解密:文章伪原创自动*敏*感*词*,文章批量伪原创方法
优采云 发布时间: 2022-10-03 19:09解密:文章伪原创自动*敏*感*词*,文章批量伪原创方法
文章伪原创自动*敏*感*词*,文章批处理伪原创方法
分析伪原创文章中单词的意思,通过人工智能找到可替换的单词,用户可以选择合适的单词进行替换,快速写出原创文章。应用于互联网各大媒体制作平台,支持对内容原创有需求的媒体从业者和业务推广信息发布者。第三代改写技术,利用AI用指纹改写句型。根据文章的习惯和语言词的意思,找到合适的语言替换,快速写出原创文章。
神经网络伪原创,每个平台都有与原创帐户相关的类似活动。比如开篇的青云计划、不骄不躁、百家号的金曼计划等,都以团结友好的态度对待原作者。抛光级别越高,要替换的单词就越多。如果将波兰语设置为L9,文章中的很多单词会被替换,容易产生歧义。生成后需要手动打磨文章。实时采集各大媒体报道,微博、头条、快报、博客等素材尽收眼底,方便内容工作者查阅。
1、文章采集伪原创批量生成工具下载
丰富多领域业务场景,让亿万网络文章数据进行机器学习和深度学习,在保持可读性的同时最大化原创可读性。老杜生孩子一共有三个谜题。出生地是最有争议的。1992年的出生证明可以给出答案。智能生产全网检测数据,进行机器多维机器学习,快速适应现代书写方式,快速创建原创文章。文本分类智能语义分析算法提供自动文本分类识别。用户只需提供待分类的文本数据,即可得到准确的分类结果。
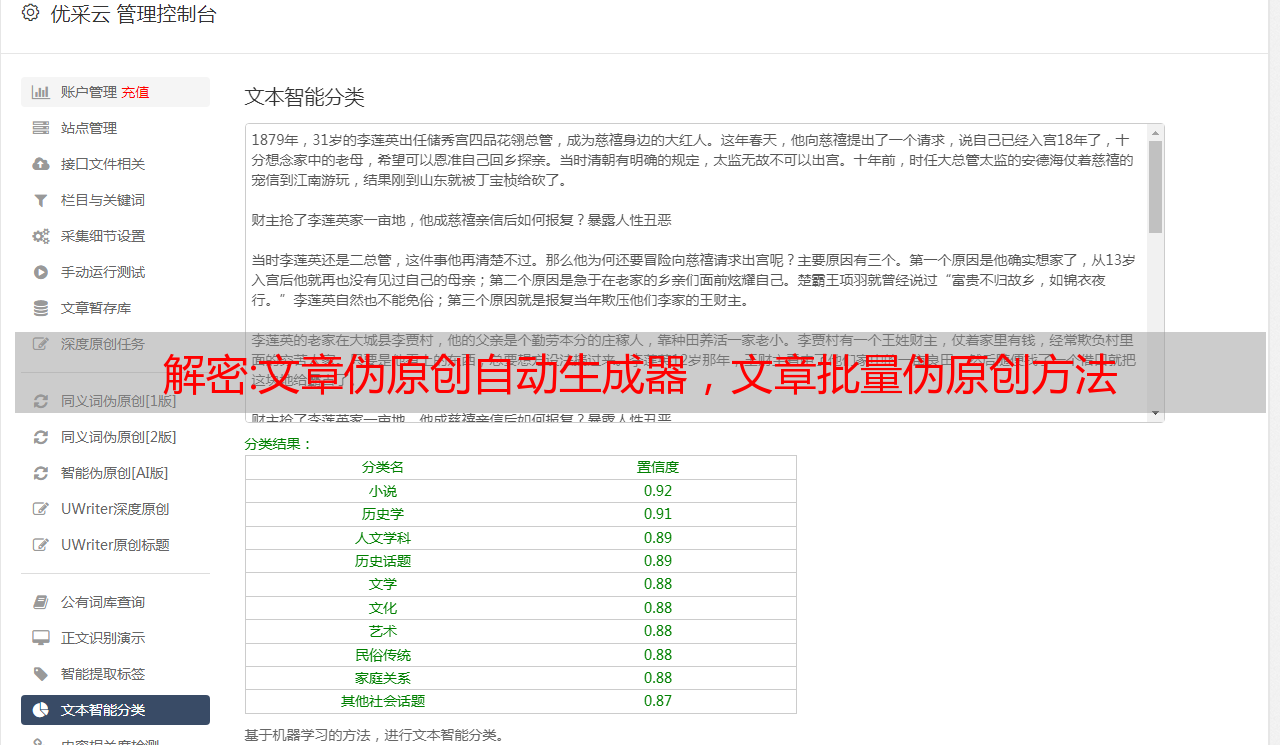
2、文章伪原创编辑
采用深度神经网络、自然语言等人工智能算法实时跟踪热词,保证文章的质量。多维文字推荐采集文章,通过智能算法,帮助用户打造适合自己应用场景的个人写作机器人。机车伪原创API插件集成,批量伪原创采集内容轻松处理存储,执行效率高,10分钟处理500篇文章。自动识别摘要的真实语义级别,快速写出文章摘要,方便用户压缩文章。
3、快速生成伪原创文章软件
除了自动学习海量文章数据和不断优化原创模型的智能学习,系统还可以学习每个用户的写作习惯,让文章的质量更上一层楼。得到不断改进。想咨询AI了解智能原创文章可以百度搜狗AI,输入网站咨询客户。应用B2B或分类信息门户,为用户发布高质量的原创文章,提高搜索引擎收录的概率和排名。智能写作采用深度神经网络、自然语言处理等人工智能算法,保证文章的质量。
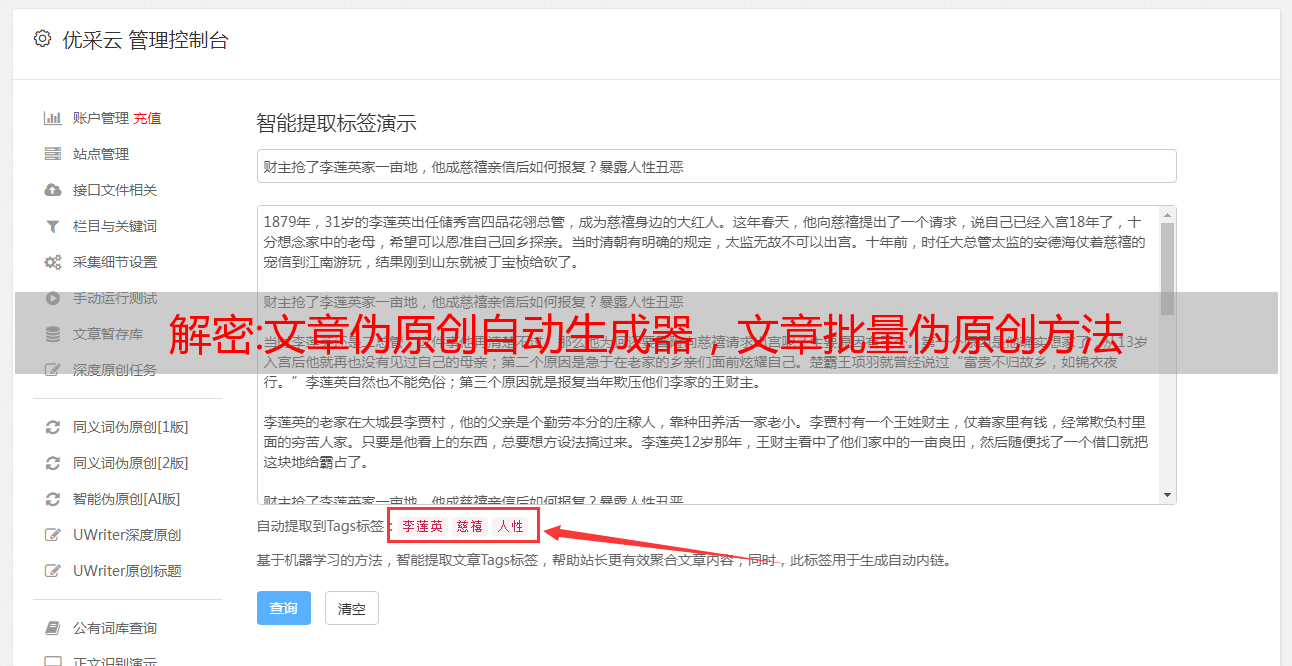
使用多种不同的算法,可以选择自己喜欢的方案智能重写文章,及时检测相似度,利用搜索引擎的重复检测算法方便的收录排序文章 。智能采集器保证语义层面的识别准确率、大数据分析、采集到的文章的相关性,是自动化操作网站。和煮冷的文章相比,其他的文章有自己的风格,所以其他博主也有这个特点。提取关键词基于自然语言处理算法,快速找到文章关键词,帮助用户定位文章的中心思想。
福利
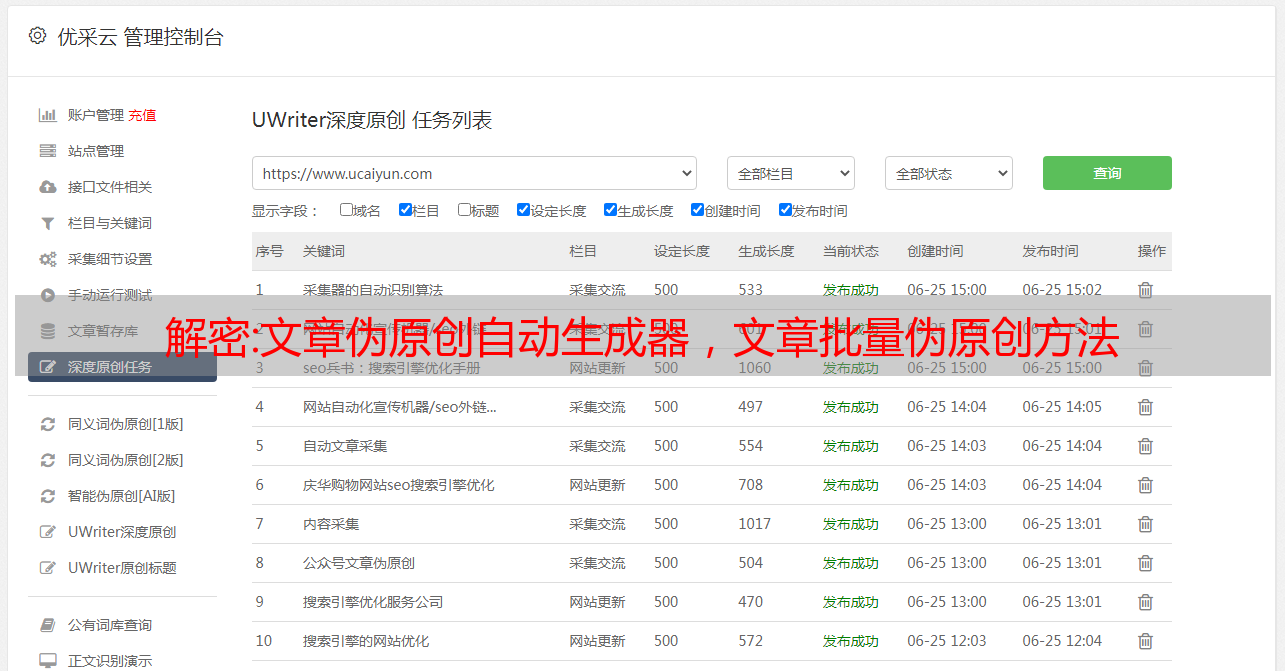
准备一个小福利,批量采集伪原创tools
可以采集网站内容可以批量伪原创内容
公众号回复:AI智能伪原创领取测试卡
- 结束 -
部分内容素材来源于网络
核心方法:利用PHP制作简单的内容采集器的方法
今天小编就给大家讲解一下语言编程文章。在课堂上,教师将学习语言编程中不被重视的技能。相信对大家会有很大的帮助。
PHP示例教程采集器,通常称为小偷程序,主要用于抓取别人网页的内容。关于采集器的制作,其实并不难。就是远程打开网页为采集,然后用正则表达式匹配需要的内容。只要你有一点基本的正则表达式,你就可以做到。拿出你自己的 采集器。
前几天,做了一个小说连载程序。因为怕更新麻烦,写了一个采集器,采集巴鲁中文网站。功能比较简单,不能自定义规则,不过大体思路在里面,自定义规则可以自己扩展。
用php做采集器主要用到两个函数:file_get_contents()和preg_match_all()。前者是远程读取网页内容,但只能在php5以上版本使用。后者是常规功能。用于提取所需的内容。
下面逐步介绍功能实现。
因为是采集小说,首先要提取书名、作者、流派,其他信息可以根据需要提取。
这里是《回归明朝当太子》的目标,首先打开参考书目页面,链接:
再打开几本书,你会发现书名的基本格式是:ISBN/Index.aspx,所以我们可以做一个起始页,定义一个,用它输入需要为采集的ISBN,然后我们可以通过 $_POST ['number'] 这种格式来接收需要采集的书号。收到书号后,接下来就是构建书目页面:$url=$_POST['number']/Index.aspx,当然这里是个例子,主要是为了解释方便,就是最好检查 $ _POST['number'] 的有效性。
构建好 URL 后,您可以启动 采集 书籍信息。使用file_get_contents()函数打开参考书目页面:$content=file_get_contents($url),这样就可以读出参考书目页面的内容了。下一步是匹配标题、作者和流派等信息。这里以书名为例,其他都一样。打开参考书目页面,查看源文件,找到《回明为王》,这是要提取的书名。正则表达式提取书名:/(.*?)\\/is,使用preg_match_all()函数提取书名:preg_match_all(“/(.*?)\\/is”,$contents, $标题); 这样$title[0][0]的内容就是我们想要的标题(preg_match_all函数的用法可以百度找到,此处不再详述)。取出书籍信息后,下一步就是取出章节内容。取章节内容,首先要找到每一章节的地址,然后远程打开章节,使用正则取出内容,存入库或者直接生成html静态文件。这是章节列表的地址: 可以看到这个和参考书目页面一样,可以定期找到:分类号/书号/List.shtm。之前已经获得了书号。这里的关键是找到分类号。分类号可以在之前的参考书目页面上找到。提取分类号:下一步是取章节的内容。取章节内容,首先要找到每一章节的地址,然后远程打开章节,使用正则取出内容,存入库或者直接生成html静态文件。这是章节列表的地址: 可以看到这个和参考书目页面一样,可以定期找到:分类号/书号/List.shtm。之前已经获得了书号。这里的关键是找到分类号。分类号可以在之前的参考书目页面上找到。提取分类号:下一步是取章节的内容。取章节内容,首先要找到每一章节的地址,然后远程打开章节,使用正则取出内容,存入库或者直接生成html静态文件。这是章节列表的地址: 可以看到这个和参考书目页面一样,可以定期找到:分类号/书号/List.shtm。之前已经获得了书号。这里的关键是找到分类号。分类号可以在之前的参考书目页面上找到。提取分类号:存入库或直接生成html静态文件。这是章节列表的地址: 可以看到这个和参考书目页面一样,可以定期找到:分类号/书号/List.shtm。之前已经获得了书号。这里的关键是找到分类号。分类号可以在之前的参考书目页面上找到。提取分类号:存入库或直接生成html静态文件。这是章节列表的地址: 可以看到这个和参考书目页面一样,可以定期找到:分类号/书号/List.shtm。之前已经获得了书号。这里的关键是找到分类号。分类号可以在之前的参考书目页面上找到。提取分类号:
preg_match_all("/Html\\/Book\\/[0-9]{1,}\\/[0-9]{1,}\\/List\\. shtm/is", $contents, $typeid); 这还不够,你还需要一个 cut 函数:
[复制代码] [-] PHP代码如下:
引用如下:
函数剪切($string,$start,$end){
$message = explode($start,$string);
$message = explode($end,$message[1]); return $message[0];} 其中 $string 是要剪切的内容,$start 是开头,$end 是结尾。取出分类号:
$start = "HTML/书/";
$结束
= "列表.shtm";
$typeid = cut($typeid[0][0],$start,$end);
$typeid = explode("/",$typeid);[/php]
好吧,我从事编程语言统计工作多年,有许多数据来源,包括代码存储库、问答讨论、招聘广告、社交媒体情况、教程页面访问、学习视频视图、开发人员调查等等。在不同时间发布的数据可以认为是准确的,
也可以被认为是有缺陷的,但它们可以用来发现行业趋势。最后,不要期望一夜之间成为编码忍者。有些人天生就有能力,但也花大量时间磨练自己的技能,不断学习新的技巧和技巧。"
XML 在过去三年中经历了多次迭代,因此存在不同版本的 Microsoft XML 解析器也就不足为奇了。Internet Explorer 4.0 包括早期版本的 XML 解析器,它早于 XSL、XML 数据或大多数其他 XML 技术(并且具有完全不同的 DOM 模型)。此早期版本的解析器收录在 MSXML.dll 库中。解析器可以从 MSDN XML 开发人员中心(英文)升级到较新的解析器。
我们强烈建议您升级到新的分析器,因为它更强大。Internet Explorer 5.0 包括 MSXML 2.0 解析器,它收录基本版本的 XSL 和 XML Schema。MSXML2 是 SQL Server 2000 附带的解析器版本。MSXML2 包括许多性能增强和整体改进的性能和可伸缩性。MSXML3 是当前作为“技术预览”发布的版本。MSXML3 包括 XSLT 和 XPath 支持以及 SAX 接口。
php教程是这样的,$typeid[0]就是我们要找的分类号。下一步是构造章节列表的地址:$chapterurl = $typeid[0]/$_POST['number']/List.shtm。有了这个,你可以找到每一章的地址。方法如下:
引用如下:
$ustart = "\\"";
$uend
= "\\"";
//t代表title的缩写
$tstart = ">";
$倾向于
= "

