO从业者。确实不容易!
今天是大会正式开始的第一天。观众满了,应该有几百人。
一个做得非常好的细节是会议日程,直接印在吊牌的背面。什么时候和谁说话一目了然,完全不用担心丢失。
回到主题,你参加任何会议都有两个目的:学习+交流。
所以,我就简单分享一下今天的一些学习笔记和感悟,然后快速聊聊社交(偷懒,录个视频)。
学习笔记
今天共有7个演讲。为了大家更好的理解,我按照SEO的组成部分把笔记分成了四个部分。
PS以下分享的内容和观点属于作者本人,我只是呈现给大家,不一定认同。
想要幻灯片的PPS读者,后天会议结束后,我会整理到Google Drive上,分享给大家。日记总结,哈哈。
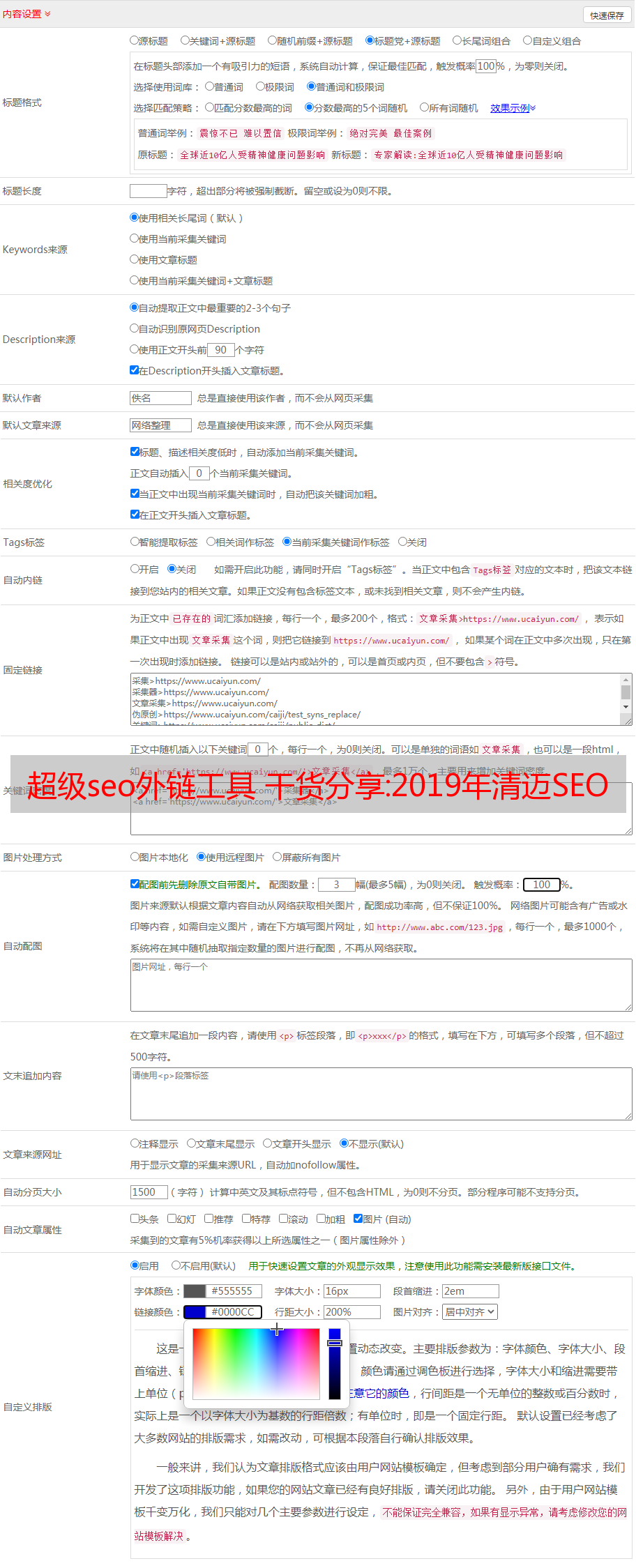
一、内容
Kyle Roof 发表了题为“Google's Algorithm is an Algorithm”(谷歌的算法是一种算法)的演讲,他首先抛出了“谷歌无法阅读”(Google doesn't read like a human)的结论,实验证实了这一点。
实验的大概过程是:他参与了“清迈隆鼻”(清迈鼻部*敏*感*词*)关键词的排名,一页满是乱码(包干),排名第一.
