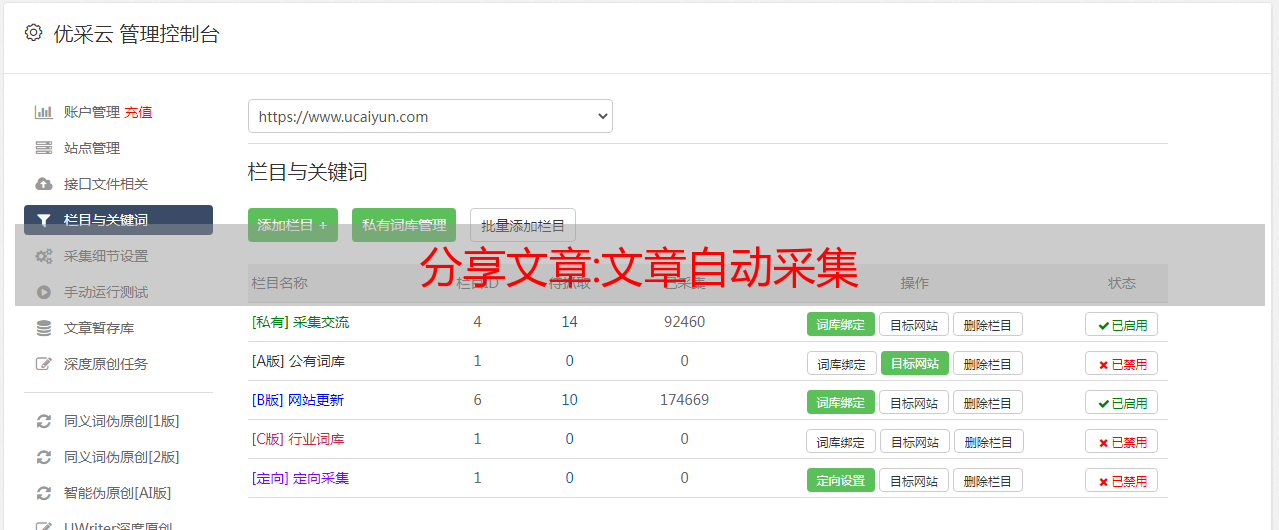
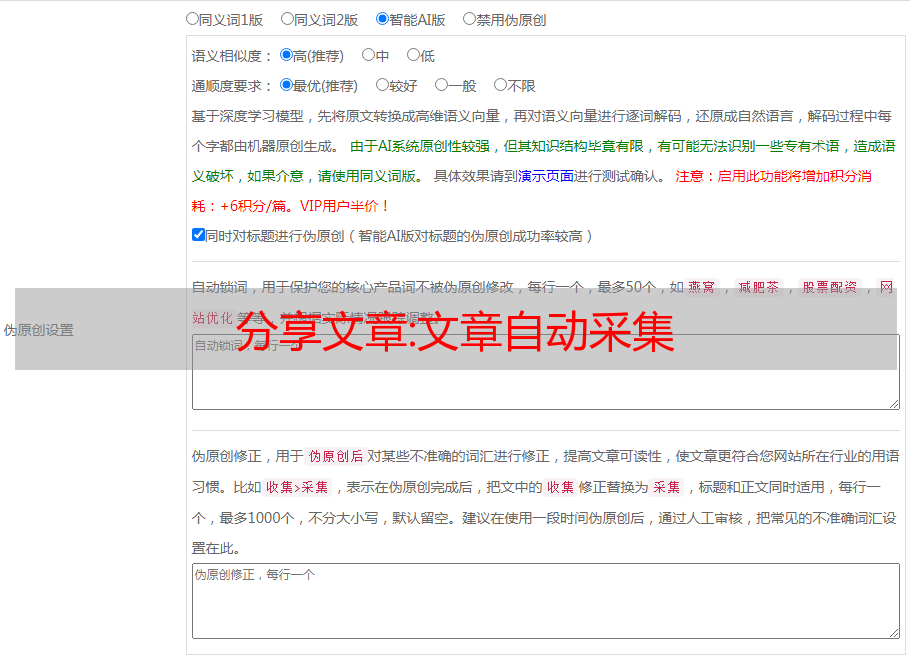
分享文章:文章自动采集
优采云 发布时间: 2022-10-03 11:37分享文章:文章自动采集
文章自动采集爬取拉勾网,以下是爬取前后的反爬虫对比,欢迎大家补充~欢迎大家留言补充。本篇主要介绍了被采集网站的反爬虫,顺便提供一个自动化的反爬虫工具::爬虫总结1.模拟登录,获取授权和解析url(按钮等模拟行为)2.爬取数据,
两个可能是同一个人
老子的一片荒芜的小树林算不算
反爬机制其实也是自动化的过程。每个网站的反爬机制都不一样。真的要自动化,做好规划。首先大方向是熟悉网站结构,这里特指大型网站。你要清楚这个网站是什么结构,用的什么技术实现的。然后针对每个实现的技术,都有对应的容易识别的特征,以及,怎么避免爬虫。尽可能地提高自动化效率,可以参考豆瓣爬虫的实现,大概说就是,尽可能的提取信息特征,以及用log转换等手段来降低爬虫请求。
豆瓣的应该很有代表*敏*感*词*
请参考豆瓣爬虫——真正的自动化之路!
首先,你要确定你的输入来源是否能对应到存在这个对应值,否则,无解。反正,无解!反正,再如此便捷,我还是觉得手动找存在那个值比较有趣。
真的很有吸引力哦
豆瓣首页搜索,搜索框你值得拥有
信息搜索一直在做,涉及多个领域,单说html->http协议、缓存等。细数搜索这个领域吧。文字搜索,电影歌曲分类,影视音乐检索。曲库检索,播放页面关键字匹配,等等,太多了,前段时间准备自己写一套来实现一些新的功能。当然,现在暂时没有实现。

