秘密武器:日志收集神器 Logstash,闪亮登场~
优采云 发布时间: 2022-10-03 16:14秘密武器:日志收集神器 Logstash,闪亮登场~
配置 Filebeat 以将日志行发送到 Logstash
在创建 Logstash 管道之前,您需要配置 Filebeat 以将日志行发送到 Logstash。Filebeat 客户端是一个轻量级、资源友好的工具,它从您的服务器上的文件中采集日志并将这些日志转发到您的 Logstash 实例进行处理。Filebeat 专为可靠性和低延迟而设计。Filebeat 在宿主机上消耗的资源非常少,Beats 输入插件会尽量减少对 Logstash 实例的资源需求。
(画外音:请注意,在典型的用例中,Filebeat 和 Logstash 实例是分开的,运行在不同的机器上。在本教程中,Logstash 和 Filebeat 运行在同一台机器上。)
第 1 步:配置 filebeat.yml
filebeat.inputs:<br />- type: log<br /> paths:<br /> - /usr/local/programs/logstash/logstash-tutorial.log<br /><br />output.logstash:<br /> hosts: ["localhost:5044"]<br />
第二步:在logstash安装目录下新建文件first-pipeline.conf
(画外音:我刚才说了Logstash的管理通常分为三个部分(输入、过滤、输出)。这里,下面beats { port => "5044" }的输入表示使用Beats输入插件,和 stdout { codec => rubydebug } 表示输出到控制台)
第 3 步:检查配置并启动 Logstash
bin/logstash -f first-pipeline.conf --config.test_and_exit<br />
(画外音:--config.test_and_exit 选项表示解析配置文件并报告任何错误)
bin/logstash -f first-pipeline.conf --config.reload.automatic<br />
(画外音:--config.reload.automatic 选项的意思是开启自动配置加载,这样就不需要每次修改配置文件时都停止重启Logstash)
第 4 步:启动文件节拍
./filebeat -e -c filebeat.yml -d "publish"<br />
如果一切顺利,您将在 Logstash 控制台中看到与此类似的输出:
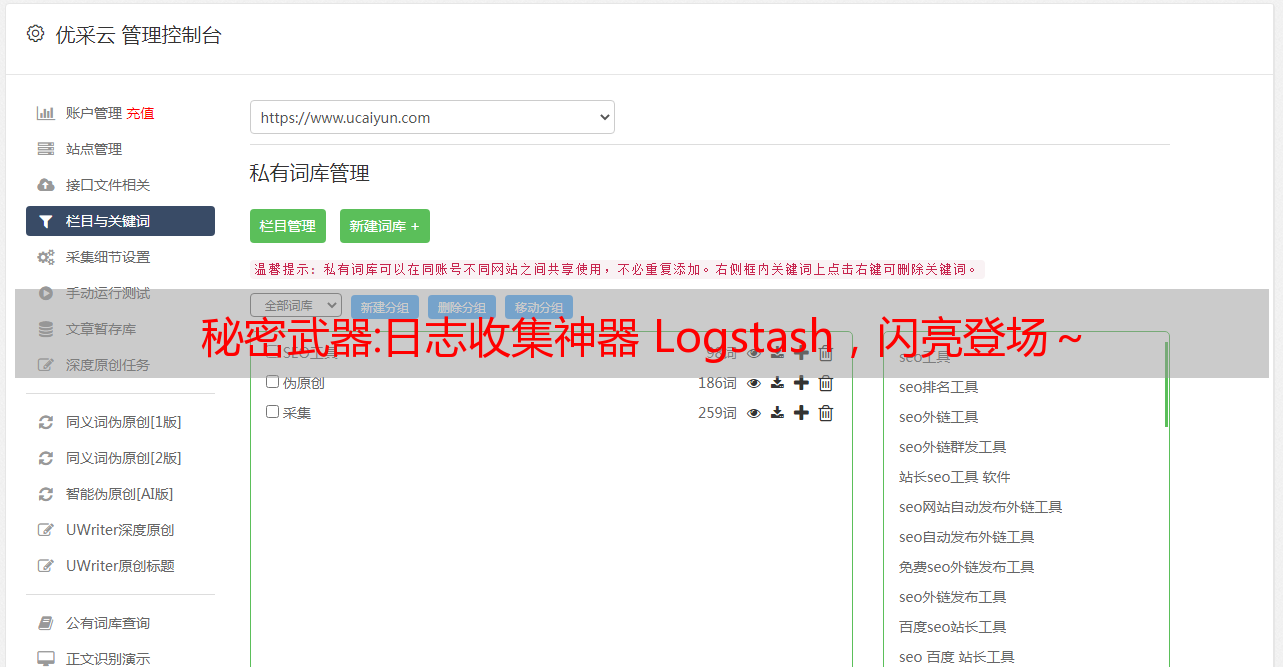
使用 Grok 过滤器插件解析日志
现在您有了一个可以从 Filebeat 读取日志行的工作管道。但是您可能已经注意到日志消息的格式并不理想。您想要解析日志消息以从日志中创建特定的命名字段。为此,您将使用 grok 过滤器插件。
grok 过滤器插件是 Logstash 中默认可用的几个插件之一。
grok 过滤器插件允许您将非结构化日志数据解析为结构化和可查询的数据。
因为 grok 过滤器插件在传入的日志数据中寻找模式
为了解析数据,您可以使用 %{COMBINEDAPACHELOG} grok 模式,该模式(或格式)的架构如下:
接下来,编辑 first-pipeline.conf 文件并添加 grok 过滤器。进行更改后,文件应如下所示:
保存后,您无需重新启动 Logstash 即可应用更改,因为您已启用自动加载配置。但是,您确实需要强制 Filebeat 从头开始读取日志文件。为此,您需要在终端中按 Ctrl+C 停止 Filebeat,然后删除 Filebeat 注册文件。例如:
rm data/registr<br />
然后重启 Filebeat
./filebeat -e -c filebeat.yml -d "publish"<br />
此时,再次查看 Logstash 控制台,输出可能如下所示:
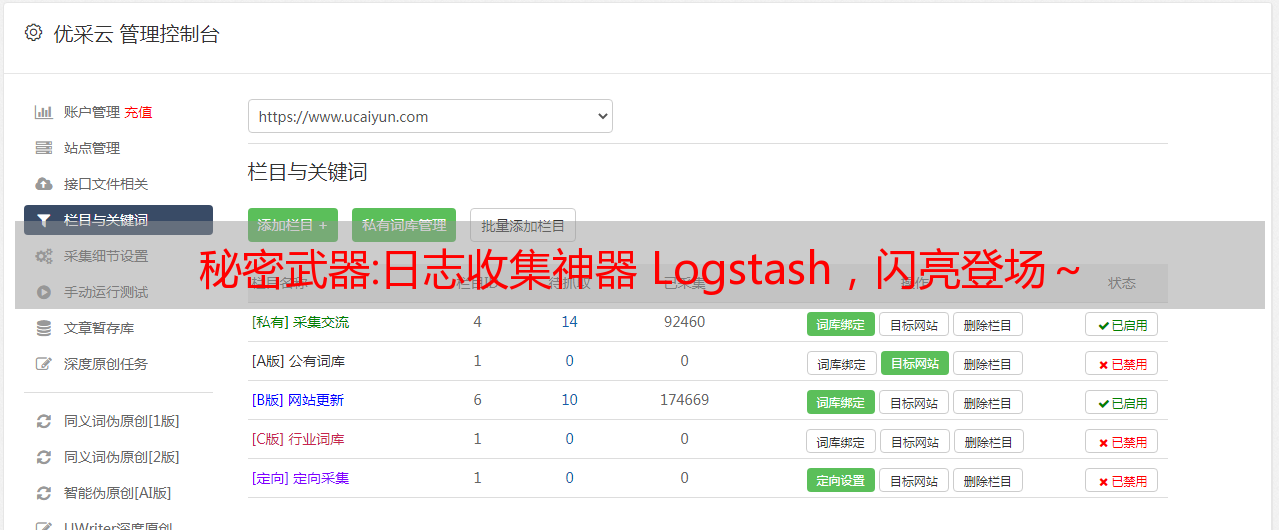
使用 Geoip 过滤器插件增强您的数据
然后,同样地,重新启动 Filebeat
Ctrl+C<br /><br />rm data/registry<br /><br />./filebeat -e -c filebeat.yml -d "publish"<br />
再次查看 Logstash 控制台,我们会发现更多的地理信息:
将您的数据索引到 Elasticsearch
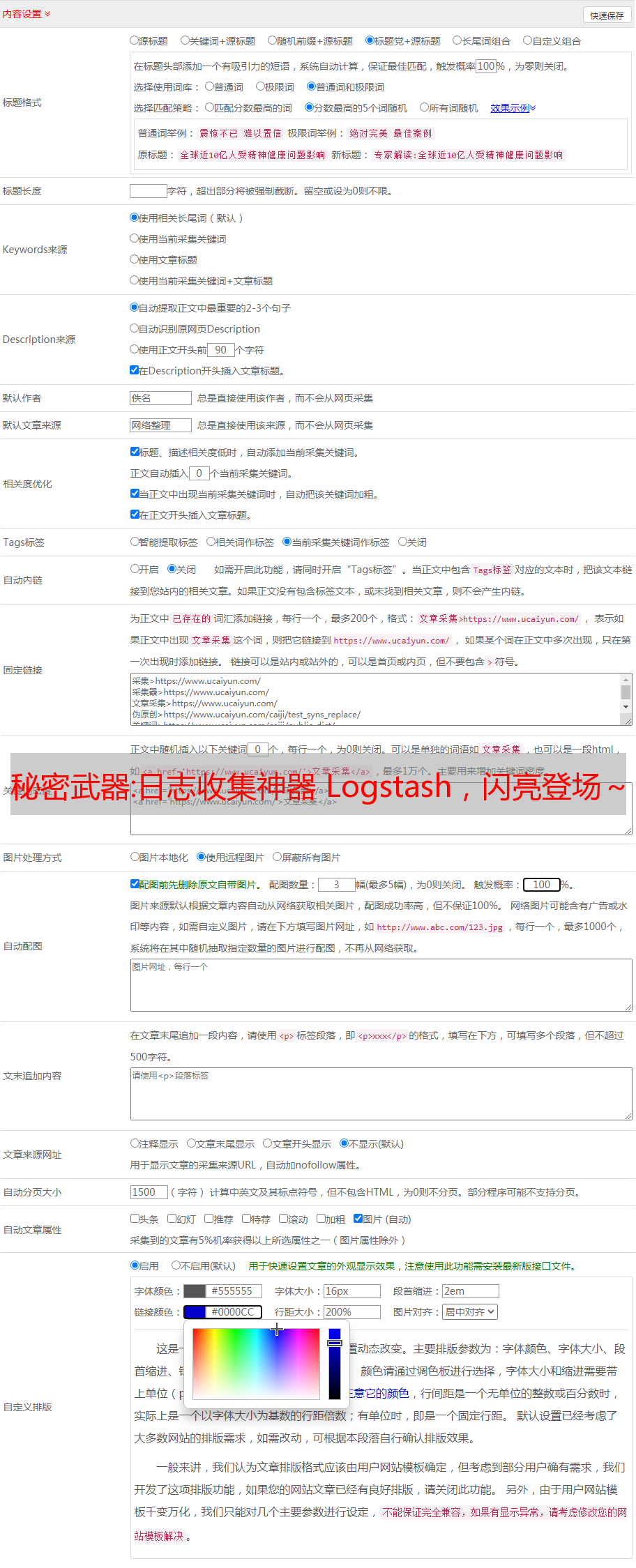
在之前的配置中,我们将 Logstash 配置为输出到控制台,现在我们将其输出到 Elasticsearch 集群。另外,关注公众号的Java技术栈,后台回复:面试,可以获得我整理的Java系列面试问答。
编辑 first-pipeline.conf 文件并将输出区域替换为:
output {<br /> elasticsearch {<br /> hosts => [ "localhost:9200" ]<br /> }<br />}<br />
在此配置中,Logstash 使用 http 协议连接到 Elasticsearch,并假设 Logstash 和 Elasticsearch 允许在同一台机器上。您还可以指定一个远程 Elasticsearch 实例,例如 host=>["es-machine:9092"]
现在,first-pipeline.conf 文件如下所示:
再次,保存更改后,重新启动 Filebeat
(画外音:首先Ctrl+C终止Filebeat;然后rm data/registry删除注册文件;最后./filebeat -e -c filebeat.yml -d "publish" 启动Filebeat)
好了,接下来启动 Elasticsearch
(画外音:检查Elasticsearch索引,如果看不到logstash索引,重启Filebeat和Logstash,重启后应该可以看到)
如果一切顺利,您可以在 Elasticsearch 的控制台日志中看到如下输出:
[2018-08-11T17:35:27,871][INFO ][o.e.c.m.MetaDataIndexTemplateService] [Px524Ts] adding template [logstash] for index patterns [logstash-*]<br />[2018-08-11T17:46:13,311][INFO ][o.e.c.m.MetaDataCreateIndexService] [Px524Ts] [logstash-2018.08.11] creating index, cause [auto(bulk api)], templates [logstash], shards [5]/[1], mappings [_default_]<br />[2018-08-11T17:46:13,549][INFO ][o.e.c.m.MetaDataMappingService] [Px524Ts] [logstash-2018.08.11/pzcVdNxSSjGzaaM9Ib_G_w] create_mapping [doc]<br />[2018-08-11T17:46:13,722][INFO ][o.e.c.m.MetaDataMappingService] [Px524Ts] [logstash-2018.08.11/pzcVdNxSSjGzaaM9Ib_G_w] update_mapping [doc]<br />
这时候我们再看一下Elasticsearch的索引
问:
curl 'localhost:9200/_cat/indices?v'<br />
回复:
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size<br />yellow open bank 59jD3B4FR8iifWWjrdMzUg 5 1 1000 0 475.1kb 475.1kb<br />green open .kibana DzGTSDo9SHSHcNH6rxYHHA 1 0 153 23 216.8kb 216.8kb<br />yellow open filebeat-6.3.2-2018.08.08 otgYPvsgR3Ot-2GDcw_Upg 3 1 255 0 63.7kb 63.7kb<br />yellow open customer DoM-O7QmRk-6f3Iuls7X6Q 5 1 1 0 4.5kb 4.5kb<br />yellow open logstash-2018.08.11 pzcVdNxSSjGzaaM9Ib_G_w 5 1 100 0 251.8kb 251.8kb<br />
可以看到有一个名为“logstash-2018.08.11”的索引,其他索引都是之前创建的,不用管
接下来看一下这个索引下的文档
问:
curl -X GET 'localhost:9200/logstash-2018.08.11/_search?pretty&q=response=200'<br />
响应如下所示:
(画外音:由于输出太长,这里截取部分)
{<br /> "_index" : "logstash-2018.08.11",<br /> "_type" : "doc",<br /> "_id" : "D_JhKGUBOuOlYJNtDfwl",<br /> "_score" : 0.070617564,<br /> "_source" : {<br /> "host" : {<br /> "name" : "localhost.localdomain"<br /> },<br /> "httpversion" : "1.1",<br /> "ident" : "-",<br /> "message" : "83.149.9.216 - - [04/Jan/2015:05:13:42 +0000] \"GET /presentations/logstash-monitorama-2013/images/kibana-search.png HTTP/1.1\" 200 203023 \"http://semicomplete.com/presentations/logstash-monitorama-2013/\" \"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.77 Safari/537.36\"",<br /> "auth" : "-",<br /> "timestamp" : "04/Jan/2015:05:13:42 +0000",<br /> "input" : {<br /> "type" : "log"<br /> },<br /> "geoip" : {<br /> "postal_code" : "101194",<br /> "region_name" : "Moscow",<br /> "timezone" : "Europe/Moscow",<br /> "continent_code" : "EU",<br /> "city_name" : "Moscow",<br /> "country_code3" : "RU",<br /> "country_name" : "Russia",<br /> "ip" : "83.149.9.216",<br /> "country_code2" : "RU",<br /> "region_code" : "MOW",<br /> "latitude" : 55.7485,<br /> "longitude" : 37.6184,<br /> "location" : {<br /> "lon" : 37.6184,<br /> "lat" : 55.7485<br /> }<br /> },<br /> "@timestamp" : "2018-08-11T09:46:10.209Z",<br /> "offset" : 0,<br /> "tags" : [<br /> "beats_input_codec_plain_applied"<br /> ],<br /> "beat" : {<br /> "version" : "6.3.2",<br /> "hostname" : "localhost.localdomain",<br /> "name" : "localhost.localdomain"<br /> },<br /> "clientip" : "83.149.9.216",<br /> "@version" : "1",<br /> "verb" : "GET",<br /> "request" : "/presentations/logstash-monitorama-2013/images/kibana-search.png",<br /> "prospector" : {<br /> "type" : "log"<br /> },<br /> "referrer" : "\"http://semicomplete.com/presentations/logstash-monitorama-2013/\"",<br /> "response" : "200",<br /> "bytes" : "203023",<br /> "source" : "/usr/local/programs/logstash/logstash-tutorial.log",<br /> "agent" : "\"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.77 Safari/537.36\""<br /> }<br /> }<br />
另一个
问:
curl -XGET 'localhost:9200/logstash-2018.08.11/_search?pretty&q=geoip.city_name=Buffalo'<br />
回复:
{<br /> "took" : 37,<br /> "timed_out" : false,<br /> "_shards" : {<br /> "total" : 5,<br /> "successful" : 5,<br /> "skipped" : 0,<br /> "failed" : 0<br /> },<br /> "hits" : {<br /> "total" : 2,<br /> "max_score" : 2.6855774,<br /> "hits" : [<br /> {<br /> "_index" : "logstash-2018.08.11",<br /> "_type" : "doc",<br /> "_id" : "DvJhKGUBOuOlYJNtDPw7",<br /> "_score" : 2.6855774,<br /> "_source" : {<br /> "host" : {<br /> "name" : "localhost.localdomain"<br /> },<br /> "httpversion" : "1.1",<br /> "ident" : "-",<br /> "message" : "198.46.149.143 - - [04/Jan/2015:05:29:13 +0000] \"GET /blog/geekery/solving-good-or-bad-problems.html?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+semicomplete%2Fmain+%28semicomplete.com+-+Jordan+Sissel%29 HTTP/1.1\" 200 10756 \"-\" \"Tiny Tiny RSS/1.11 (http://tt-rss.org/)\"",<br /> "auth" : "-",<br /> "timestamp" : "04/Jan/2015:05:29:13 +0000",<br /> "input" : {<br /> "type" : "log"<br /> },<br /> "geoip" : {<br /> "postal_code" : "14202",<br /> "region_name" : "New York",<br /> "timezone" : "America/New_York",<br /> "continent_code" : "NA",<br /> "city_name" : "Buffalo",<br /> "country_code3" : "US",<br /> "country_name" : "United States",<br /> "ip" : "198.46.149.143",<br /> "dma_code" : 514,<br /> "country_code2" : "US",<br /> "region_code" : "NY",<br /> "latitude" : 42.8864,<br /> "longitude" : -78.8781,<br /> "location" : {<br /> "lon" : -78.8781,<br /> "lat" : 42.8864<br /> }<br /> },<br /> "@timestamp" : "2018-08-11T09:46:10.254Z",<br /> "offset" : 22795,<br /> "tags" : [<br /> "beats_input_codec_plain_applied"<br /> ],<br /> "beat" : {<br /> "version" : "6.3.2",<br /> "hostname" : "localhost.localdomain",<br /> "name" : "localhost.localdomain"<br /> },<br /> "clientip" : "198.46.149.143",<br /> "@version" : "1",<br /> "verb" : "GET",<br /> "request" : "/blog/geekery/solving-good-or-bad-problems.html?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+semicomplete%2Fmain+%28semicomplete.com+-+Jordan+Sissel%29",<br /> "prospector" : {<br /> "type" : "log"<br /> },<br /> "referrer" : "\"-\"",<br /> "response" : "200",<br /> "bytes" : "10756",<br /> "source" : "/usr/local/programs/logstash/logstash-tutorial.log",<br /> "agent" : "\"Tiny Tiny RSS/1.11 (http://tt-rss.org/)\""<br /> }<br /> },<br />。。。<br />
从命令行启动 Logstash
要从命令行启动 Logstash,请使用以下命令:
bin/logstash [options]<br />
以下示例显示使用 mypipeline.conf 文件中定义的配置启动 Logstash:
bin/logstash -f mypipeline.conf<br />
命令行上设置的任何标志都会覆盖 logstash.yml 中的相应设置。但是文件本身的内容并没有改变。
命令行标志
--node.name 名称
指定 Logstash 实例的名称。如果未指定,则默认为当前主机名。
-f, --path.config CONFIG_PATH
从指定的文件或目录加载 Logstash 配置。如果给定目录,则该目录中的所有文件将按字典顺序连接,然后解析为一个配置文件。
-e, --config.string CONFIG_STRING
使用给定的字符串作为配置数据,语法与配置文件中的相同。
--模块
运行模块名称
-l, --path.logs 路径
Logstash 内部日志输出目录
--log.level 级别
日志级别
-t,--config.test_and_exit
检查配置语法是否正确并退出
-r, --config.reload.automatic
监视配置文件的更改,并在配置文件被修改时自动重新加载。
-config.reload.interval RELOAD_INTERVAL
多久拉一次配置文件以检查配置文件是否已更改。默认值为 3 秒。
事实:自动爬取?三种工具让数据搜集超容易 | 数据新闻工具之二
编者注
“数据新闻”是一种全新的新闻报道形式,从数据中挖掘线索,以可视化的方式呈现故事,其核心是对数据的处理。有效使用数据分析技术和可视化软件是我们提高数据新闻生产能力的重要一步。
《数据新闻报道软件工具及应用》旨在提高新闻专业学生和媒体从业人员在数据新闻领域的制作技能。介绍了数据新闻的*敏*感*词*法,并提供了详细的案例练习,指导读者学习技术工具。
在上一篇文章中,我们介绍了如何使用 Python、Node.js 和 R 通过自主编程来爬取数据。对于没有代码库的数据记者来说,工具化的爬虫应用程序“data采集器”是一个不错的选择。
01
工具 1:优采云
介绍
优采云大数据采集平台集成了网页数据采集、移动互联网数据和API接口服务等功能,无需编写代码即可快速满足用户的基础数据爬取需求。
官方网站:
主要功能
优采云采集器主要有两种数据采集模式:模板采集、自定义采集。
优采云中有上百个网站的采集模板,覆盖了主流网站的采集场景。自定义采集模式适用于所有网站,用户可以根据自己的需要进行配置,包括智能识别和手动配置采集流程两种模式。
案例实践
本书针对采集的上述两种模式——模板采集和自定义采集。以采集豆瓣电影Top250为例,简单、清晰、详细地讲解了相关步骤和原理,为直接操作打下了良好的基础。有关详细信息,请参阅数据新闻软件工具和应用程序的第 23-33 页。
02
工具 2:GooSeeker
介绍
GooSeeker 是一款采集 软件,根据网页的语义标注和结构变换,对网页信息和数据进行爬取。
官方网站:
主要功能
GooSeeker的功能主要集中在客户端和官网网站。
Jisouke GooSeeker客户端是一个浏览器布局,被命名为“爬虫浏览器”。内置MS号和DS号功能,用户可以通过视觉点击轻松采集目标数据,确定采集规则等内容。
除了提供对应客户端的下载功能外,GooSeeker官方网站还提供了一系列辅助功能。例如可以在网站的资源栏下载配置的任务采集规则;在大数据论坛发表使用心得或遇到的困难。
案例实践
本书以豆瓣电影250强榜单为例,在数据采集的时间和地点详细讲解了客户端的步骤和操作原理;不仅如此,官方还对网站提供的一系列辅助功能进行了说明。有关详细信息,请参阅数据新闻软件工具和应用程序,第 36-48 页。
03
工具 3:优采云采集器
介绍
优采云采集器是一个网页采集软件,可以在数据自动化过程中同步清洗数据采集,保证采集数据更准确有效.
官方 网站 网址:
主要功能
优采云采集器主要有两种采集模式:智能模式采集和流程图模式采集。
智能模式主要是为没有编程基础的用户开发的,其功能可以类比之前推送中提到的优采云custom采集模式的智能识别功能。不同的是,软件的智能模式可以根据需要下载图片、音频、视频等内容。
流程图模式是一种满足用户丰富个性化数据需求的操作模式采集。通过点击可视化网页,自定义采集流程,满足用户更加个性化、精准化的需求。
案例实践
本书以国家统计局公布的2010-2019年我国行政区划数据为例,详细讲解了智能模式和流程图模式的数据采集步骤,并“启动-up settings”为软件界面的所有功能和功能中的每一项设置都解释清楚,并开通绿色通道,直接动手操作。有关详细信息,请参阅数据新闻软件工具和应用程序,第 49-62 页。
以上所有内容都可以在“数据新闻软件工具和应用程序”中找到
购书链接:

