解读:【自研】东鸽用 Go 语言写了一个能够自动解析新闻网页的算法
优采云 发布时间: 2022-10-04 11:17解读:【自研】东鸽用 Go 语言写了一个能够自动解析新闻网页的算法
“夜班”,当之无愧的明星
的公众号。
输入网页文本(无需输入xpath),自动结构化输出标题、发表时间、正文、作者、来源等信息。
对于流量,标题有点虚张声势。但是,该算法确实可以在多个来源和多个站点中使用。已经在生产环境中应用,效果不错。
先体验一下
打开体验地址(或点击阅读下方原文)->体验页面[1],体验页面比较简单,主要分为3个区域:体验说明、参数输入区、分析结果展示区。
在开始体验之前,您可以阅读体验说明。
① 打开新闻页面,如永福:林业科技专员助力麻竹种植[2]。
② 然后在页面空白处右击,在弹出的选项卡中选择查看页面源代码。
然后我们看到浏览器新窗口中显示的网页原文
③ 选择所有文本并复制。查找 Base64 编码的在线工具 [3]
④ 将复制的网页原文粘贴到框1,然后点击加密按钮,框2会出现对应的Base64编码,点击复制按钮将内容复制到剪贴板
⑤ 回到我们的体验页面,将Base64内容粘贴到参数输入区的网页框中,在URL中填入这个文章对应的URL。
⑥ 点击开始分析按钮,稍等片刻,体验页面会弹出分析结果提示。然后可以滑动到下方的分析结果显示区查看分析结果。
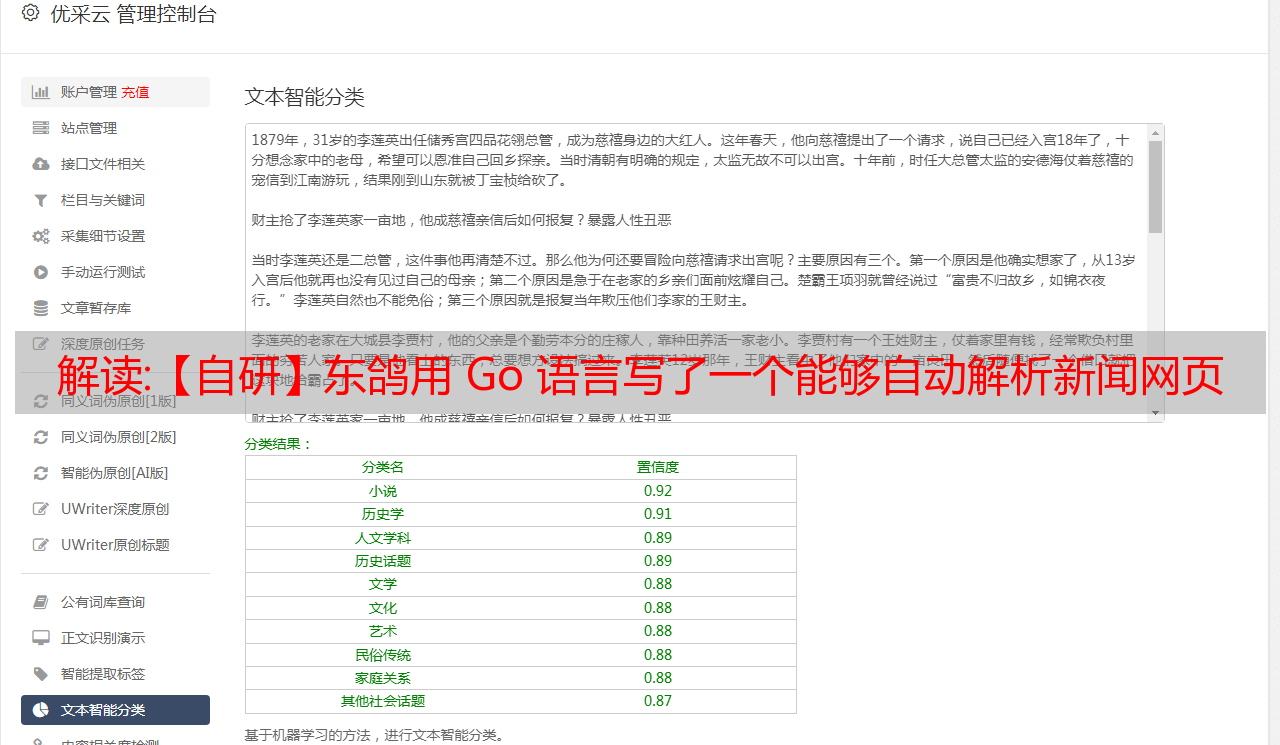
解析结果展示区主要分为界面信息、解析耗时统计、解析结果三部分。
接口信息主要是后端接口返回的一些信息;
分析耗时统计是每个环节的耗时记录,单位为毫秒;
该算法的结果会显示在解析结果中,如文章标题、文章出处、文章发表时间、文章作者、文章正文,文本所在的HTML标签,文本所在的HTML标签的Class属性等。
还有根据文本内容计算的文章分类、文章标签、文章摘要等。多实体命名+情感分析还在训练中,所以还没有体验页面。
建议你找一些其他的新闻页面,用同样的方法复制粘贴到体验页面,看看算法是怎么工作的。
这个算法有什么用
事实上,我们在工具应用中已经看到了这种算法:早年360浏览器推出的阅读模式几乎就是这样的算法。阅读模式可以屏蔽那些广告、侧边栏和底栏内容,让您专注于阅读文档和小说。
在研发层面,它也发挥着很大的作用。我们来看一些业务场景:
①假设一家舆情公司,它采集news文章data,经过提取内容、标注、训练,最终形成舆情产品(比如什么舆情,什么舆情波)。
②我们再举个栗子,假设一个投标公司,它采集投标信息,然后格式化内容提取投标标题、投标金额、投标人信息、代理信息,投标要求等,可以形成一个投标产品(例如千匹马投标)。
无论是新闻网站还是竞价信息网站,站点的数量非常多,通常在几万个。按照惯例,招聘一批爬虫工程师+一批写xpath规则的工作人员(通常是勤奋的实习生),从上万个站点中一个一个的填写xpath,等爬虫的时候去读采集 取对应的xpath进行解析。
几十、几百个网站,幸好这几万个站点的数据要填好几个月。另外,有些网站会有页面规则变化,导致无法解析数据,所以需要每天更新xpath。你想想工作量...
但是有了这样的算法,就不需要填写每个xpath了。
你的团队/公司可以采集在短时间内获得大量数据,你不开心
这个算法强大吗?
先不说强不强。让我们看看哪里有这样的算法或产品。
1、之前提到过360浏览器(现在是其他厂商的浏览器)有这样的产品。
2、微软似乎也有类似的能力,也开放了API接口。
3. Readability,国外开源Python库。
4.国内开源Python库GNE。
5、部分国内硕士研究论文(可在百度图书馆查询)。
6. 其他基于深度学习的库,名字记不住了。我记得微软工程师崔庆才写的。
7.有个国外的网站,名字忘记了,费用很贵。
8.有一个用Java写的外文版本,名字里有News,但是我忘记了。
现在大家体验的算法都是受GNE启发的。在GNE的早期,我通读了源码,与原作者进行了很多交流,询问了很多知识。后来在我写的《Python3网络爬虫合集》一书中,有一章介绍了GNE算法的原理和源码。再次感谢GNE作者青楠。
体验过浏览器的阅读模式,通过阅读源码阅读了Readability,也通读了国内能找到的相关论文。目前深度学习相关库和计费接口尚未测试。
这类自动解析算法的好坏在于几个点:效率、提取能力和准确性。以下是我接触过的几种算法的评估:
1. 可读性基于 HTML 标签的权重。比如p标签的权重高于div,h的权重高于span。在很标准的新闻网站中,效果还可以,但是一般计算出来的结果都离谱。
2、GNE早期,GNE早期是基于标点密度的,90%以上的网页解析都没有问题。但是在实际应用中发现了几个问题:内容会被截断,正文少的会被错误识别,发布时间和页面显示不一样。与文本提取相关的问题都是由密度算法引起的。由于提取优先级和逻辑选择了另一种方式,因此时序不规则。
3.国内论文,因为看不懂国外论文,只能搜索国内论文。一般来说,基于文字密度、标点密度、位置、距离等,效果其实不是很好。在这里你可能会问,为什么论文的结果这么好?
那是因为测试样品选择得很好!!!
4. GNE-modern,GNE-modern是基于人类视觉+新闻网页特征规则的。一般的逻辑是网页的内容通常在网页的中间,这样可以消除左右上下的噪音。中间的噪声通过块的长度来判断,最后可以提取出非常准确的文本。
技术细节不能泄露太多,我举个例子。上图中的蓝色块是放置图片的位置。从 GNE-Modern 的角度来看,它会认为蓝色块的宽度和下面文字的宽度不同,所以这个块会是噪声,应该排除。
先不说那些需要大量样本训练的深度学习算法,毕竟我自己没有体验过。但有一点是肯定的,仅仅基于分类和回归的深度学习是不可能取得好的效果的。不知道bert模型出来后有没有人训练出更好的模型。
对比总结:上面列举的例子中,GNE-Modern的body part提取是最好的,但是我记得是需要浏览器渲染的,从效率上看好像还没有找到好的解决方案。
本文中的算法,大家可以体验一下,毕竟实际体验可以证明好不好。我觉得这篇文章的算法目前可以按照效率+准确率+提取能力来排名(这是一个很谦虚的词)。
放上群友提供的哔哩哔哩专栏的分析效果。
算法的逻辑是什么
不好意思,我现在不打算讨论这个问题,也不是开源的时候,下一个。
引用了哪些算法
前面说过,我读过Readability和GNE-early的源码,国内也读过大部分相关论文。
一开始我是基于GNE的早期优化和改造。
看了很多深度学习相关资料,最后决定不走这条路线,因为结果发现效果并没有达到我想要的效果。
突然有一天,我在看《天上九歌》的那一集选了那一集,得到了灵感。经过短暂的编码,我测试了一下,发现结果是可行的,于是我就一头扎进去了。这条领带是20年...
错误的
是 200 天
哪些区域可以横向缩放
现在主要用于新闻数据分析,可以扩展到招标网页分析、电子商务网页分析、药品网页分析等。
如果从深度学习的角度来看,它们可能需要不同的训练、不同的样本和不同的算法模型。但是从我的算法原理来看,它们都是一样的,适当的改动,就可以得到另一个领域的解析算法。
参考
[1] 体验页面:3597/
[2]永福:林业科技专员助力麻竹种植:
[3] 在线工具:
推荐文章:撰写高质量伪原创文章的技巧有哪些
在内容为王的互联网时代,网站的管理员首先更新了自己的网站内容,很多SEOer都被自己的原创文章惹恼了,毕竟他们已经是肚子里的墨水和自己的视线都是有限的。写了半年,感觉没什么可写的。大多数人将注意力转向伪原创文章。那么我们怎样才能写好伪原创文章呢?
OK伪原创=更改数字+替换同义词+按顺序随机播放段落+开始和结束段落原创?
传统的伪原创是这样的,把“谷歌,百度”改成“百度,谷歌”,“五技”改成“三技”等等。任何这样的修改都是初级的,修改后的伪原创 文章 的常识和信息比 原创文章 少。普通人看了两篇文章的文章,一眼就能看出他们在说同一个东西,谁是盗版谁是原创一目了然。过去,蜘蛛可以上当,但现在随着深度学习算法的兴起,而百度一直在计划依靠人工智能作为下一个起飞点,这样的伪原创技能很容易被识破。
如何写出好的伪原创?
我的建议是先学习,好像你对某个行业已经很熟悉了。在这个行业中编写 伪原创文章 很容易。如果你写了很多关于这个行业的伪原创文章,并且你写了你所知道的一切,当你没有什么可写的时候,试着看看其他人写了什么,阅读多一些,总结一下自己的概念,总结一下自己的概念,然后插入自己的观点和附加的方法或者自己知道的常识等等,一个高质量的伪原创文章就出来了。
如果你不是很了解这个行业,需要在短时间内将文章发布到特定的网站,那么我建议你尝试搜索几个该行业的具体开头词to find what you want 你想写的文章的标题,缩小搜索范围后,看4-10篇与你想写的想法和内容相关的文章,记得阅读每篇文章文章 仔细,并在最后关闭这些页面。开始你自己的写作,用你自己的话表达你的常识。“读一百遍书是自找的”,“一千个人的眼里有一千个哈姆雷特”,你写的都是高质量的伪原创。