怎么做?他首先分析了本学期的前三个竞争页面,并总结了一些特点,例如:关键词 出现在哪里?多少次重复?什么是语义相关的词?几张图?多少个字符等等。
然后,他将所有这些功能应用到那个乱码网页上,提交给 Google收录,然后等待,最后它真的排名了,太棒了!
这就是为什么关联搜索引擎优化在过去两年非常流行的原因。一些工具,例如:Surfer SEO、Coral、Page Optimizer Pro 在市场上非常流行。
顺便说一下,Page Optimizer Pro 是 Kyle Roof 的产品。
Kyle Roof 演讲的后半部分谈到了反向孤岛(reverse topic classification)的重要性,大致意思是:
我们需要将网站的页面按照不同的主题(silo)进行分类,做关键词研究,在页面上找到一级关键词、二级关键词并进行优化,然后,通过配套页面有序的内部链接目标页面,最终提升目标页面主次关键词的排名表现。
结论是:谷歌的算法=计数+筒仓
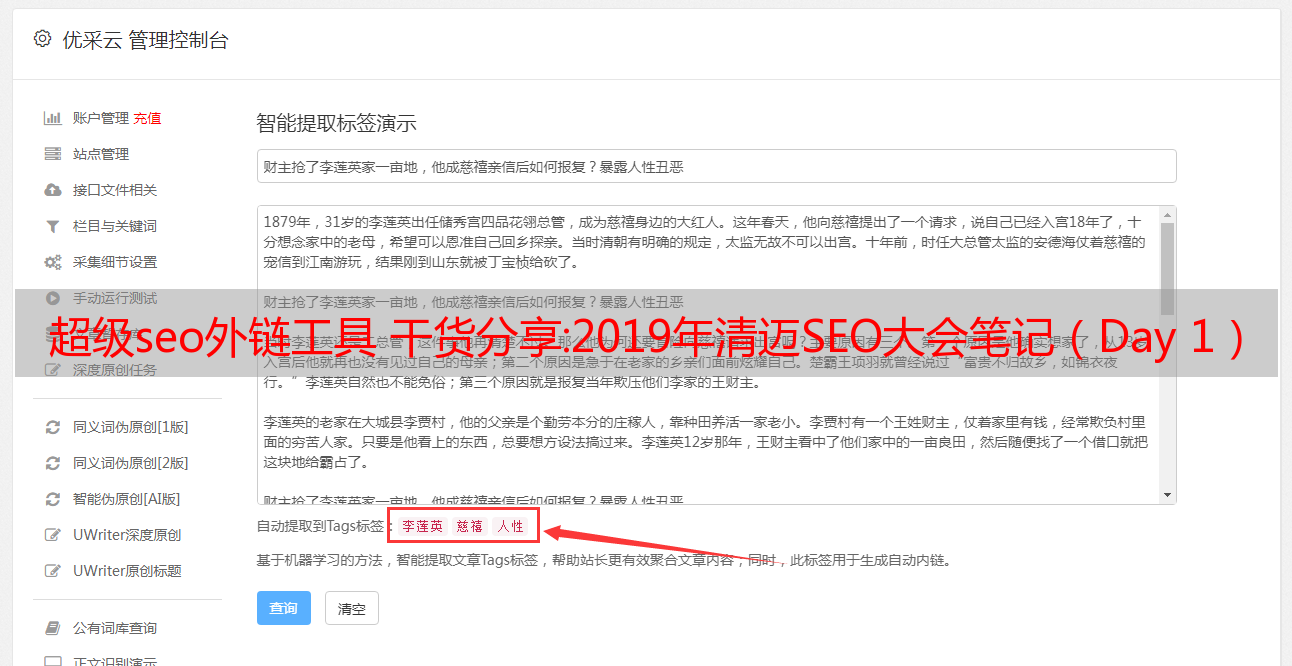
注:Kyle 提到的算法是针对网站的优化,而不是针对外链或技术的优化。
最后,通过测试,他也得出了链接权重通过的结论。
午休时间,Empire Flipper 的营销总监 Greg Elfrink 做了一个小分享“内容网站的数百万美元的终结游戏”。时间虽短,但干货不少。
(与在中国的AuthorityHacker学生一起)
2.链接建设
外链有两场演讲,嘉宾均来自英国。
第一个是Stacey MacNaught,第二个是业内知名的Charles Floate。
Stacey 分享了 Outreach Journalists/Bloggers 在过去几年的一些经验,并总结了一些结论和趋势,例如:
越来越多的 SEO 通过电子邮件“骚扰”记者,导致大多数记者讨厌我们;
要钱的博主越来越多,这使得外展的成本(时间+金钱)越来越贵;
但是,机会还是存在的,就看你是否有足够的创造力;
你真的了解记者吗,他们喜欢什么宣传,什么时候发送,快速回复和其他小细节很重要。
媒体资源和记者就这么少,SEO人越来越多,能不能拿到媒体的特色就看你的能力了。
另外,了解pitch object的心理很重要,Stacey提到了两点:
提示:外展时一定要查清对方的名字,否则会被记者或博主秒删。
最后,Stacey 提到了一种非常新颖的外部链接获取技术:运行 Google 广告来宣传您的可链接资产!并且分摊了花费的成本,似乎还不错。
Charles Floate 在业内享有“黑帽 SEO 之王”的美誉,但他的演讲《What I Learned Spending A Million Dollar on Backlinks A Year》并没有那么阴暗,更多的是关于花钱买外链 ROI 的情况后。
查尔斯非常聪明,喜欢把钱花在边缘(刀片是可以产生巨大回报率的地方)。
例如:谷歌无暇顾及的多语种市场!
、google.co.uk等英文搜索由数千万谷歌员工维护,你很难伺机而动。在北欧、越南等多语种地区,一般只有少数谷歌员工需要维护,所以“漏洞自然很多”。
他的观点:你可以任意搭建多种语言的外链网站,几乎任何外链搭建策略都不会受到谷歌的惩罚。
谷歌更看重高权威还是高相关性?
查尔斯毫不犹豫地提到了前者,他列举了各种证据表明,许多细分市场的 SERP 的首页都被媒体牢牢占据。
并且他提到高权重网站反向链接比高相关反向链接具有更高的价值,但是你最好同时拥有两种类型的反向链接,并注意获取反向链接的速度以及锚点文字通知。
PS Charles Floate 的产品是 DFY Links。为了在我们中国地区推广,他们的团队还设计了这样一件T恤,喜欢!
3.技术搜索引擎优化
Barry Adams的演讲《技术SEO成功秘诀》非常幽默,也源于他多年客户网站优化所产生的超强信心,他的客户包括(英国每日邮报)、技术SEO案例数不胜数。
巴里首先普及了谷歌搜索引擎的运行机制(三步):
并提到:更重要的网址被爬得更频繁(重要的页面爬得更快),而重要的页面一般是首页可以一键到达的页面。
然后,他展示了 1998 年谷歌两位创始人在斯坦福大学发表的论文,并询问谁读过这篇论文。我看了一下,好像不超过10个(哈哈,哼,我会在网上见你线下有分享,记住)
这篇论文就是PageRank(Page's Law)的原型!
Barry在处理客户网站技术SEO问题时,总是按照以上三个步骤进行分类,然后一一解决。
例如:rel="cononical"、hreflang、301重定向、页面加载速度、结构化数据等。
他大胆攻击谷歌:Google AMP Can Go Hell(谷歌的AMP可以退役,没用!)
并呼吁我们 SEO 的人不要使用 Chrome 浏览器(他自己使用 FireFox),因为 Google 会采集我们的使用数据(不要将数据免费提供给搜索引擎)。
例如:谷歌通过chrome数据测量页面加载速度(页面加载速度),而不是我们常用的页面速度测试工具。
Barry 推荐的技术 SEO 审计工具是:
4. 团队管理
Jonathan Kiekbush 是第二次在清迈 SEO 大会上发言(你可以回顾一下)。与往年一样,“沉睡的巨人战略”主题也与管理有关。
内容要点如下:
建立标准操作程序 (SOP)
创造移情文化
更有启发性,更适合Digital Agency经理细看。我不会在这里冗长。这都是商学院的东西,带有一些创新的网络工作应用程序。
PS Jonathan 是 SEOButler 的创始人。
社会接触
今晚写不下去了,给大家录个视频吧,哈哈。
明天继续写!
干货教程:分享一篇采集知乎问题和回答的文章
采集场景
知乎首页,输入关键字搜索得到相关问题列表。然后,点击问题链接进入详情页面,采集问题下的多个答案数据。
采集字段
问题名称、问题描述、评论数量、问题网站答案ID、答案ID描述、答案ID头像、答案正文等字段。
将鼠标放在图像上,右键单击,然后选择在新选项卡中打开图像以查看高分辨率大图
下面的其他图片也是如此
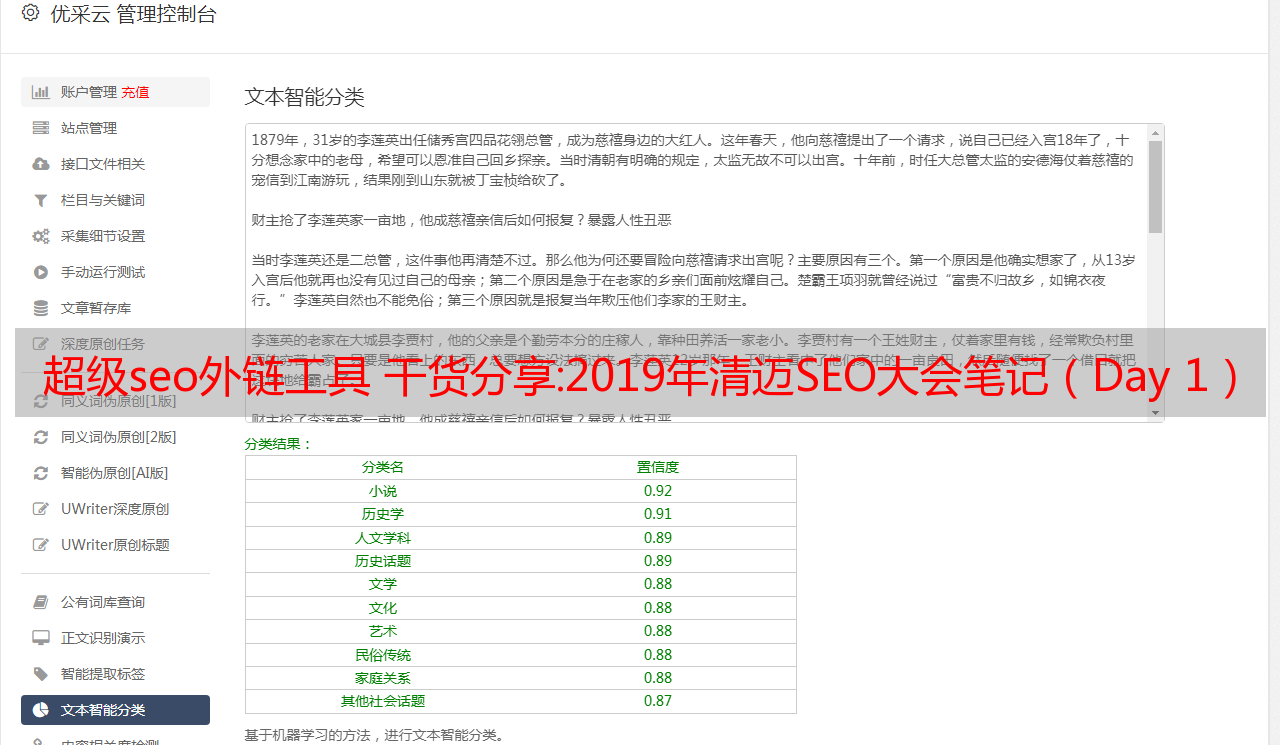
采集结果
可以导出采集结果Excel、CSV、HTML、数据库等多种格式。Excel 示例:
采集步骤
第一步:打开网页
第二步,使用cookies登录知乎
Step 3. 批量输入多个关键词
第 4 步:向下滚动页面以加载更多问题列表
第五步,建立循环——点击元素,进入每个问题的详细页面
第 6 步:提取与问题相关的字段
第七步。展开所有答案,滚动以加载更多答案
第 8 步:建立一个循环列表以从所有答案列表中采集数据
第九步,开始采集
具体步骤如下:
第一步是打开网站
在首页的【输入框】输入目标网址,点击【开始采集】,八达通会自动打开网页。
特别说明:
一个。打开网页后,如果自动识别启动,请点击不自动识别或取消识别关闭。因为这篇文章不适合自动识别。
湾。【自动识别】适用于网页自动识别列表、滚动和翻页。识别成功后,可以直接启动采集获取数据。点击查看自动识别教程
第二步,使用cookies登录知乎
采集知乎数据,首先需要登录。如果不先登录,就无法搜索关键词,采集搜索后得到的issue数据。因此,我们需要按照以下步骤登录八达通:
1.打开浏览器模式
点击
按钮打开浏览器模式。输入您的帐户密码并登录到浏览器模式。
2.使用cookies登录知乎
进入打开网页设置界面 1、查看指定cookie的使用情况],点击获取当前页面cookie]并保存。这样,登录后获取cookie,启动时直接以登录状态打开网页。
特别说明:
一个。什么是浏览器模式?在浏览器模式下,我们可以在不生成流程步骤的情况下点击操作页面。如果您需要编辑流程步骤,您需要关闭浏览器模式。
湾。什么是饼干?一般来说,cookie是存储在用户电脑上的一个小文件,用来保存一些网站用户数据,其作用是让浏览器为用户定制内容。比如用户第一次访问网站,输入账号密码登录,浏览器会询问是否需要记住账号密码。选择“是”后,浏览器会将这些帐户密码信息存储在用户的计算机上。下次您访问此网站 时,您将无需再次输入您的帐户密码。点击查看需要登录的页面(包括登录时的验证码)
C。如何判断是否获取cookie?拿到饼干后
第三步:批量输入多个关键词
批量输入多个关键字 输入多个关键字。
1.创建文本列表循环
2.创建输入文本并与文本列表循环链接,输入多个关键字
3. 点击搜索
4.创建文本列表循环
在打开网页步骤之后,添加一个循环。
进入循环设置页面。选择如何循环浏览文本列表
按钮,输入我们准备好的关键字(可以同时输入多个关键字,一行一行),然后保存。
特别说明:
一个。示例中输入的关键字是大数据和机器学习,可以根据自己的需要进行替换。
湾。一次最多输入 2W 个关键字。先准备一份收录多个关键词的文件,然后复制粘贴到八达通。
2.创建输入文本并与文本列表循环链接,输入多个关键字
① 创建输入文本
关闭浏览器模式,选择页面上的搜索框,在*敏*感*词*动作提示框中选择输入文本,点击确定。
② 与文本列表的循环联动
将“输入文本”步骤拖到循环中。然后进入输入文本设置页面,勾选用当前循环中的文本填充输入框并保存。
3. 点击搜索
在循环中选择一个关键字,点击输入文本,可以看到该关键字成功输入到网页的文本框中。
然后选择搜索按钮,点击操作提示框中的单击此按钮,出现关键字搜索结果列表页面。
第 4 步:向下滚动页面以加载更多问题列表
点击搜索按钮后,向下滚动页面以加载更多问题列表并滚动浏览章鱼。
进入【点击元素】设置页面,点击【页面加载】,设置【页面加载后向下滚动】,滚动方式为【直接滚动到底部】,滚动次数为2次,间隔为1秒并保存。
特别说明:
一个。请根据采集和页面加载的要求在设置中设置滚动次数和时间间隔,而不是静态的。请点击查看处理滚动加载数据的网络教程
第五步,建立循环——点击元素,进入每个问题的详细页面
1.创建一个【循环-点击元素,进入每个问题的详细页面
循环浏览每个问题链接以进入问题详细信息页面:
① 选择页面第一个问题链接(注意问题链接)
② 在*敏*感*词*操作提示框中点击全选
③ 点击循环点击各个链接进入第一题的详情页面
特别说明:
一个。继续以上连续三个步骤,循环-点击元素】完成创建。[圆圈]中的项目对应页面上的所有问题链接。启动采集后,优采云会在循环中按顺序点击每个问题链接,进入问题详情页面,使用采集每个问题下的答案数据。
湾。为什么上面三个步骤可以建立一个循环——点击元素?单击查看详细信息集并单击多个链接后的详细信息页面数据教程。
2.修改【循环点击元素】Xpath
为了准确定位所有问题链接,需要修改循环单击元素 XPath。
特别说明:
一个。搜索关键词后,搜索结果有多种数据:主题、栏目、Lives、eBooks、文章、问题。本文仅采集问题数据,不考虑其他类别。
湾。默认生成的循环方式为固定元素列表循环,无法准确定位所有问题链接。您需要手动修改 XPath 以将其定位为所有问题链接。这里需要一些 XPath 知识。点击查看 XPath 学习与实践教程。
第 6 步:提取与问题相关的字段
1.展开问题描述,提取问题名称和问题描述
如果问题描述太长,会被折叠。选择Show All按钮,在弹出的动作提示框中选择Click this element,展开所有问题描述。
如果您不需要 采集 问题描述,请跳过此步骤。
2.提取问题名称并描述问题
选择页面上的文本,然后单击操作工具提示中的采集元素文本。
可以像这样提取文本字段。例如,我们提取问题名称、问题描述等字段。
特别说明:
一个。文字、图片、视频和源代码是不同的数据形式,在操作提示框中选择的提取方式略有不同。文本通常是集合元素文本,图像通常是集合图像的地址。请点击查看不同的数据类型(文本、图片、链接、源代码等)。
3.编辑字段
设置界面时,可以删除冗余字段、修改字段名称、移动字段顺序、添加字段等。
单击,选择 Add Current网站Info-Collect Links for Current Issues。
第七步。展开所有答案,滚动以加载更多答案
1. 展开答案
当一个问题的答案太多时,默认显示三个答案,其他答案将被折叠。选择查看所有信息 X 按钮,然后在操作提示框中,选择单击此链接以展开答案。
如果您不需要采集所有答案,则可以跳过此步骤。
2.滚动加载更多答案
单击查看全部 X 一个答案后,向下滚动页面将加载更多答案并在八达通中设置滚动。
进入【点击元素3】设置页面,不要勾选【在新标签中打开】,然后点击【页面加载】,设置【页面加载后向下滚动】,滚动方式为【直接滚动到底部,滚动次数】 , [每个时间间隔] 2秒,设置后保存。
特别说明:
一个。为什么不检查新标签?因为 View All Info X 按钮是检查新选项卡后的 Ajax 单击,所以 采集 会出现问题。请点击查看Ajax网页采集方法
湾。请根据采集的要求和页面的加载情况在设置中设置滚动次数和时间间隔,而不是静态的。请点击查看处理滚动加载数据的网络教程
第 8 步:建立一个循环列表以从所有答案列表中采集数据
1.创建循环列表
采集通过以下 3 个连续步骤从所有答案列表中获取数据:
① 选择页面上的答案列表(注意选择整个列表,包括所有必填字段)
② 选择页面上的第二个问题列表
③ 在*敏*感*词*的操作提示框中,选择采集以下元素文本
特别说明:
一个。继续上面三个连续的步骤,循环——创建并完成提取数据。循环中的项目对应于页面上的所有问题列表。但这会将整个列表提取为一个字段。如果您需要单独提取字段,请查看以下操作。
湾。为什么可以通过以上三个步骤建立一个循环——提取数据?点击查看详细列表数据采集教程。
C。【循环列表】默认只有5个问题列表。在八达通中滚动页面后,问题列表会增加。
2.从问题列表中提取字段
点击当前选中页面中的文本,采集action tooltip中的元素文本。
可以像这样提取文本字段。在示例中,我们提取了答案 ID、答案 ID 描述、答案 ID 多个字段,例如头像、答案正文等。
特别说明:
一个。文字、图片、视频和源代码是不同的数据形式,在操作提示框中选择的提取方式略有不同。文本通常是集合元素文本,图像通常是集合图像的地址。请点击查看不同的数据类型(文本、图片、链接、源代码等)。
3.编辑字段
设置页面时,可以删除冗余字段、修改字段名称、移动字段顺序等。
第九步,开始采集
1. 单击 [采集] 和 [启动本地 采集]。八达通开始自动采集数据。
特别说明:
一个。[本地采集]是使用自己的电脑采集,[云采集]是使用八达通提供的云服务器采集,点击查看本地采集和云采集详细说明。
2、采集完成后,选择合适的导出方式导出数据。支持导出Excel、CSV、HTML、数据库等,这里导出Excel。
原文链接:

