逆天:黑帽seo快速排名(单页seo快速排名)
优采云 发布时间: 2022-10-02 18:15逆天:黑帽seo快速排名(单页seo快速排名)
新手如何使用WordPress 伪原创插件快速创建原创内容,快速获取网站收录和排名关键词?新手 SEO 应该怎么做?快速开始。
从新手到高手,坚持排名优化很重要。很多新手在做SEO的时候总是会陷入误区。其实他们心里是很想学seo的,但是因为不懂seo这个行业,所以走在新手的路上越来越难了。大多数新手在刚接触 seo 行业时总是不耐烦。经过几天的SEO,我开始不耐烦了。为什么它不起作用?然后他们去找各种seo老手。一般做seo的资深人士会耐心回答等等。这还早了一个月,但这是真的。这时,新手会开始感到迷茫和不知所措。那么,让我们来看看新手不擅长SEO的原因。
我不知道从哪里开始。
有很多新手对seo还是很感兴趣的,只是不知道从哪里开始,不知道怎么入手,也不知道怎么理解它的技术点。所以在这种情况下,我建议先百度一下,对seo这个行业有一个大概的了解,然后再学一些编程语言,就不用知道学编程语言有多难了。只要学过基本的HTML语言和PHP/ASP/JAVA等一些简单的编程语言,还必须学习数据分析,这是一个很重要的课题。网站 优化的质量取决于数据分析后定制执行方法的有效性。
在大部分学习者看来,所谓的SEO就是把想要的关键词优化到首页,但真正的SEO是搜索引擎优化,而不是搜索排名优化。正是因为排名被视为SEO的整体,所以没有人整天关心排名,导致很多人半途而废。总之,您对 SEO 的了解程度取决于您可以在 SEO 中走多远。
二、缺乏毅力
由于seo是一项长期有效的工作,所以大部分放弃seo的新手都是因为坚持不了。在做了几天没有效果之后,他们总是感到受到打击。但实际上,这不仅是新手如此,老手也是如此。所有从事seo多年的人都有耐心。如果你没有耐心,无论你多么熟练,你都无法完成这项工作。但不是没有优化一下子就能看到效果,但不是优化,是作弊。黑帽seo也可以在短时间内看到效果,但是想要在一个好的关键词排名中实现长期稳定,黑帽seo做不到,所以一定要坚持,否则不会能够去。新手的方法。
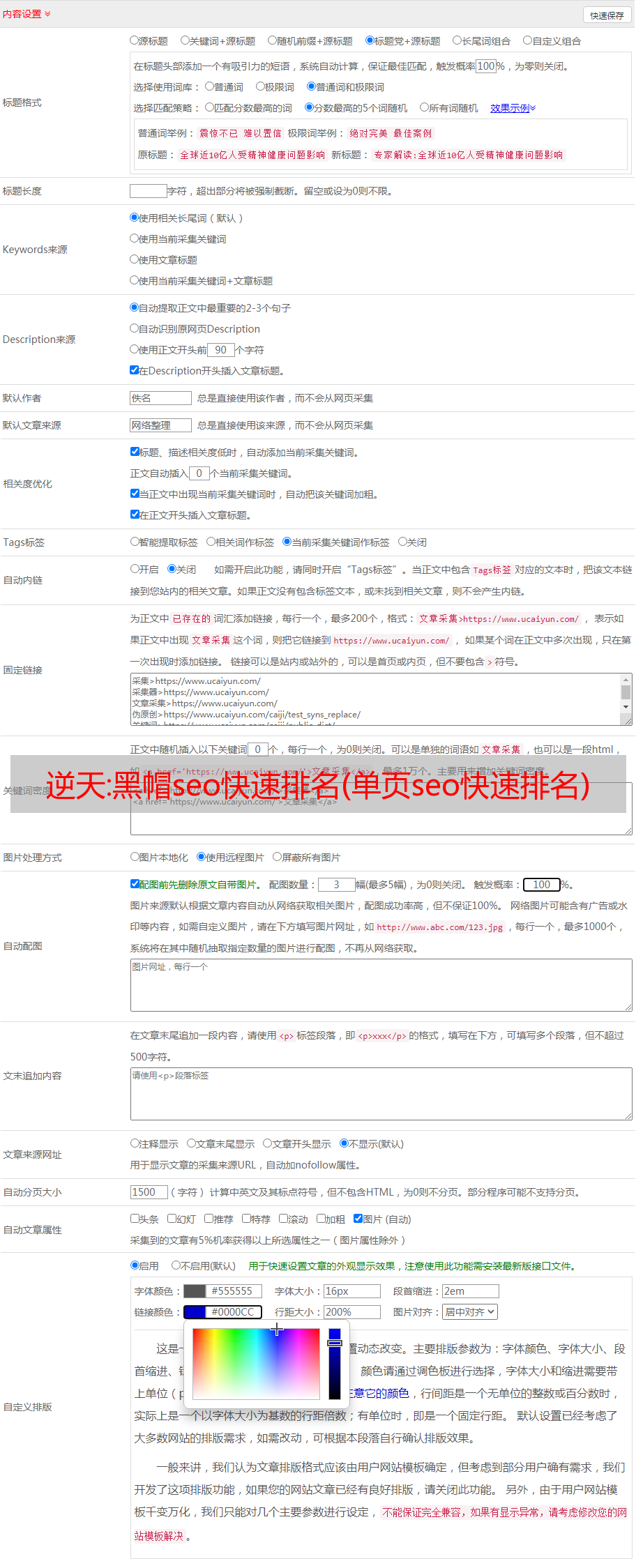
第三,WordPress 伪原创 插件快速创建原创 内容并不断更新网站。
要创建大量 原创 内容,首先需要大量 文章 素材。批量创作原创内容的过程是(采集行业相关的文章-处理伪原创-通过WordPress中的SEO能力提高页面原创性能伪原创插件) - 主动推送到主要搜索引擎)。在这个WordPress伪原创插件中我们不需要学习更多的专业技能,只需几个简单的步骤就可以轻松采集内容数据。用户只需要在 WordPress 伪原创 插件上进行简单的设置。完成后,WordPress 伪原创插件会根据用户设置的关键词采集高精度的内容和图片。可以保存在本地,也可以伪原创发布,提供方便快捷的内容采集和伪原创 出版服务!!
与其他WordPress伪原创插件相比,这个WordPress伪原创插件基本没有门槛,不需要花很多时间学习正则表达式或者html标签。一分钟后即可使用,只需输入 关键词 即可添加书签(WordPress 伪原创 插件还带有 关键词 书签功能)。一路挂断!将任务设置为自动化 采集pseudo-raw 发布推送任务。(支持本地采集和手动修改)
无论你有成百上千个不同的cms网站,都可以实现统一管理。一个人维护数百个网站文章更新不是问题。这个皇家伪原创插件还配备了很多SEO功能,通过软件采集伪原创的发布的同时可以提升很多SEO优化。
比如网站主动推送(让搜索引擎更快找到我们的网站),自动匹配图片(如果文章里面没有图片,会自动配置相关图片)。设置为自动下载图片并保存在本地或第三方(使内容不存在于对方外链)。自动链接(让搜索引擎更深入地抓取你的链接),前后插入内容或标题,插入网站内容或随机作者,随机阅读等,形成“高度原创”。定期发布(定期发布文章,以便搜索引擎及时抓取您的网站内容)
这些小的 SEO 功能不仅提高了 网站 页面的 原创 性能,还间接提高了 网站 的排名。您可以直接监控管理软件工具,查看文章的收录发布和百度推送,无需每天登录网站后台。目前博主亲测软件是免费的,可以直接下载使用!
首先,给自己设定一个合理的学习时间框架。
你为什么这么说?这真的很容易。一切都必须有计划和有针对性。如果没有,最简单的事情也可以无限扩展。给自己一个最后期限是很重要的,比如两三个月。说说我自己吧。我属于励志青年。
后面两个月的学习时间有限,大概需要三个月的时间来学习上手。给自己一个截止日期是合理的。为什么要讲道理?这是因为许多学生的理解能力不同。如果讲摊位的价格,你两三个月就学会了,他们两三个月就停止学习了。
很容易产生失败感而放弃学习。有的可能需要半年,有的可能一个月就学会了。当然,这是在某人的指导下。目前,一年的效果普遍不理想。
其次,你自己必须有一个网站。
很多同学想做SEO,但是没有网站。没有网站,他们就无法练习。就像我过去学的CAD一样,他们基本上一两年就忘记了。所以如果他们只学习理论而不实践和应用,他们很快就会忘记。经验是积累的。
第三,不要做你做不到的事情网站。
不能做的事不做是什么意思?指一些你很难做到的网站,因为你作为锁泉站长,没有那么多的资金和资源去做推广和营销,有些网站不适合优化,还是需要资源做的,个人不推荐。
比如,kiosk厂商不应该做团购导航或者美谈之类的分享社区,因为很难做到。类似于我自己开发的软件,功能齐全,游戏、IP变更、外贸等。相当于做起来更轻松。
第四,学会养成数据分析的习惯。
如果一个SEO从业者不分析数据,他基本上就不是一个合格的SEOER。养成数据分析的习惯,每天了解网站的数据,比如IIS日志、页面收录、页面点击、实时访问、百度PV、UV、IP等数据统计数据。
这些数据可以反映你的一些网站情况,是否有异常等等。有时候你的网站出了问题,你也不知道怎么回事。
第五,继续研究一些官方的文章搜索引擎。
不是每个人都非常擅长搜索引擎。他们对搜索引擎了解不多,只能积累。百度和谷歌目前都有可以与网站管理员交流的社区。我的建议是多去这些地方活动,可以看到很多有用的知识。也推荐阅读百度和谷歌的空优化指南。
根据你对SEO的理解,层次不同,同一件事在不同时期可以有不同的理解,会有不同的收获。看一遍有收获,再看一遍有收获。
看完这篇文章,如果觉得不错,不妨留着,或者发给需要的朋友同事。关注博主,每天带您体验各种 SEO 体验,完成您的约会!
给力:高可用 Prometheus:问题集锦【转】
2021-06-30
监控系统历史悠久,是一个非常成熟的方向,而Prometheus作为新一代的开源监控系统,已经逐渐成为云原生系统的事实标准,这也证明了它的设计很受欢迎. 本文主要分享Prometheus在实践中遇到的一些问题和思考。如果你对 K8S 监控系统或者 Prometheus 的设计不是很了解,可以先看看容器监控系列。
几个原则 Prometheus 限制 K8S 集群中常用的 exporter
Prometheus 是一个 CNCF 项目,拥有完整的开源生态系统。与Zabbix等传统代理监控不同,它提供了丰富的exporter来满足你的各种需求。您可以在此处查看官方和非官方出口商。如果还是不能满足你的需求,你也可以自己写一个exporter,简单方便,完全开放,这是一个优势。
但是,过于开放会带来选择和试错的成本。以前只需在 zabbix 代理中进行几行配置即可完成的工作,现在您将需要大量的导出器来完成它。还维护和监控所有出口商。尤其是升级exporter版本的时候,很痛苦。非官方的exporter会有很多bug。这是一个用处,当然也是Prometheus的设计原则。
K8S 生态系统的组件将提供 /metric 接口以提供自我监控。以下是我们正在使用的:
还有各种场景下的自定义导出器,比如日志提取,后面会介绍。
K8S核心组件监控和Grafana面板
k8s集群运行过程中,需要关注核心组件的状态和性能。比如kubelet、apiserver等,根据上面提到的exporter指标,可以在Grafana中绘制如下图表:
模板可以参考dashboards-for-kubernetes-administrators,根据运行情况不断调整告警阈值。
这里提到,虽然Grafana支持模板能力,可以方便的进行多级下拉框选择,但不支持模板模式下配置告警规则。相关问题
官方解释了很多这个功能,但是最新的版本还是不支持。从 issue 中借用一句话吐出:
It would be grate to add templates support in alerts. Otherwise the feature looks useless a bit.
Grafana的基本用法可以看这个文章
采集组件多合一
Prometheus 系统中的 Exporter 是独立的,每个组件都各司其职,例如 Node-Exporter 用于机器资源,Nvidia Exporter 用于 Gpu 等。但是Exporters越多,运维压力就越大,尤其是Agent的资源控制和版本升级。我们尝试结合一些Exporters,有两种解决方案:
通过主进程拉起 N 个 Exporter 进程,您仍然可以关注社区版本的更新和错误修复。使用 Telegraf 支持各种类型的 Input,N in 1。
此外,Node-Exporter 不支持进程监控。可以添加一个Process-Exporter,也可以使用上面提到的Telegraf 来使用procstat 的输入到采集process 指标。
黄金指标的合理选择
采集的指标很多,我们应该关注哪些呢?Google 在《Sre 手册》中提出了“四个黄金信号”:延迟、流量、错误数和饱和度。在实践中,您可以使用 Use 或 Red 方法作为指导,Use 用于资源,Red 用于服务。
Prometheus 采集 中共有三个常用服务:
在线服务:如Web服务、数据库等,一般关注请求率、延迟和错误率即RED方法离线服务:如日志处理、消息队列等,一般关注队列数、正在进行的数量、处理速度和出现的错误 使用方法 批处理任务:类似于离线任务,但离线任务是长时间运行的,批处理任务是按计划运行的,比如持续集成就是批处理任务,对应job或者K8S中的cronjob,一般要注意开销时间、错误次数等,因为运行周期短,很有可能在采集到来之前运行就结束了,所以一般使用pushgateway,并将拉改为推。
Use和Red的实例请参考容器监控实践-K8S常用指标分析文章。
K8S中Cadvisor的指标兼容性问题1.16
在 K8S 1.16 版本中,Cadvisor 指标移除了 pod_Name 和 container_name 的标签,并将它们替换为 pod 和 container。如果之前使用这两个标签进行查询或Grafana绘图,则需要更改Sql。因为我们一直支持多个 K8S 版本,所以我们通过 relabel 配置继续保留原来的 **_name。
metric_relabel_configs:
- source_labels: [container]
regex: (.+)
target_label: container_name
replacement:
action: replace
- source_labels: [pod]
regex: (.+)
target_label: pod_name
replacement:
action: replace
注意使用metric_relabel_configs,而不是relabel_configs,替换在采集之后。
Prometheus 采集外接K8S集群,多集群
如果Prometheus部署在K8S集群采集,使用官方的Yaml很方便,但是因为权限和网络的关系,我们需要部署在集群外,二进制操作,采集多个K8S集群.
Pod模式在集群中运行不需要证书(In-Cluster模式),但需要在集群外声明一个token等证书,并替换地址,即使用Apiserver Proxy采集 ,以Cadvisor采集为例,Job配置为:
- job_name: cluster-cadvisor
honor_timestamps: true
scrape_interval: 30s
scrape_timeout: 10s
metrics_path: /metrics
scheme: https
kubernetes_sd_configs:
- api_server: https://xx:6443
role: node
bearer_token_file: token/cluster.token
tls_config:
insecure_skip_verify: true
bearer_token_file: token/cluster.token
tls_config:
insecure_skip_verify: true
relabel_configs:
- separator: ;
regex: __meta_kubernetes_node_label_(.+)
replacement:
action: labelmap
- separator: ;
regex: (.*)
target_label: __address__
replacement: xx:6443
action: replace
- source_labels: [__meta_kubernetes_node_name]
separator: ;
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/
/proxy/metrics/cadvisoraction: replace
metric_relabel_configs:
- source_labels: [container]
separator: ;
regex: (.+)
target_label: container_name
replacement:
action: replace
- source_labels: [pod]
separator: ;
regex: (.+)
target_label: pod_name
replacement:
action: replace
Bearer_token_file 需要提前生成,这个可以参考官方文档。记住base64解码。
对于cadvisor,可以将__metrics_path__转换为/api/v1/nodes/
/proxy/metrics/cadvisor,代表Apiserver代理到Kubelet,如果网络可以通,也可以直接使用Kubelet的10255作为目标,可以直接写成::10255/metrics/cadvisor,意思是直接请求Kubelet,在规模大的时候减轻Apiserver的压力,即使用Apiserver进行服务发现,采集Apiserver 未使用因为cadvisor暴露了主机端口,所以配置比较简单。如果是kube-state-metric之类的Deployment,是以endpoint的形式暴露出来的,写法应该是:
- job_name: cluster-service-endpoints
honor_timestamps: true
scrape_interval: 30s
scrape_timeout: 10s
metrics_path: /metrics
scheme: https
kubernetes_sd_configs:
- api_server: https://xxx:6443
role: endpoints
bearer_token_file: token/cluster.token
tls_config:
insecure_skip_verify: true
bearer_token_file: token/cluster.token
tls_config:
insecure_skip_verify: true
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
separator: ;
regex: "true"
replacement:
action: keep
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
separator: ;
regex: (https?)
target_label: __scheme__
replacement:
action: replace
- separator: ;
regex: (.*)
target_label: __address__
replacement: xxx:6443
action: replace
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_endpoints_name,
__meta_kubernetes_service_annotation_prometheus_io_port]
separator: ;
regex: (.+);(.+);(.*)
target_label: __metrics_path__
replacement: /api/v1/namespaces/
/services/逆天:黑帽seo快速排名(单页seo快速排名)
优采云 发布时间: 2022-10-02 18:15逆天:黑帽seo快速排名(单页seo快速排名)
新手如何使用WordPress 伪原创插件快速创建原创内容,快速获取网站收录和排名关键词?新手 SEO 应该怎么做?快速开始。
从新手到高手,坚持排名优化很重要。很多新手在做SEO的时候总是会陷入误区。其实他们心里是很想学seo的,但是因为不懂seo这个行业,所以走在新手的路上越来越难了。大多数新手在刚接触 seo 行业时总是不耐烦。经过几天的SEO,我开始不耐烦了。为什么它不起作用?然后他们去找各种seo老手。一般做seo的资深人士会耐心回答等等。这还早了一个月,但这是真的。这时,新手会开始感到迷茫和不知所措。那么,让我们来看看新手不擅长SEO的原因。
我不知道从哪里开始。
有很多新手对seo还是很感兴趣的,只是不知道从哪里开始,不知道怎么入手,也不知道怎么理解它的技术点。所以在这种情况下,我建议先百度一下,对seo这个行业有一个大概的了解,然后再学一些编程语言,就不用知道学编程语言有多难了。只要学过基本的HTML语言和PHP/ASP/JAVA等一些简单的编程语言,还必须学习数据分析,这是一个很重要的课题。网站 优化的质量取决于数据分析后定制执行方法的有效性。
在大部分学习者看来,所谓的SEO就是把想要的关键词优化到首页,但真正的SEO是搜索引擎优化,而不是搜索排名优化。正是因为排名被视为SEO的整体,所以没有人整天关心排名,导致很多人半途而废。总之,您对 SEO 的了解程度取决于您可以在 SEO 中走多远。
二、缺乏毅力
由于seo是一项长期有效的工作,所以大部分放弃seo的新手都是因为坚持不了。在做了几天没有效果之后,他们总是感到受到打击。但实际上,这不仅是新手如此,老手也是如此。所有从事seo多年的人都有耐心。如果你没有耐心,无论你多么熟练,你都无法完成这项工作。但不是没有优化一下子就能看到效果,但不是优化,是作弊。黑帽seo也可以在短时间内看到效果,但是想要在一个好的关键词排名中实现长期稳定,黑帽seo做不到,所以一定要坚持,否则不会能够去。新手的方法。
第三,WordPress 伪原创 插件快速创建原创 内容并不断更新网站。
要创建大量 原创 内容,首先需要大量 文章 素材。批量创作原创内容的过程是(采集行业相关的文章-处理伪原创-通过WordPress中的SEO能力提高页面原创性能伪原创插件) - 主动推送到主要搜索引擎)。在这个WordPress伪原创插件中我们不需要学习更多的专业技能,只需几个简单的步骤就可以轻松采集内容数据。用户只需要在 WordPress 伪原创 插件上进行简单的设置。完成后,WordPress 伪原创插件会根据用户设置的关键词采集高精度的内容和图片。可以保存在本地,也可以伪原创发布,提供方便快捷的内容采集和伪原创 出版服务!!
与其他WordPress伪原创插件相比,这个WordPress伪原创插件基本没有门槛,不需要花很多时间学习正则表达式或者html标签。一分钟后即可使用,只需输入 关键词 即可添加书签(WordPress 伪原创 插件还带有 关键词 书签功能)。一路挂断!将任务设置为自动化 采集pseudo-raw 发布推送任务。(支持本地采集和手动修改)
无论你有成百上千个不同的cms网站,都可以实现统一管理。一个人维护数百个网站文章更新不是问题。这个皇家伪原创插件还配备了很多SEO功能,通过软件采集伪原创的发布的同时可以提升很多SEO优化。
比如网站主动推送(让搜索引擎更快找到我们的网站),自动匹配图片(如果文章里面没有图片,会自动配置相关图片)。设置为自动下载图片并保存在本地或第三方(使内容不存在于对方外链)。自动链接(让搜索引擎更深入地抓取你的链接),前后插入内容或标题,插入网站内容或随机作者,随机阅读等,形成“高度原创”。定期发布(定期发布文章,以便搜索引擎及时抓取您的网站内容)
这些小的 SEO 功能不仅提高了 网站 页面的 原创 性能,还间接提高了 网站 的排名。您可以直接监控管理软件工具,查看文章的收录发布和百度推送,无需每天登录网站后台。目前博主亲测软件是免费的,可以直接下载使用!
首先,给自己设定一个合理的学习时间框架。
你为什么这么说?这真的很容易。一切都必须有计划和有针对性。如果没有,最简单的事情也可以无限扩展。给自己一个最后期限是很重要的,比如两三个月。说说我自己吧。我属于励志青年。
后面两个月的学习时间有限,大概需要三个月的时间来学习上手。给自己一个截止日期是合理的。为什么要讲道理?这是因为许多学生的理解能力不同。如果讲摊位的价格,你两三个月就学会了,他们两三个月就停止学习了。
很容易产生失败感而放弃学习。有的可能需要半年,有的可能一个月就学会了。当然,这是在某人的指导下。目前,一年的效果普遍不理想。
其次,你自己必须有一个网站。
很多同学想做SEO,但是没有网站。没有网站,他们就无法练习。就像我过去学的CAD一样,他们基本上一两年就忘记了。所以如果他们只学习理论而不实践和应用,他们很快就会忘记。经验是积累的。
第三,不要做你做不到的事情网站。
不能做的事不做是什么意思?指一些你很难做到的网站,因为你作为锁泉站长,没有那么多的资金和资源去做推广和营销,有些网站不适合优化,还是需要资源做的,个人不推荐。
比如,kiosk厂商不应该做团购导航或者美谈之类的分享社区,因为很难做到。类似于我自己开发的软件,功能齐全,游戏、IP变更、外贸等。相当于做起来更轻松。
第四,学会养成数据分析的习惯。
如果一个SEO从业者不分析数据,他基本上就不是一个合格的SEOER。养成数据分析的习惯,每天了解网站的数据,比如IIS日志、页面收录、页面点击、实时访问、百度PV、UV、IP等数据统计数据。
这些数据可以反映你的一些网站情况,是否有异常等等。有时候你的网站出了问题,你也不知道怎么回事。
第五,继续研究一些官方的文章搜索引擎。
不是每个人都非常擅长搜索引擎。他们对搜索引擎了解不多,只能积累。百度和谷歌目前都有可以与网站管理员交流的社区。我的建议是多去这些地方活动,可以看到很多有用的知识。也推荐阅读百度和谷歌的空优化指南。
根据你对SEO的理解,层次不同,同一件事在不同时期可以有不同的理解,会有不同的收获。看一遍有收获,再看一遍有收获。
看完这篇文章,如果觉得不错,不妨留着,或者发给需要的朋友同事。关注博主,每天带您体验各种 SEO 体验,完成您的约会!
给力:高可用 Prometheus:问题集锦【转】
2021-06-30
监控系统历史悠久,是一个非常成熟的方向,而Prometheus作为新一代的开源监控系统,已经逐渐成为云原生系统的事实标准,这也证明了它的设计很受欢迎. 本文主要分享Prometheus在实践中遇到的一些问题和思考。如果你对 K8S 监控系统或者 Prometheus 的设计不是很了解,可以先看看容器监控系列。
几个原则 Prometheus 限制 K8S 集群中常用的 exporter
Prometheus 是一个 CNCF 项目,拥有完整的开源生态系统。与Zabbix等传统代理监控不同,它提供了丰富的exporter来满足你的各种需求。您可以在此处查看官方和非官方出口商。如果还是不能满足你的需求,你也可以自己写一个exporter,简单方便,完全开放,这是一个优势。
但是,过于开放会带来选择和试错的成本。以前只需在 zabbix 代理中进行几行配置即可完成的工作,现在您将需要大量的导出器来完成它。还维护和监控所有出口商。尤其是升级exporter版本的时候,很痛苦。非官方的exporter会有很多bug。这是一个用处,当然也是Prometheus的设计原则。
K8S 生态系统的组件将提供 /metric 接口以提供自我监控。以下是我们正在使用的:
还有各种场景下的自定义导出器,比如日志提取,后面会介绍。
K8S核心组件监控和Grafana面板
k8s集群运行过程中,需要关注核心组件的状态和性能。比如kubelet、apiserver等,根据上面提到的exporter指标,可以在Grafana中绘制如下图表:
模板可以参考dashboards-for-kubernetes-administrators,根据运行情况不断调整告警阈值。
这里提到,虽然Grafana支持模板能力,可以方便的进行多级下拉框选择,但不支持模板模式下配置告警规则。相关问题
官方解释了很多这个功能,但是最新的版本还是不支持。从 issue 中借用一句话吐出:
It would be grate to add templates support in alerts. Otherwise the feature looks useless a bit.
Grafana的基本用法可以看这个文章
采集组件多合一
Prometheus 系统中的 Exporter 是独立的,每个组件都各司其职,例如 Node-Exporter 用于机器资源,Nvidia Exporter 用于 Gpu 等。但是Exporters越多,运维压力就越大,尤其是Agent的资源控制和版本升级。我们尝试结合一些Exporters,有两种解决方案:
通过主进程拉起 N 个 Exporter 进程,您仍然可以关注社区版本的更新和错误修复。使用 Telegraf 支持各种类型的 Input,N in 1。
此外,Node-Exporter 不支持进程监控。可以添加一个Process-Exporter,也可以使用上面提到的Telegraf 来使用procstat 的输入到采集process 指标。
黄金指标的合理选择
采集的指标很多,我们应该关注哪些呢?Google 在《Sre 手册》中提出了“四个黄金信号”:延迟、流量、错误数和饱和度。在实践中,您可以使用 Use 或 Red 方法作为指导,Use 用于资源,Red 用于服务。
Prometheus 采集 中共有三个常用服务:
在线服务:如Web服务、数据库等,一般关注请求率、延迟和错误率即RED方法离线服务:如日志处理、消息队列等,一般关注队列数、正在进行的数量、处理速度和出现的错误 使用方法 批处理任务:类似于离线任务,但离线任务是长时间运行的,批处理任务是按计划运行的,比如持续集成就是批处理任务,对应job或者K8S中的cronjob,一般要注意开销时间、错误次数等,因为运行周期短,很有可能在采集到来之前运行就结束了,所以一般使用pushgateway,并将拉改为推。
Use和Red的实例请参考容器监控实践-K8S常用指标分析文章。
K8S中Cadvisor的指标兼容性问题1.16
在 K8S 1.16 版本中,Cadvisor 指标移除了 pod_Name 和 container_name 的标签,并将它们替换为 pod 和 container。如果之前使用这两个标签进行查询或Grafana绘图,则需要更改Sql。因为我们一直支持多个 K8S 版本,所以我们通过 relabel 配置继续保留原来的 **_name。
metric_relabel_configs:
- source_labels: [container]
regex: (.+)
target_label: container_name
replacement: $1
action: replace
- source_labels: [pod]
regex: (.+)
target_label: pod_name
replacement: $1
action: replace
注意使用metric_relabel_configs,而不是relabel_configs,替换在采集之后。
Prometheus 采集外接K8S集群,多集群
如果Prometheus部署在K8S集群采集,使用官方的Yaml很方便,但是因为权限和网络的关系,我们需要部署在集群外,二进制操作,采集多个K8S集群.
Pod模式在集群中运行不需要证书(In-Cluster模式),但需要在集群外声明一个token等证书,并替换地址,即使用Apiserver Proxy采集 ,以Cadvisor采集为例,Job配置为:
- job_name: cluster-cadvisor
honor_timestamps: true
scrape_interval: 30s
scrape_timeout: 10s
metrics_path: /metrics
scheme: https
kubernetes_sd_configs:
- api_server: https://xx:6443
role: node
bearer_token_file: token/cluster.token
tls_config:
insecure_skip_verify: true
bearer_token_file: token/cluster.token
tls_config:
insecure_skip_verify: true
relabel_configs:
- separator: ;
regex: __meta_kubernetes_node_label_(.+)
replacement: $1
action: labelmap
- separator: ;
regex: (.*)
target_label: __address__
replacement: xx:6443
action: replace
- source_labels: [__meta_kubernetes_node_name]
separator: ;
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
action: replace
metric_relabel_configs:
- source_labels: [container]
separator: ;
regex: (.+)
target_label: container_name
replacement: $1
action: replace
- source_labels: [pod]
separator: ;
regex: (.+)
target_label: pod_name
replacement: $1
action: replace
Bearer_token_file 需要提前生成,这个可以参考官方文档。记住base64解码。
对于cadvisor,可以将__metrics_path__转换为/api/v1/nodes/${1}/proxy/metrics/cadvisor,代表Apiserver代理到Kubelet,如果网络可以通,也可以直接使用Kubelet的10255作为目标,可以直接写成:${1}:10255/metrics/cadvisor,意思是直接请求Kubelet,在规模大的时候减轻Apiserver的压力,即使用Apiserver进行服务发现,采集Apiserver 未使用
因为cadvisor暴露了主机端口,所以配置比较简单。如果是kube-state-metric之类的Deployment,是以endpoint的形式暴露出来的,写法应该是:
- job_name: cluster-service-endpoints
honor_timestamps: true
scrape_interval: 30s
scrape_timeout: 10s
metrics_path: /metrics
scheme: https
kubernetes_sd_configs:
- api_server: https://xxx:6443
role: endpoints
bearer_token_file: token/cluster.token
tls_config:
insecure_skip_verify: true
bearer_token_file: token/cluster.token
tls_config:
insecure_skip_verify: true
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
separator: ;
regex: "true"
replacement: $1
action: keep
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
separator: ;
regex: (https?)
target_label: __scheme__
replacement: $1
action: replace
- separator: ;
regex: (.*)
target_label: __address__
replacement: xxx:6443
action: replace
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_endpoints_name,
__meta_kubernetes_service_annotation_prometheus_io_port]
separator: ;
regex: (.+);(.+);(.*)
target_label: __metrics_path__
replacement: /api/v1/namespaces/${1}/services/${2}:${3}/proxy/metrics
action: replace
- separator: ;
regex: __meta_kubernetes_service_label_(.+)
replacement: $1
action: labelmap
- source_labels: [__meta_kubernetes_namespace]
separator: ;
regex: (.*)
<p>
target_label: kubernetes_namespace
replacement: $1
action: replace
- source_labels: [__meta_kubernetes_service_name]
separator: ;
regex: (.*)
target_label: kubernetes_name
replacement: $1
action: replace
</p>
对于端点类型,需要将__metrics_path__转换为/api/v1/namespaces/${1}/services/${2}:${3}/proxy/metrics,需要替换命名空间、svc名称端口、等等,这里的写法只适用于接口为/metrics的exporter。如果你的 exporter 不是 /metrics 接口,你需要替换这个路径。或者像我们一样将此地址用于统一约束。
这里的__meta_kubernetes_service_annotation_prometheus_io_port的来源是部署exporter时写的注解。大多数 文章 只提到 prometheus.io/scrape: 'true',但它也可以定义端口、路径和协议。为了方便采集时的替换处理。
其他一些relabels比如kubernetes_namespace是为了保留原创信息,方便做promql查询时的过滤条件。
如果是多集群,可以多次编写相同的配置。一般来说,一个集群可以配置三种类型的作业:
获取 GPU 指标
nvidia-smi 可以查看机器上的 GPU 资源,而 Cadvisor 实际上暴露了 Metrics 来指示容器的 GPU 使用情况。
container_accelerator_duty_cycle
container_accelerator_memory_total_bytes
container_accelerator_memory_used_bytes
如果想要更详细的 GPU 数据,可以安装 dcgm exporter,但 K8S 1.13 只能支持。
更改 Prometheus 的显示时区
为了避免时区混淆,Prometheus 使用 Unix Time 和 Utc 专门用于在所有组件中显示。不支持在配置文件中设置时区,也无法读取原生的/etc/timezone时区。
事实上,这个限制并不影响使用:
有关时区的讨论,请参阅此问题。
如何采集 LB 后面的 RS 度量
如果你有负载均衡LB,但是网络上的Prometheus只能访问LB本身,不能访问后续的RS,采集RS应该如何暴露metrics呢?
版本选择
Prometheus当前最新版本是2.16,Prometheus还在迭代中,所以尽量使用最新版本,1.X版本不是必须的。
2.16版本有一套实验UI,可以查看TSDB的状态,包括Top 10 Label、Metric。
Prometheus 大内存问题
随着规模变大,Prometheus 所需的 CPU 和内存都会增加,内存一般会先达到瓶颈。这里我们先讨论一下*敏*感*词*Prometheus的内存问题。
原因:
我的指标需要多少内存:
以我们的其中一台 Prometheus Server 为例,本地只保留了 2 个小时的数据,950,000 系列,大概占用的内存如下:
优化方案是什么:
Prometheus 内存使用分析:
相关问题:
Prometheus 容量规划
除了上面提到的内存,容量规划还包括磁盘存储规划,这和你的 Prometheus 架构有关。
Prometheus 每 2 小时将已经缓冲在内存中的数据压缩到磁盘上的块中。包括 Chunks、Indexes、Tombstones、Metadata,这些都占用了部分存储空间。一般来说,Prometheus 中存储的每个样本大约占用 1-2 个字节大小(1.7Byte)。您可以使用 Promql 查看每个样本平均占用多少空间:
"`重击
速率(prometheus_tsdb_compaction_chunk_size_bytes_sum[1h])
/
速率(prometheus_tsdb_compaction_chunk_samples_sum[1h])
{instance="0.0.0.0:8890", job="prometheus"} 1.252747585939941
"`
如果粗略估计本地磁盘的大小,可以使用以下公式:
磁盘大小 = 保留时间 * 每秒获取样本数 * 样本大小
在保留时间(retention_time_seconds)和样本大小(bytes_per_sample)不变的情况下,如果要降低本地磁盘的容量要求,只能降低每秒的样本数(ingested_samples_per_second)。
查看当前每秒采集的样本数:
rate(prometheus_tsdb_head_samples_appended_total[1h])
有两种手段,一种是减少时间序列的数量,另一种是增加采集个样本的时间间隔。考虑到 Prometheus 压缩了时间序列,减少时间序列数量的效果更加明显。
例如:
以上磁盘容量不包括wal文件。wal文件(Raw Data)在Prometheus官方文档中说明至少会保存3个Write-Ahead Log Files,每个最大大小为128M(实际数量会更多)。
因为我们使用的是灭霸的方案,所以本地磁盘只保留2H热数据。Wal 每 2 小时生成一个块文件,每 2 小时将块文件上传到对象存储。本地磁盘基本没有压力。
对于 Prometheus 的存储机制,你可以阅读这个。
对 Apiserver 的性能影响
如果你的 Prometheus 使用 kubernetes_sd_config 进行服务发现,请求一般会通过集群的 Apiserver。随着规模的增加,您需要评估对 Apiserver 性能的影响,尤其是当 Proxy 发生故障时,会导致 CPU 增加。当然,如果单个 K8S 集群规模过大,一般会进行集群拆分,但还是需要随时监控 Apiserver 的进程变化。
在监控Cadvisor、Docker、Kube-Proxy的metrics时,我们最初选择Apiserver Proxy到节点的对应端口,统一设置比较方便,后来改成直接拉节点,Apiserver只做服务发现.
Rate的计算逻辑
Prometheus 中的 Counter 类型主要是针对 Rate 存在的,即计算速率。纯Counter计数意义不大,因为一旦Counter复位,总计数就没有意义了。
Rate 会自动处理 Counter 的重置,通常会不断变大。例如,Exporter 启动然后崩溃。最初以每秒约 10 的速率递增,但只运行半小时,rate(x_total[1h]) 将返回每秒约 5 的结果。此外,计数器的任何减少也被视为计数器重置。例如,如果时间序列的值为 [5,10,4,6],则将其视为 [5,10,14,16]。
费率值很少是准确的。由于不同目标的提取发生在不同的时间,抖动会随着时间的推移而发生,query_range 很少被计算为完全匹配提取时间,并且提取可能会失败。面对这样的挑战,Rate 的设计必须稳健。
Rate 不想捕获每个 delta,因为有时 delta 会丢失,例如实例在 fetch 间隔内死亡。如果 Counter 变化缓慢,比如每小时只增加几次,可能会导致 [artifacts]。例如,有一个值为 100 的 Counter 时间序列,Rate 不知道这些增量是否是当前值,或者目标是否已经运行了几年并且刚刚开始返回。
建议将 Rate 计算的范围向量的时间设置为至少 4 倍的 fetch 间隔。这将确保即使爬行缓慢和爬行失败,您也始终有两个可用的样本。此类问题在实践中经常出现,因此保持这种弹性很重要。例如,对于 1 分钟的爬网间隔,您可以使用 4 分钟的速率计算,但这通常四舍五入为 5 分钟。
如果Rate的时间区间有缺失数据,他会根据趋势做出推断,比如:
有关详细信息,请参阅此视频
违反直觉的 P95 统计数据
histogram_quantile 是 Prometheus 常用的一个函数,例如,一个服务的 P95 响应时间经常被用来衡量服务质量。但是,具体是什么意思很难解释,尤其是对非技术类的学生来说,会遭遇很多“灵魂拷问”。
我们常说的P95(P99,P90都可以)的响应延迟是100ms,其实就是说在所有采集到的响应延迟中,有5%的请求大于100ms,95%的请求小于100ms . Prometheus中的histogram_quantile函数接收一个0-1之间的小数,小数乘以100就可以很方便的得到对应的百分位数。比如0.95对应P95,也可以是更高的百分位精度,例如 0.9999。
当您使用 histogram_quantile 绘制响应时间趋势时,您可能会被问到:为什么 P95 大于或小于我的平均值?
正如中位数可能大于或小于平均值一样,P99 完全有可能小于平均值。通常 P99 几乎总是大于平均值,但如果数据分布极端,前 1% 可能会大到推高平均值。一个可能的例子:
1, 1, ... 1, 901 // 共 100 条数据,平均值=10,P99=1
服务X分两步完成,A和B,其中X的P99耗时100Ms,A进程的P99耗时50Ms。那么B流程的P99的预估时间是多少呢?
直觉上,既然X=A+B,答案大概是50Ms,或者至少应该小于50Ms。实际上,B可以大于50Ms。只要 A 和 B 中最大的 1% 不碰巧相遇,B 就可以有一个非常大的 P99:
A = 1, 1, ... 1, 1, 1, 50, 50 // 共 100 条数据,P99=50
B = 1, 1, ... 1, 1, 1, 99, 99 // 共 100 条数据,P99=99
X = 2, 2, ... 1, 51, 51, 100, 100 // 共 100 条数据,P99=100
如果让 A 过程最大的 1% 接近 100Ms,我们也能构造出 P99 很小的 B:
A = 50, 50, ... 50, 50, 99 // 共 100 条数据,P99=50
B = 1, 1, ... 1, 1, 50 // 共 100 条数据,P99=1
X = 51, 51, ... 51, 100, 100 // 共 100 条数据,P99=100
所以,我们从标题中唯一能确定的就是B的P99不应该超过100ms,而A的P99取50Ms的条件其实是没有用的。
类似的问题还有很多,所以对于 histogram_quantile 函数,可能会产生一些反直觉的结果。最好的处理方式就是不断调整你的 Bucket 的值,保证更多的请求次数落入更详细的范围内,这样请求时间在统计上是显着的。
查询慢问题
Promql 的基础见这个 文章
Prometheus 提供了一个自定义 Promql 作为查询语句。在Graph上调试的时候会告诉你这个Sql的返回时间。如果太慢,请注意,可能是您的使用有问题。
要评估 Prometheus 的整体响应时间,您可以使用以下默认指标:
prometheus_engine_query_duration_seconds{}
一般情况下,响应慢的原因是Promql使用不当,或者指标规划有问题,比如:
基数
高基数是数据库无法回避的话题。对于像 Mysql 这样的 DB,基数是指特定列或字段中收录的唯一值的数量。基数越低,列中重复的元素就越多。对于时间序列数据库,是标签、标签等标签值的个数。
例如,如果 Prometheus 中有一个指标 http_request_count{method="get",path="/abc",originIP="1.1.1.1"},则表示访问次数,method表示请求方法,originIP是客户端IP,method的枚举值是有限的,而originIP是无限的,再加上其他标签的排列组合是无限的,没有关联的特征,所以这种高基数不适合作为 Metric 标签,如果真的要提取 originIP,应该使用 log 的方式,而不是 Metric 监控
时间序列数据库对这些标签进行索引以提高查询性能,以便您可以快速找到与所有指定标签匹配的值。如果值的个数太大,索引就没有意义了,尤其是在做P95等计算的时候,需要扫描大量的Series数据
官方文档中对 Label 的建议
CAUTION: Remember that every unique combination of key-value label pairs represents a new time series, which can dramatically increase the amount of data stored. Do not use labels to store dimensions with high cardinality (many different label values), such as user IDs, email addresses, or other unbounded sets of values.
如何查看当前的Label分布,可以使用Prometheus提供的Tsdb工具。可以使用命令行查看,也可以在2.16版本以上的Prometheus Graph中查看
[work@xxx bin]$ ./tsdb analyze ../data/prometheus/
Block ID: 01E41588AJNGM31SPGHYA3XSXG
Duration: 2h0m0s
Series: 955372
Label names: 301
Postings (unique label pairs): 30757
Postings entries (total label pairs): 10842822
....
top10 高基数指标
Highest cardinality metric names:
87176 apiserver_request_latencies_bucket
59968 apiserver_response_sizes_bucket
39862 apiserver_request_duration_seconds_bucket
37555 container_tasks_state
....
高基数标签
Highest cardinality labels:
4271 resource_version
3670 id
3414 name
1857 container_id
1824 __name__
1297 uid
1276 pod
...
找到最大的指标或工作
top10 中的指标数量:按指标名称
topk(10, count by (__name__)({__name__=~".+"}))
apiserver_request_latencies_bucket{} 62544
apiserver_response_sizes_bucket{} 44600
top10中的metrics个数:按job name
topk(10, count by (__name__, job)({__name__=~".+"}))
{job="master-scrape"} 525667
{job="xxx-kubernetes-cadvisor"} 50817
{job="yyy-kubernetes-cadvisor"} 44261
Prometheus 重启慢且热重载
当 Prometheus 重启时,需要将 Wal 的内容加载到内存中。保留时间越长,Wal文件越大,实际重启的时间越长。这是普罗米修斯的机制,没有办法做到。因此,如果可以Reload,就不要重启,必须重启。会导致短期不可用,此时Prometheus的高可用就很重要了。
Prometheus 还优化了启动时间。在 2.6 版本中,优化了 Wal 的加载速度。我希望重启时间不会超过1分钟。
Prometheus 提供热加载能力,但需要启用 web.enable-lifecycle 配置。更改配置后,可以点击curl下的reload界面。默认情况下更改 prometheus-operator 中的配置将触发重新加载。如果你不使用算子,又想监控 configmap 配置变化来重新加载服务,可以试试这个简单的脚本
#!/bin/sh
FILE=$1
URL=$2
HASH=$(md5sum $(readlink -f $FILE))
while true; do
NEW_HASH=$(md5sum $(readlink -f $FILE))
if [ "$HASH" != "$NEW_HASH" ]; then
HASH="$NEW_HASH"
echo "[$(date +%s)] Trigger refresh"
curl -sSL -X POST "$2" > /dev/null
fi
sleep 5
done
使用时挂载和prometheus一样的configmap,传入如下参数:
args:
- /etc/prometheus/prometheus.yml
- http://prometheus.kube-system.svc.cluster.local:9090/-/reload
args:
- /etc/alertmanager/alertmanager.yml
- http://prometheus.kube-system.svc.cluster.local:9093/-/reload
您的应用需要公开多少指标
自己开发服务的时候,可能会暴露一些数据给metrics,比如具体请求的数量,goroutines的数量等等,多少metrics比较合适呢?
虽然指标的数量与您的应用程序的大小有关,但有一些建议(Brian Brazil),
比如缓存等简单的服务,类似于Pushgateway,有120个左右的指标。Prometheus 本身公开了大约 700 个指标。如果您的应用程序很大,请尽量不要超过 10,000 个指标。您需要合理控制您的标签。
node-exporter node-exporter不支持进程监控的问题,前面已经讲过了。node-exporter 只支持 unix 系统,windows 机器请使用 wmi_exporter。因此,当yaml形式不是node-exporter时,node-selector应该指明os类型。因为node_exporter是老组件,有一些最佳实践没有合并,比如符合Prometheus命名约定,所以推荐使用较新的0.16和0.17版本。
一些指标名称更改:
* node_cpu -> node_cpu_seconds_total
* node_memory_MemTotal -> node_memory_MemTotal_bytes
* node_memory_MemFree -> node_memory_MemFree_bytes
* node_filesystem_avail -> node_filesystem_avail_bytes
* node_filesystem_size -> node_filesystem_size_bytes
* node_disk_io_time_ms -> node_disk_io_time_seconds_total
* node_disk_reads_completed -> node_disk_reads_completed_total
* node_disk_sectors_written -> node_disk_written_bytes_total
* node_time -> node_time_seconds
* node_boot_time -> node_boot_time_seconds
* node_intr -> node_intr_total
如果之前使用过旧版本的exporter,绘制grafana时指标名称会有所不同。有两种解决方案:
kube-state-metric 的问题
kube-state-metric的使用和原理可以先阅读
除了文章中提到的功能,kube-state-metric还有一个很重要的使用场景,就是结合cadvisor metrics。原来的cadvisor只有pod信息,不知道属于哪个deployment或者sts,但是用kube-state-metric中的kube_pod_info可以在join查询后显示。kube-state-metric 的元数据索引在扩展 cadvisor 的标签方面起到了很大的作用。prometheus-operator 的许多记录规则使用 kube-state-metric 进行组合查询。
Pod 的标签信息也可以在 kube-state-metric 中展示,这样可以在获取 cadvisor 数据后进行分组更方便,比如根据 Pod 的运行环境进行分类。但是,kube-state-metric 不会暴露 pod 的注释。原因是下面提到的高基数问题,即注解的内容太多,不适合作为指标暴露。
relabel_configs 和 metric_relabel_configs
relabel_config 出现在 采集 之前,metric_relabel_configs 出现在 采集 之后。合理的组合可以满足很多场景的配置。
喜欢:
metric_relabel_configs:
- separator: ;
regex: instance
replacement: $1
action: labeldrop
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_endpoints_name,
__meta_kubernetes_service_annotation_prometheus_io_port]
separator: ;
regex: (.+);(.+);(.*)
target_label: __metrics_path__
replacement: /api/v1/namespaces/${1}/services/${2}:${3}/proxy/metrics
action: replace
Prometheus 的预测能力
场景一:你的磁盘剩余空间一直在减少,减少的幅度比较均匀。您想知道达到阈值需要多长时间,并且您想在某个时刻发出警报。
场景二:你的 Pod 的内存使用量一直在增加,你想知道需要多长时间才能达到 Limit 值,并在某个时间报警,并在被杀死之前检查。
Prometheus 的 Deriv 和 Predict_Linear 方法可以满足这样的需求。Promtheus 提供基本的预测能力,根据当前的变化率,推断一段时间后的值。
以 mem_free 为例,最近一小时 free 值一直在下降。
mem_free仅为举例,实际内存可用以mem_available为准
deriv 函数可以显示一段时间内指标的变化率:
predict_linear 方法就是根据这个速度来预测最终可达到的值:
predict_linear(mem_free{instanceIP="100.75.155.55"}[1h], 2*3600)/1024/1024
您可以根据设置设置合理的报警规则,例如小于10时报警:
<p>rule: predict_linear(mem_free{instanceIP="100.75.155.55"}[1h], 2*3600)/1024/1024
0 个评论
官方客服QQ群


在
线
客
服
action: replace
- separator: ;
regex: __meta_kubernetes_service_label_(.+)
replacement:
action: labelmap
- source_labels: [__meta_kubernetes_namespace]
separator: ;
regex: (.*)
<p>
target_label: kubernetes_namespace
replacement:
action: replace
- source_labels: [__meta_kubernetes_service_name]
separator: ;
regex: (.*)
target_label: kubernetes_name
replacement:
action: replace
</p>
对于端点类型,需要将__metrics_path__转换为/api/v1/namespaces/
/services/逆天:黑帽seo快速排名(单页seo快速排名)
优采云 发布时间: 2022-10-02 18:15逆天:黑帽seo快速排名(单页seo快速排名)
新手如何使用WordPress 伪原创插件快速创建原创内容,快速获取网站收录和排名关键词?新手 SEO 应该怎么做?快速开始。
从新手到高手,坚持排名优化很重要。很多新手在做SEO的时候总是会陷入误区。其实他们心里是很想学seo的,但是因为不懂seo这个行业,所以走在新手的路上越来越难了。大多数新手在刚接触 seo 行业时总是不耐烦。经过几天的SEO,我开始不耐烦了。为什么它不起作用?然后他们去找各种seo老手。一般做seo的资深人士会耐心回答等等。这还早了一个月,但这是真的。这时,新手会开始感到迷茫和不知所措。那么,让我们来看看新手不擅长SEO的原因。
我不知道从哪里开始。
有很多新手对seo还是很感兴趣的,只是不知道从哪里开始,不知道怎么入手,也不知道怎么理解它的技术点。所以在这种情况下,我建议先百度一下,对seo这个行业有一个大概的了解,然后再学一些编程语言,就不用知道学编程语言有多难了。只要学过基本的HTML语言和PHP/ASP/JAVA等一些简单的编程语言,还必须学习数据分析,这是一个很重要的课题。网站 优化的质量取决于数据分析后定制执行方法的有效性。
在大部分学习者看来,所谓的SEO就是把想要的关键词优化到首页,但真正的SEO是搜索引擎优化,而不是搜索排名优化。正是因为排名被视为SEO的整体,所以没有人整天关心排名,导致很多人半途而废。总之,您对 SEO 的了解程度取决于您可以在 SEO 中走多远。
二、缺乏毅力
由于seo是一项长期有效的工作,所以大部分放弃seo的新手都是因为坚持不了。在做了几天没有效果之后,他们总是感到受到打击。但实际上,这不仅是新手如此,老手也是如此。所有从事seo多年的人都有耐心。如果你没有耐心,无论你多么熟练,你都无法完成这项工作。但不是没有优化一下子就能看到效果,但不是优化,是作弊。黑帽seo也可以在短时间内看到效果,但是想要在一个好的关键词排名中实现长期稳定,黑帽seo做不到,所以一定要坚持,否则不会能够去。新手的方法。
第三,WordPress 伪原创 插件快速创建原创 内容并不断更新网站。
要创建大量 原创 内容,首先需要大量 文章 素材。批量创作原创内容的过程是(采集行业相关的文章-处理伪原创-通过WordPress中的SEO能力提高页面原创性能伪原创插件) - 主动推送到主要搜索引擎)。在这个WordPress伪原创插件中我们不需要学习更多的专业技能,只需几个简单的步骤就可以轻松采集内容数据。用户只需要在 WordPress 伪原创 插件上进行简单的设置。完成后,WordPress 伪原创插件会根据用户设置的关键词采集高精度的内容和图片。可以保存在本地,也可以伪原创发布,提供方便快捷的内容采集和伪原创 出版服务!!
与其他WordPress伪原创插件相比,这个WordPress伪原创插件基本没有门槛,不需要花很多时间学习正则表达式或者html标签。一分钟后即可使用,只需输入 关键词 即可添加书签(WordPress 伪原创 插件还带有 关键词 书签功能)。一路挂断!将任务设置为自动化 采集pseudo-raw 发布推送任务。(支持本地采集和手动修改)
无论你有成百上千个不同的cms网站,都可以实现统一管理。一个人维护数百个网站文章更新不是问题。这个皇家伪原创插件还配备了很多SEO功能,通过软件采集伪原创的发布的同时可以提升很多SEO优化。
比如网站主动推送(让搜索引擎更快找到我们的网站),自动匹配图片(如果文章里面没有图片,会自动配置相关图片)。设置为自动下载图片并保存在本地或第三方(使内容不存在于对方外链)。自动链接(让搜索引擎更深入地抓取你的链接),前后插入内容或标题,插入网站内容或随机作者,随机阅读等,形成“高度原创”。定期发布(定期发布文章,以便搜索引擎及时抓取您的网站内容)
这些小的 SEO 功能不仅提高了 网站 页面的 原创 性能,还间接提高了 网站 的排名。您可以直接监控管理软件工具,查看文章的收录发布和百度推送,无需每天登录网站后台。目前博主亲测软件是免费的,可以直接下载使用!
首先,给自己设定一个合理的学习时间框架。
你为什么这么说?这真的很容易。一切都必须有计划和有针对性。如果没有,最简单的事情也可以无限扩展。给自己一个最后期限是很重要的,比如两三个月。说说我自己吧。我属于励志青年。
后面两个月的学习时间有限,大概需要三个月的时间来学习上手。给自己一个截止日期是合理的。为什么要讲道理?这是因为许多学生的理解能力不同。如果讲摊位的价格,你两三个月就学会了,他们两三个月就停止学习了。
很容易产生失败感而放弃学习。有的可能需要半年,有的可能一个月就学会了。当然,这是在某人的指导下。目前,一年的效果普遍不理想。
其次,你自己必须有一个网站。
很多同学想做SEO,但是没有网站。没有网站,他们就无法练习。就像我过去学的CAD一样,他们基本上一两年就忘记了。所以如果他们只学习理论而不实践和应用,他们很快就会忘记。经验是积累的。
第三,不要做你做不到的事情网站。
不能做的事不做是什么意思?指一些你很难做到的网站,因为你作为锁泉站长,没有那么多的资金和资源去做推广和营销,有些网站不适合优化,还是需要资源做的,个人不推荐。
比如,kiosk厂商不应该做团购导航或者美谈之类的分享社区,因为很难做到。类似于我自己开发的软件,功能齐全,游戏、IP变更、外贸等。相当于做起来更轻松。
第四,学会养成数据分析的习惯。
如果一个SEO从业者不分析数据,他基本上就不是一个合格的SEOER。养成数据分析的习惯,每天了解网站的数据,比如IIS日志、页面收录、页面点击、实时访问、百度PV、UV、IP等数据统计数据。
这些数据可以反映你的一些网站情况,是否有异常等等。有时候你的网站出了问题,你也不知道怎么回事。
第五,继续研究一些官方的文章搜索引擎。
不是每个人都非常擅长搜索引擎。他们对搜索引擎了解不多,只能积累。百度和谷歌目前都有可以与网站管理员交流的社区。我的建议是多去这些地方活动,可以看到很多有用的知识。也推荐阅读百度和谷歌的空优化指南。
根据你对SEO的理解,层次不同,同一件事在不同时期可以有不同的理解,会有不同的收获。看一遍有收获,再看一遍有收获。
看完这篇文章,如果觉得不错,不妨留着,或者发给需要的朋友同事。关注博主,每天带您体验各种 SEO 体验,完成您的约会!
给力:高可用 Prometheus:问题集锦【转】
2021-06-30
监控系统历史悠久,是一个非常成熟的方向,而Prometheus作为新一代的开源监控系统,已经逐渐成为云原生系统的事实标准,这也证明了它的设计很受欢迎. 本文主要分享Prometheus在实践中遇到的一些问题和思考。如果你对 K8S 监控系统或者 Prometheus 的设计不是很了解,可以先看看容器监控系列。
几个原则 Prometheus 限制 K8S 集群中常用的 exporter
Prometheus 是一个 CNCF 项目,拥有完整的开源生态系统。与Zabbix等传统代理监控不同,它提供了丰富的exporter来满足你的各种需求。您可以在此处查看官方和非官方出口商。如果还是不能满足你的需求,你也可以自己写一个exporter,简单方便,完全开放,这是一个优势。
但是,过于开放会带来选择和试错的成本。以前只需在 zabbix 代理中进行几行配置即可完成的工作,现在您将需要大量的导出器来完成它。还维护和监控所有出口商。尤其是升级exporter版本的时候,很痛苦。非官方的exporter会有很多bug。这是一个用处,当然也是Prometheus的设计原则。
K8S 生态系统的组件将提供 /metric 接口以提供自我监控。以下是我们正在使用的:
还有各种场景下的自定义导出器,比如日志提取,后面会介绍。
K8S核心组件监控和Grafana面板
k8s集群运行过程中,需要关注核心组件的状态和性能。比如kubelet、apiserver等,根据上面提到的exporter指标,可以在Grafana中绘制如下图表:
模板可以参考dashboards-for-kubernetes-administrators,根据运行情况不断调整告警阈值。
这里提到,虽然Grafana支持模板能力,可以方便的进行多级下拉框选择,但不支持模板模式下配置告警规则。相关问题
官方解释了很多这个功能,但是最新的版本还是不支持。从 issue 中借用一句话吐出:
It would be grate to add templates support in alerts. Otherwise the feature looks useless a bit.
Grafana的基本用法可以看这个文章
采集组件多合一
Prometheus 系统中的 Exporter 是独立的,每个组件都各司其职,例如 Node-Exporter 用于机器资源,Nvidia Exporter 用于 Gpu 等。但是Exporters越多,运维压力就越大,尤其是Agent的资源控制和版本升级。我们尝试结合一些Exporters,有两种解决方案:
通过主进程拉起 N 个 Exporter 进程,您仍然可以关注社区版本的更新和错误修复。使用 Telegraf 支持各种类型的 Input,N in 1。
此外,Node-Exporter 不支持进程监控。可以添加一个Process-Exporter,也可以使用上面提到的Telegraf 来使用procstat 的输入到采集process 指标。
黄金指标的合理选择
采集的指标很多,我们应该关注哪些呢?Google 在《Sre 手册》中提出了“四个黄金信号”:延迟、流量、错误数和饱和度。在实践中,您可以使用 Use 或 Red 方法作为指导,Use 用于资源,Red 用于服务。
Prometheus 采集 中共有三个常用服务:
在线服务:如Web服务、数据库等,一般关注请求率、延迟和错误率即RED方法离线服务:如日志处理、消息队列等,一般关注队列数、正在进行的数量、处理速度和出现的错误 使用方法 批处理任务:类似于离线任务,但离线任务是长时间运行的,批处理任务是按计划运行的,比如持续集成就是批处理任务,对应job或者K8S中的cronjob,一般要注意开销时间、错误次数等,因为运行周期短,很有可能在采集到来之前运行就结束了,所以一般使用pushgateway,并将拉改为推。
Use和Red的实例请参考容器监控实践-K8S常用指标分析文章。
K8S中Cadvisor的指标兼容性问题1.16
在 K8S 1.16 版本中,Cadvisor 指标移除了 pod_Name 和 container_name 的标签,并将它们替换为 pod 和 container。如果之前使用这两个标签进行查询或Grafana绘图,则需要更改Sql。因为我们一直支持多个 K8S 版本,所以我们通过 relabel 配置继续保留原来的 **_name。
metric_relabel_configs:
- source_labels: [container]
regex: (.+)
target_label: container_name
replacement: $1
action: replace
- source_labels: [pod]
regex: (.+)
target_label: pod_name
replacement: $1
action: replace
注意使用metric_relabel_configs,而不是relabel_configs,替换在采集之后。
Prometheus 采集外接K8S集群,多集群
如果Prometheus部署在K8S集群采集,使用官方的Yaml很方便,但是因为权限和网络的关系,我们需要部署在集群外,二进制操作,采集多个K8S集群.
Pod模式在集群中运行不需要证书(In-Cluster模式),但需要在集群外声明一个token等证书,并替换地址,即使用Apiserver Proxy采集 ,以Cadvisor采集为例,Job配置为:
- job_name: cluster-cadvisor
honor_timestamps: true
scrape_interval: 30s
scrape_timeout: 10s
metrics_path: /metrics
scheme: https
kubernetes_sd_configs:
- api_server: https://xx:6443
role: node
bearer_token_file: token/cluster.token
tls_config:
insecure_skip_verify: true
bearer_token_file: token/cluster.token
tls_config:
insecure_skip_verify: true
relabel_configs:
- separator: ;
regex: __meta_kubernetes_node_label_(.+)
replacement: $1
action: labelmap
- separator: ;
regex: (.*)
target_label: __address__
replacement: xx:6443
action: replace
- source_labels: [__meta_kubernetes_node_name]
separator: ;
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
action: replace
metric_relabel_configs:
- source_labels: [container]
separator: ;
regex: (.+)
target_label: container_name
replacement: $1
action: replace
- source_labels: [pod]
separator: ;
regex: (.+)
target_label: pod_name
replacement: $1
action: replace
Bearer_token_file 需要提前生成,这个可以参考官方文档。记住base64解码。
对于cadvisor,可以将__metrics_path__转换为/api/v1/nodes/${1}/proxy/metrics/cadvisor,代表Apiserver代理到Kubelet,如果网络可以通,也可以直接使用Kubelet的10255作为目标,可以直接写成:${1}:10255/metrics/cadvisor,意思是直接请求Kubelet,在规模大的时候减轻Apiserver的压力,即使用Apiserver进行服务发现,采集Apiserver 未使用
因为cadvisor暴露了主机端口,所以配置比较简单。如果是kube-state-metric之类的Deployment,是以endpoint的形式暴露出来的,写法应该是:
- job_name: cluster-service-endpoints
honor_timestamps: true
scrape_interval: 30s
scrape_timeout: 10s
metrics_path: /metrics
scheme: https
kubernetes_sd_configs:
- api_server: https://xxx:6443
role: endpoints
bearer_token_file: token/cluster.token
tls_config:
insecure_skip_verify: true
bearer_token_file: token/cluster.token
tls_config:
insecure_skip_verify: true
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
separator: ;
regex: "true"
replacement: $1
action: keep
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
separator: ;
regex: (https?)
target_label: __scheme__
replacement: $1
action: replace
- separator: ;
regex: (.*)
target_label: __address__
replacement: xxx:6443
action: replace
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_endpoints_name,
__meta_kubernetes_service_annotation_prometheus_io_port]
separator: ;
regex: (.+);(.+);(.*)
target_label: __metrics_path__
replacement: /api/v1/namespaces/${1}/services/${2}:${3}/proxy/metrics
action: replace
- separator: ;
regex: __meta_kubernetes_service_label_(.+)
replacement: $1
action: labelmap
- source_labels: [__meta_kubernetes_namespace]
separator: ;
regex: (.*)
<p>
target_label: kubernetes_namespace
replacement: $1
action: replace
- source_labels: [__meta_kubernetes_service_name]
separator: ;
regex: (.*)
target_label: kubernetes_name
replacement: $1
action: replace
</p>
对于端点类型,需要将__metrics_path__转换为/api/v1/namespaces/${1}/services/${2}:${3}/proxy/metrics,需要替换命名空间、svc名称端口、等等,这里的写法只适用于接口为/metrics的exporter。如果你的 exporter 不是 /metrics 接口,你需要替换这个路径。或者像我们一样将此地址用于统一约束。
这里的__meta_kubernetes_service_annotation_prometheus_io_port的来源是部署exporter时写的注解。大多数 文章 只提到 prometheus.io/scrape: 'true',但它也可以定义端口、路径和协议。为了方便采集时的替换处理。
其他一些relabels比如kubernetes_namespace是为了保留原创信息,方便做promql查询时的过滤条件。
如果是多集群,可以多次编写相同的配置。一般来说,一个集群可以配置三种类型的作业:
获取 GPU 指标
nvidia-smi 可以查看机器上的 GPU 资源,而 Cadvisor 实际上暴露了 Metrics 来指示容器的 GPU 使用情况。
container_accelerator_duty_cycle
container_accelerator_memory_total_bytes
container_accelerator_memory_used_bytes
如果想要更详细的 GPU 数据,可以安装 dcgm exporter,但 K8S 1.13 只能支持。
更改 Prometheus 的显示时区
为了避免时区混淆,Prometheus 使用 Unix Time 和 Utc 专门用于在所有组件中显示。不支持在配置文件中设置时区,也无法读取原生的/etc/timezone时区。
事实上,这个限制并不影响使用:
有关时区的讨论,请参阅此问题。
如何采集 LB 后面的 RS 度量
如果你有负载均衡LB,但是网络上的Prometheus只能访问LB本身,不能访问后续的RS,采集RS应该如何暴露metrics呢?
版本选择
Prometheus当前最新版本是2.16,Prometheus还在迭代中,所以尽量使用最新版本,1.X版本不是必须的。
2.16版本有一套实验UI,可以查看TSDB的状态,包括Top 10 Label、Metric。
Prometheus 大内存问题
随着规模变大,Prometheus 所需的 CPU 和内存都会增加,内存一般会先达到瓶颈。这里我们先讨论一下*敏*感*词*Prometheus的内存问题。
原因:
我的指标需要多少内存:
以我们的其中一台 Prometheus Server 为例,本地只保留了 2 个小时的数据,950,000 系列,大概占用的内存如下:
优化方案是什么:
Prometheus 内存使用分析:
相关问题:
Prometheus 容量规划
除了上面提到的内存,容量规划还包括磁盘存储规划,这和你的 Prometheus 架构有关。
Prometheus 每 2 小时将已经缓冲在内存中的数据压缩到磁盘上的块中。包括 Chunks、Indexes、Tombstones、Metadata,这些都占用了部分存储空间。一般来说,Prometheus 中存储的每个样本大约占用 1-2 个字节大小(1.7Byte)。您可以使用 Promql 查看每个样本平均占用多少空间:
"`重击
速率(prometheus_tsdb_compaction_chunk_size_bytes_sum[1h])
/
速率(prometheus_tsdb_compaction_chunk_samples_sum[1h])
{instance="0.0.0.0:8890", job="prometheus"} 1.252747585939941
"`
如果粗略估计本地磁盘的大小,可以使用以下公式:
磁盘大小 = 保留时间 * 每秒获取样本数 * 样本大小
在保留时间(retention_time_seconds)和样本大小(bytes_per_sample)不变的情况下,如果要降低本地磁盘的容量要求,只能降低每秒的样本数(ingested_samples_per_second)。
查看当前每秒采集的样本数:
rate(prometheus_tsdb_head_samples_appended_total[1h])
有两种手段,一种是减少时间序列的数量,另一种是增加采集个样本的时间间隔。考虑到 Prometheus 压缩了时间序列,减少时间序列数量的效果更加明显。
例如:
以上磁盘容量不包括wal文件。wal文件(Raw Data)在Prometheus官方文档中说明至少会保存3个Write-Ahead Log Files,每个最大大小为128M(实际数量会更多)。
因为我们使用的是灭霸的方案,所以本地磁盘只保留2H热数据。Wal 每 2 小时生成一个块文件,每 2 小时将块文件上传到对象存储。本地磁盘基本没有压力。
对于 Prometheus 的存储机制,你可以阅读这个。
对 Apiserver 的性能影响
如果你的 Prometheus 使用 kubernetes_sd_config 进行服务发现,请求一般会通过集群的 Apiserver。随着规模的增加,您需要评估对 Apiserver 性能的影响,尤其是当 Proxy 发生故障时,会导致 CPU 增加。当然,如果单个 K8S 集群规模过大,一般会进行集群拆分,但还是需要随时监控 Apiserver 的进程变化。
在监控Cadvisor、Docker、Kube-Proxy的metrics时,我们最初选择Apiserver Proxy到节点的对应端口,统一设置比较方便,后来改成直接拉节点,Apiserver只做服务发现.
Rate的计算逻辑
Prometheus 中的 Counter 类型主要是针对 Rate 存在的,即计算速率。纯Counter计数意义不大,因为一旦Counter复位,总计数就没有意义了。
Rate 会自动处理 Counter 的重置,通常会不断变大。例如,Exporter 启动然后崩溃。最初以每秒约 10 的速率递增,但只运行半小时,rate(x_total[1h]) 将返回每秒约 5 的结果。此外,计数器的任何减少也被视为计数器重置。例如,如果时间序列的值为 [5,10,4,6],则将其视为 [5,10,14,16]。
费率值很少是准确的。由于不同目标的提取发生在不同的时间,抖动会随着时间的推移而发生,query_range 很少被计算为完全匹配提取时间,并且提取可能会失败。面对这样的挑战,Rate 的设计必须稳健。
Rate 不想捕获每个 delta,因为有时 delta 会丢失,例如实例在 fetch 间隔内死亡。如果 Counter 变化缓慢,比如每小时只增加几次,可能会导致 [artifacts]。例如,有一个值为 100 的 Counter 时间序列,Rate 不知道这些增量是否是当前值,或者目标是否已经运行了几年并且刚刚开始返回。
建议将 Rate 计算的范围向量的时间设置为至少 4 倍的 fetch 间隔。这将确保即使爬行缓慢和爬行失败,您也始终有两个可用的样本。此类问题在实践中经常出现,因此保持这种弹性很重要。例如,对于 1 分钟的爬网间隔,您可以使用 4 分钟的速率计算,但这通常四舍五入为 5 分钟。
如果Rate的时间区间有缺失数据,他会根据趋势做出推断,比如:
有关详细信息,请参阅此视频
违反直觉的 P95 统计数据
histogram_quantile 是 Prometheus 常用的一个函数,例如,一个服务的 P95 响应时间经常被用来衡量服务质量。但是,具体是什么意思很难解释,尤其是对非技术类的学生来说,会遭遇很多“灵魂拷问”。
我们常说的P95(P99,P90都可以)的响应延迟是100ms,其实就是说在所有采集到的响应延迟中,有5%的请求大于100ms,95%的请求小于100ms . Prometheus中的histogram_quantile函数接收一个0-1之间的小数,小数乘以100就可以很方便的得到对应的百分位数。比如0.95对应P95,也可以是更高的百分位精度,例如 0.9999。
当您使用 histogram_quantile 绘制响应时间趋势时,您可能会被问到:为什么 P95 大于或小于我的平均值?
正如中位数可能大于或小于平均值一样,P99 完全有可能小于平均值。通常 P99 几乎总是大于平均值,但如果数据分布极端,前 1% 可能会大到推高平均值。一个可能的例子:
1, 1, ... 1, 901 // 共 100 条数据,平均值=10,P99=1
服务X分两步完成,A和B,其中X的P99耗时100Ms,A进程的P99耗时50Ms。那么B流程的P99的预估时间是多少呢?
直觉上,既然X=A+B,答案大概是50Ms,或者至少应该小于50Ms。实际上,B可以大于50Ms。只要 A 和 B 中最大的 1% 不碰巧相遇,B 就可以有一个非常大的 P99:
A = 1, 1, ... 1, 1, 1, 50, 50 // 共 100 条数据,P99=50
B = 1, 1, ... 1, 1, 1, 99, 99 // 共 100 条数据,P99=99
X = 2, 2, ... 1, 51, 51, 100, 100 // 共 100 条数据,P99=100
如果让 A 过程最大的 1% 接近 100Ms,我们也能构造出 P99 很小的 B:
A = 50, 50, ... 50, 50, 99 // 共 100 条数据,P99=50
B = 1, 1, ... 1, 1, 50 // 共 100 条数据,P99=1
X = 51, 51, ... 51, 100, 100 // 共 100 条数据,P99=100
所以,我们从标题中唯一能确定的就是B的P99不应该超过100ms,而A的P99取50Ms的条件其实是没有用的。
类似的问题还有很多,所以对于 histogram_quantile 函数,可能会产生一些反直觉的结果。最好的处理方式就是不断调整你的 Bucket 的值,保证更多的请求次数落入更详细的范围内,这样请求时间在统计上是显着的。
查询慢问题
Promql 的基础见这个 文章
Prometheus 提供了一个自定义 Promql 作为查询语句。在Graph上调试的时候会告诉你这个Sql的返回时间。如果太慢,请注意,可能是您的使用有问题。
要评估 Prometheus 的整体响应时间,您可以使用以下默认指标:
prometheus_engine_query_duration_seconds{}
一般情况下,响应慢的原因是Promql使用不当,或者指标规划有问题,比如:
基数
高基数是数据库无法回避的话题。对于像 Mysql 这样的 DB,基数是指特定列或字段中收录的唯一值的数量。基数越低,列中重复的元素就越多。对于时间序列数据库,是标签、标签等标签值的个数。
例如,如果 Prometheus 中有一个指标 http_request_count{method="get",path="/abc",originIP="1.1.1.1"},则表示访问次数,method表示请求方法,originIP是客户端IP,method的枚举值是有限的,而originIP是无限的,再加上其他标签的排列组合是无限的,没有关联的特征,所以这种高基数不适合作为 Metric 标签,如果真的要提取 originIP,应该使用 log 的方式,而不是 Metric 监控
时间序列数据库对这些标签进行索引以提高查询性能,以便您可以快速找到与所有指定标签匹配的值。如果值的个数太大,索引就没有意义了,尤其是在做P95等计算的时候,需要扫描大量的Series数据
官方文档中对 Label 的建议
CAUTION: Remember that every unique combination of key-value label pairs represents a new time series, which can dramatically increase the amount of data stored. Do not use labels to store dimensions with high cardinality (many different label values), such as user IDs, email addresses, or other unbounded sets of values.
如何查看当前的Label分布,可以使用Prometheus提供的Tsdb工具。可以使用命令行查看,也可以在2.16版本以上的Prometheus Graph中查看
[work@xxx bin]$ ./tsdb analyze ../data/prometheus/
Block ID: 01E41588AJNGM31SPGHYA3XSXG
Duration: 2h0m0s
Series: 955372
Label names: 301
Postings (unique label pairs): 30757
Postings entries (total label pairs): 10842822
....
top10 高基数指标
Highest cardinality metric names:
87176 apiserver_request_latencies_bucket
59968 apiserver_response_sizes_bucket
39862 apiserver_request_duration_seconds_bucket
37555 container_tasks_state
....
高基数标签
Highest cardinality labels:
4271 resource_version
3670 id
3414 name
1857 container_id
1824 __name__
1297 uid
1276 pod
...
找到最大的指标或工作
top10 中的指标数量:按指标名称
topk(10, count by (__name__)({__name__=~".+"}))
apiserver_request_latencies_bucket{} 62544
apiserver_response_sizes_bucket{} 44600
top10中的metrics个数:按job name
topk(10, count by (__name__, job)({__name__=~".+"}))
{job="master-scrape"} 525667
{job="xxx-kubernetes-cadvisor"} 50817
{job="yyy-kubernetes-cadvisor"} 44261
Prometheus 重启慢且热重载
当 Prometheus 重启时,需要将 Wal 的内容加载到内存中。保留时间越长,Wal文件越大,实际重启的时间越长。这是普罗米修斯的机制,没有办法做到。因此,如果可以Reload,就不要重启,必须重启。会导致短期不可用,此时Prometheus的高可用就很重要了。
Prometheus 还优化了启动时间。在 2.6 版本中,优化了 Wal 的加载速度。我希望重启时间不会超过1分钟。
Prometheus 提供热加载能力,但需要启用 web.enable-lifecycle 配置。更改配置后,可以点击curl下的reload界面。默认情况下更改 prometheus-operator 中的配置将触发重新加载。如果你不使用算子,又想监控 configmap 配置变化来重新加载服务,可以试试这个简单的脚本
#!/bin/sh
FILE=$1
URL=$2
HASH=$(md5sum $(readlink -f $FILE))
while true; do
NEW_HASH=$(md5sum $(readlink -f $FILE))
if [ "$HASH" != "$NEW_HASH" ]; then
HASH="$NEW_HASH"
echo "[$(date +%s)] Trigger refresh"
curl -sSL -X POST "$2" > /dev/null
fi
sleep 5
done
使用时挂载和prometheus一样的configmap,传入如下参数:
args:
- /etc/prometheus/prometheus.yml
- http://prometheus.kube-system.svc.cluster.local:9090/-/reload
args:
- /etc/alertmanager/alertmanager.yml
- http://prometheus.kube-system.svc.cluster.local:9093/-/reload
您的应用需要公开多少指标
自己开发服务的时候,可能会暴露一些数据给metrics,比如具体请求的数量,goroutines的数量等等,多少metrics比较合适呢?
虽然指标的数量与您的应用程序的大小有关,但有一些建议(Brian Brazil),
比如缓存等简单的服务,类似于Pushgateway,有120个左右的指标。Prometheus 本身公开了大约 700 个指标。如果您的应用程序很大,请尽量不要超过 10,000 个指标。您需要合理控制您的标签。
node-exporter node-exporter不支持进程监控的问题,前面已经讲过了。node-exporter 只支持 unix 系统,windows 机器请使用 wmi_exporter。因此,当yaml形式不是node-exporter时,node-selector应该指明os类型。因为node_exporter是老组件,有一些最佳实践没有合并,比如符合Prometheus命名约定,所以推荐使用较新的0.16和0.17版本。
一些指标名称更改:
* node_cpu -> node_cpu_seconds_total
* node_memory_MemTotal -> node_memory_MemTotal_bytes
* node_memory_MemFree -> node_memory_MemFree_bytes
* node_filesystem_avail -> node_filesystem_avail_bytes
* node_filesystem_size -> node_filesystem_size_bytes
* node_disk_io_time_ms -> node_disk_io_time_seconds_total
* node_disk_reads_completed -> node_disk_reads_completed_total
* node_disk_sectors_written -> node_disk_written_bytes_total
* node_time -> node_time_seconds
* node_boot_time -> node_boot_time_seconds
* node_intr -> node_intr_total
如果之前使用过旧版本的exporter,绘制grafana时指标名称会有所不同。有两种解决方案:
kube-state-metric 的问题
kube-state-metric的使用和原理可以先阅读
除了文章中提到的功能,kube-state-metric还有一个很重要的使用场景,就是结合cadvisor metrics。原来的cadvisor只有pod信息,不知道属于哪个deployment或者sts,但是用kube-state-metric中的kube_pod_info可以在join查询后显示。kube-state-metric 的元数据索引在扩展 cadvisor 的标签方面起到了很大的作用。prometheus-operator 的许多记录规则使用 kube-state-metric 进行组合查询。
Pod 的标签信息也可以在 kube-state-metric 中展示,这样可以在获取 cadvisor 数据后进行分组更方便,比如根据 Pod 的运行环境进行分类。但是,kube-state-metric 不会暴露 pod 的注释。原因是下面提到的高基数问题,即注解的内容太多,不适合作为指标暴露。
relabel_configs 和 metric_relabel_configs
relabel_config 出现在 采集 之前,metric_relabel_configs 出现在 采集 之后。合理的组合可以满足很多场景的配置。
喜欢:
metric_relabel_configs:
- separator: ;
regex: instance
replacement: $1
action: labeldrop
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_endpoints_name,
__meta_kubernetes_service_annotation_prometheus_io_port]
separator: ;
regex: (.+);(.+);(.*)
target_label: __metrics_path__
replacement: /api/v1/namespaces/${1}/services/${2}:${3}/proxy/metrics
action: replace
Prometheus 的预测能力
场景一:你的磁盘剩余空间一直在减少,减少的幅度比较均匀。您想知道达到阈值需要多长时间,并且您想在某个时刻发出警报。
场景二:你的 Pod 的内存使用量一直在增加,你想知道需要多长时间才能达到 Limit 值,并在某个时间报警,并在被杀死之前检查。
Prometheus 的 Deriv 和 Predict_Linear 方法可以满足这样的需求。Promtheus 提供基本的预测能力,根据当前的变化率,推断一段时间后的值。
以 mem_free 为例,最近一小时 free 值一直在下降。
mem_free仅为举例,实际内存可用以mem_available为准
deriv 函数可以显示一段时间内指标的变化率:
predict_linear 方法就是根据这个速度来预测最终可达到的值:
predict_linear(mem_free{instanceIP="100.75.155.55"}[1h], 2*3600)/1024/1024
您可以根据设置设置合理的报警规则,例如小于10时报警:
<p>rule: predict_linear(mem_free{instanceIP="100.75.155.55"}[1h], 2*3600)/1024/1024
0 个评论
官方客服QQ群
在
线
客
服
这里的__meta_kubernetes_service_annotation_prometheus_io_port的来源是部署exporter时写的注解。大多数 文章 只提到 prometheus.io/scrape: 'true',但它也可以定义端口、路径和协议。为了方便采集时的替换处理。
其他一些relabels比如kubernetes_namespace是为了保留原创信息,方便做promql查询时的过滤条件。
如果是多集群,可以多次编写相同的配置。一般来说,一个集群可以配置三种类型的作业:
获取 GPU 指标
nvidia-smi 可以查看机器上的 GPU 资源,而 Cadvisor 实际上暴露了 Metrics 来指示容器的 GPU 使用情况。
container_accelerator_duty_cycle
container_accelerator_memory_total_bytes
container_accelerator_memory_used_bytes
如果想要更详细的 GPU 数据,可以安装 dcgm exporter,但 K8S 1.13 只能支持。
更改 Prometheus 的显示时区
为了避免时区混淆,Prometheus 使用 Unix Time 和 Utc 专门用于在所有组件中显示。不支持在配置文件中设置时区,也无法读取原生的/etc/timezone时区。
事实上,这个限制并不影响使用:
有关时区的讨论,请参阅此问题。
如何采集 LB 后面的 RS 度量
如果你有负载均衡LB,但是网络上的Prometheus只能访问LB本身,不能访问后续的RS,采集RS应该如何暴露metrics呢?
版本选择
Prometheus当前最新版本是2.16,Prometheus还在迭代中,所以尽量使用最新版本,1.X版本不是必须的。
2.16版本有一套实验UI,可以查看TSDB的状态,包括Top 10 Label、Metric。
Prometheus 大内存问题
随着规模变大,Prometheus 所需的 CPU 和内存都会增加,内存一般会先达到瓶颈。这里我们先讨论一下*敏*感*词*Prometheus的内存问题。
原因:
我的指标需要多少内存:
以我们的其中一台 Prometheus Server 为例,本地只保留了 2 个小时的数据,950,000 系列,大概占用的内存如下:
优化方案是什么:
Prometheus 内存使用分析:
相关问题:
Prometheus 容量规划
除了上面提到的内存,容量规划还包括磁盘存储规划,这和你的 Prometheus 架构有关。
Prometheus 每 2 小时将已经缓冲在内存中的数据压缩到磁盘上的块中。包括 Chunks、Indexes、Tombstones、Metadata,这些都占用了部分存储空间。一般来说,Prometheus 中存储的每个样本大约占用 1-2 个字节大小(1.7Byte)。您可以使用 Promql 查看每个样本平均占用多少空间:
"`重击
速率(prometheus_tsdb_compaction_chunk_size_bytes_sum[1h])
/
速率(prometheus_tsdb_compaction_chunk_samples_sum[1h])
{instance="0.0.0.0:8890", job="prometheus"} 1.252747585939941
"`
如果粗略估计本地磁盘的大小,可以使用以下公式:
磁盘大小 = 保留时间 * 每秒获取样本数 * 样本大小
在保留时间(retention_time_seconds)和样本大小(bytes_per_sample)不变的情况下,如果要降低本地磁盘的容量要求,只能降低每秒的样本数(ingested_samples_per_second)。
查看当前每秒采集的样本数:
rate(prometheus_tsdb_head_samples_appended_total[1h])
有两种手段,一种是减少时间序列的数量,另一种是增加采集个样本的时间间隔。考虑到 Prometheus 压缩了时间序列,减少时间序列数量的效果更加明显。
例如:
以上磁盘容量不包括wal文件。wal文件(Raw Data)在Prometheus官方文档中说明至少会保存3个Write-Ahead Log Files,每个最大大小为128M(实际数量会更多)。
因为我们使用的是灭霸的方案,所以本地磁盘只保留2H热数据。Wal 每 2 小时生成一个块文件,每 2 小时将块文件上传到对象存储。本地磁盘基本没有压力。
对于 Prometheus 的存储机制,你可以阅读这个。
对 Apiserver 的性能影响
如果你的 Prometheus 使用 kubernetes_sd_config 进行服务发现,请求一般会通过集群的 Apiserver。随着规模的增加,您需要评估对 Apiserver 性能的影响,尤其是当 Proxy 发生故障时,会导致 CPU 增加。当然,如果单个 K8S 集群规模过大,一般会进行集群拆分,但还是需要随时监控 Apiserver 的进程变化。
在监控Cadvisor、Docker、Kube-Proxy的metrics时,我们最初选择Apiserver Proxy到节点的对应端口,统一设置比较方便,后来改成直接拉节点,Apiserver只做服务发现.
Rate的计算逻辑
Prometheus 中的 Counter 类型主要是针对 Rate 存在的,即计算速率。纯Counter计数意义不大,因为一旦Counter复位,总计数就没有意义了。
Rate 会自动处理 Counter 的重置,通常会不断变大。例如,Exporter 启动然后崩溃。最初以每秒约 10 的速率递增,但只运行半小时,rate(x_total[1h]) 将返回每秒约 5 的结果。此外,计数器的任何减少也被视为计数器重置。例如,如果时间序列的值为 [5,10,4,6],则将其视为 [5,10,14,16]。
费率值很少是准确的。由于不同目标的提取发生在不同的时间,抖动会随着时间的推移而发生,query_range 很少被计算为完全匹配提取时间,并且提取可能会失败。面对这样的挑战,Rate 的设计必须稳健。
Rate 不想捕获每个 delta,因为有时 delta 会丢失,例如实例在 fetch 间隔内死亡。如果 Counter 变化缓慢,比如每小时只增加几次,可能会导致 [artifacts]。例如,有一个值为 100 的 Counter 时间序列,Rate 不知道这些增量是否是当前值,或者目标是否已经运行了几年并且刚刚开始返回。
建议将 Rate 计算的范围向量的时间设置为至少 4 倍的 fetch 间隔。这将确保即使爬行缓慢和爬行失败,您也始终有两个可用的样本。此类问题在实践中经常出现,因此保持这种弹性很重要。例如,对于 1 分钟的爬网间隔,您可以使用 4 分钟的速率计算,但这通常四舍五入为 5 分钟。
如果Rate的时间区间有缺失数据,他会根据趋势做出推断,比如:
有关详细信息,请参阅此视频
违反直觉的 P95 统计数据
histogram_quantile 是 Prometheus 常用的一个函数,例如,一个服务的 P95 响应时间经常被用来衡量服务质量。但是,具体是什么意思很难解释,尤其是对非技术类的学生来说,会遭遇很多“灵魂拷问”。
我们常说的P95(P99,P90都可以)的响应延迟是100ms,其实就是说在所有采集到的响应延迟中,有5%的请求大于100ms,95%的请求小于100ms . Prometheus中的histogram_quantile函数接收一个0-1之间的小数,小数乘以100就可以很方便的得到对应的百分位数。比如0.95对应P95,也可以是更高的百分位精度,例如 0.9999。
当您使用 histogram_quantile 绘制响应时间趋势时,您可能会被问到:为什么 P95 大于或小于我的平均值?
正如中位数可能大于或小于平均值一样,P99 完全有可能小于平均值。通常 P99 几乎总是大于平均值,但如果数据分布极端,前 1% 可能会大到推高平均值。一个可能的例子:
1, 1, ... 1, 901 // 共 100 条数据,平均值=10,P99=1
服务X分两步完成,A和B,其中X的P99耗时100Ms,A进程的P99耗时50Ms。那么B流程的P99的预估时间是多少呢?
直觉上,既然X=A+B,答案大概是50Ms,或者至少应该小于50Ms。实际上,B可以大于50Ms。只要 A 和 B 中最大的 1% 不碰巧相遇,B 就可以有一个非常大的 P99:
A = 1, 1, ... 1, 1, 1, 50, 50 // 共 100 条数据,P99=50
B = 1, 1, ... 1, 1, 1, 99, 99 // 共 100 条数据,P99=99
X = 2, 2, ... 1, 51, 51, 100, 100 // 共 100 条数据,P99=100
如果让 A 过程最大的 1% 接近 100Ms,我们也能构造出 P99 很小的 B:
A = 50, 50, ... 50, 50, 99 // 共 100 条数据,P99=50
B = 1, 1, ... 1, 1, 50 // 共 100 条数据,P99=1
X = 51, 51, ... 51, 100, 100 // 共 100 条数据,P99=100
所以,我们从标题中唯一能确定的就是B的P99不应该超过100ms,而A的P99取50Ms的条件其实是没有用的。
类似的问题还有很多,所以对于 histogram_quantile 函数,可能会产生一些反直觉的结果。最好的处理方式就是不断调整你的 Bucket 的值,保证更多的请求次数落入更详细的范围内,这样请求时间在统计上是显着的。
查询慢问题
Promql 的基础见这个 文章
Prometheus 提供了一个自定义 Promql 作为查询语句。在Graph上调试的时候会告诉你这个Sql的返回时间。如果太慢,请注意,可能是您的使用有问题。
要评估 Prometheus 的整体响应时间,您可以使用以下默认指标:
prometheus_engine_query_duration_seconds{}
一般情况下,响应慢的原因是Promql使用不当,或者指标规划有问题,比如:
基数
高基数是数据库无法回避的话题。对于像 Mysql 这样的 DB,基数是指特定列或字段中收录的唯一值的数量。基数越低,列中重复的元素就越多。对于时间序列数据库,是标签、标签等标签值的个数。
例如,如果 Prometheus 中有一个指标 http_request_count{method="get",path="/abc",originIP="1.1.1.1"},则表示访问次数,method表示请求方法,originIP是客户端IP,method的枚举值是有限的,而originIP是无限的,再加上其他标签的排列组合是无限的,没有关联的特征,所以这种高基数不适合作为 Metric 标签,如果真的要提取 originIP,应该使用 log 的方式,而不是 Metric 监控
时间序列数据库对这些标签进行索引以提高查询性能,以便您可以快速找到与所有指定标签匹配的值。如果值的个数太大,索引就没有意义了,尤其是在做P95等计算的时候,需要扫描大量的Series数据
官方文档中对 Label 的建议
CAUTION: Remember that every unique combination of key-value label pairs represents a new time series, which can dramatically increase the amount of data stored. Do not use labels to store dimensions with high cardinality (many different label values), such as user IDs, email addresses, or other unbounded sets of values.
如何查看当前的Label分布,可以使用Prometheus提供的Tsdb工具。可以使用命令行查看,也可以在2.16版本以上的Prometheus Graph中查看
[work@xxx bin]$ ./tsdb analyze ../data/prometheus/
Block ID: 01E41588AJNGM31SPGHYA3XSXG
Duration: 2h0m0s
Series: 955372
Label names: 301
Postings (unique label pairs): 30757
Postings entries (total label pairs): 10842822
....
top10 高基数指标
Highest cardinality metric names:
87176 apiserver_request_latencies_bucket
59968 apiserver_response_sizes_bucket
39862 apiserver_request_duration_seconds_bucket
37555 container_tasks_state
....
高基数标签
Highest cardinality labels:
4271 resource_version
3670 id
3414 name
1857 container_id
1824 __name__
1297 uid
1276 pod
...
找到最大的指标或工作
top10 中的指标数量:按指标名称
topk(10, count by (__name__)({__name__=~".+"}))
apiserver_request_latencies_bucket{} 62544
apiserver_response_sizes_bucket{} 44600
top10中的metrics个数:按job name
topk(10, count by (__name__, job)({__name__=~".+"}))
{job="master-scrape"} 525667
{job="xxx-kubernetes-cadvisor"} 50817
{job="yyy-kubernetes-cadvisor"} 44261
Prometheus 重启慢且热重载
当 Prometheus 重启时,需要将 Wal 的内容加载到内存中。保留时间越长,Wal文件越大,实际重启的时间越长。这是普罗米修斯的机制,没有办法做到。因此,如果可以Reload,就不要重启,必须重启。会导致短期不可用,此时Prometheus的高可用就很重要了。
Prometheus 还优化了启动时间。在 2.6 版本中,优化了 Wal 的加载速度。我希望重启时间不会超过1分钟。
Prometheus 提供热加载能力,但需要启用 web.enable-lifecycle 配置。更改配置后,可以点击curl下的reload界面。默认情况下更改 prometheus-operator 中的配置将触发重新加载。如果你不使用算子,又想监控 configmap 配置变化来重新加载服务,可以试试这个简单的脚本
#!/bin/sh
FILE=
URL=
逆天:黑帽seo快速排名(单页seo快速排名)
优采云 发布时间: 2022-10-02 18:15逆天:黑帽seo快速排名(单页seo快速排名)
新手如何使用WordPress 伪原创插件快速创建原创内容,快速获取网站收录和排名关键词?新手 SEO 应该怎么做?快速开始。
从新手到高手,坚持排名优化很重要。很多新手在做SEO的时候总是会陷入误区。其实他们心里是很想学seo的,但是因为不懂seo这个行业,所以走在新手的路上越来越难了。大多数新手在刚接触 seo 行业时总是不耐烦。经过几天的SEO,我开始不耐烦了。为什么它不起作用?然后他们去找各种seo老手。一般做seo的资深人士会耐心回答等等。这还早了一个月,但这是真的。这时,新手会开始感到迷茫和不知所措。那么,让我们来看看新手不擅长SEO的原因。
我不知道从哪里开始。
有很多新手对seo还是很感兴趣的,只是不知道从哪里开始,不知道怎么入手,也不知道怎么理解它的技术点。所以在这种情况下,我建议先百度一下,对seo这个行业有一个大概的了解,然后再学一些编程语言,就不用知道学编程语言有多难了。只要学过基本的HTML语言和PHP/ASP/JAVA等一些简单的编程语言,还必须学习数据分析,这是一个很重要的课题。网站 优化的质量取决于数据分析后定制执行方法的有效性。
在大部分学习者看来,所谓的SEO就是把想要的关键词优化到首页,但真正的SEO是搜索引擎优化,而不是搜索排名优化。正是因为排名被视为SEO的整体,所以没有人整天关心排名,导致很多人半途而废。总之,您对 SEO 的了解程度取决于您可以在 SEO 中走多远。
二、缺乏毅力
由于seo是一项长期有效的工作,所以大部分放弃seo的新手都是因为坚持不了。在做了几天没有效果之后,他们总是感到受到打击。但实际上,这不仅是新手如此,老手也是如此。所有从事seo多年的人都有耐心。如果你没有耐心,无论你多么熟练,你都无法完成这项工作。但不是没有优化一下子就能看到效果,但不是优化,是作弊。黑帽seo也可以在短时间内看到效果,但是想要在一个好的关键词排名中实现长期稳定,黑帽seo做不到,所以一定要坚持,否则不会能够去。新手的方法。
第三,WordPress 伪原创 插件快速创建原创 内容并不断更新网站。
要创建大量 原创 内容,首先需要大量 文章 素材。批量创作原创内容的过程是(采集行业相关的文章-处理伪原创-通过WordPress中的SEO能力提高页面原创性能伪原创插件) - 主动推送到主要搜索引擎)。在这个WordPress伪原创插件中我们不需要学习更多的专业技能,只需几个简单的步骤就可以轻松采集内容数据。用户只需要在 WordPress 伪原创 插件上进行简单的设置。完成后,WordPress 伪原创插件会根据用户设置的关键词采集高精度的内容和图片。可以保存在本地,也可以伪原创发布,提供方便快捷的内容采集和伪原创 出版服务!!
与其他WordPress伪原创插件相比,这个WordPress伪原创插件基本没有门槛,不需要花很多时间学习正则表达式或者html标签。一分钟后即可使用,只需输入 关键词 即可添加书签(WordPress 伪原创 插件还带有 关键词 书签功能)。一路挂断!将任务设置为自动化 采集pseudo-raw 发布推送任务。(支持本地采集和手动修改)
无论你有成百上千个不同的cms网站,都可以实现统一管理。一个人维护数百个网站文章更新不是问题。这个皇家伪原创插件还配备了很多SEO功能,通过软件采集伪原创的发布的同时可以提升很多SEO优化。
比如网站主动推送(让搜索引擎更快找到我们的网站),自动匹配图片(如果文章里面没有图片,会自动配置相关图片)。设置为自动下载图片并保存在本地或第三方(使内容不存在于对方外链)。自动链接(让搜索引擎更深入地抓取你的链接),前后插入内容或标题,插入网站内容或随机作者,随机阅读等,形成“高度原创”。定期发布(定期发布文章,以便搜索引擎及时抓取您的网站内容)
这些小的 SEO 功能不仅提高了 网站 页面的 原创 性能,还间接提高了 网站 的排名。您可以直接监控管理软件工具,查看文章的收录发布和百度推送,无需每天登录网站后台。目前博主亲测软件是免费的,可以直接下载使用!
首先,给自己设定一个合理的学习时间框架。
你为什么这么说?这真的很容易。一切都必须有计划和有针对性。如果没有,最简单的事情也可以无限扩展。给自己一个最后期限是很重要的,比如两三个月。说说我自己吧。我属于励志青年。
后面两个月的学习时间有限,大概需要三个月的时间来学习上手。给自己一个截止日期是合理的。为什么要讲道理?这是因为许多学生的理解能力不同。如果讲摊位的价格,你两三个月就学会了,他们两三个月就停止学习了。
很容易产生失败感而放弃学习。有的可能需要半年,有的可能一个月就学会了。当然,这是在某人的指导下。目前,一年的效果普遍不理想。
其次,你自己必须有一个网站。
很多同学想做SEO,但是没有网站。没有网站,他们就无法练习。就像我过去学的CAD一样,他们基本上一两年就忘记了。所以如果他们只学习理论而不实践和应用,他们很快就会忘记。经验是积累的。
第三,不要做你做不到的事情网站。
不能做的事不做是什么意思?指一些你很难做到的网站,因为你作为锁泉站长,没有那么多的资金和资源去做推广和营销,有些网站不适合优化,还是需要资源做的,个人不推荐。
比如,kiosk厂商不应该做团购导航或者美谈之类的分享社区,因为很难做到。类似于我自己开发的软件,功能齐全,游戏、IP变更、外贸等。相当于做起来更轻松。
第四,学会养成数据分析的习惯。
如果一个SEO从业者不分析数据,他基本上就不是一个合格的SEOER。养成数据分析的习惯,每天了解网站的数据,比如IIS日志、页面收录、页面点击、实时访问、百度PV、UV、IP等数据统计数据。
这些数据可以反映你的一些网站情况,是否有异常等等。有时候你的网站出了问题,你也不知道怎么回事。
第五,继续研究一些官方的文章搜索引擎。
不是每个人都非常擅长搜索引擎。他们对搜索引擎了解不多,只能积累。百度和谷歌目前都有可以与网站管理员交流的社区。我的建议是多去这些地方活动,可以看到很多有用的知识。也推荐阅读百度和谷歌的空优化指南。
根据你对SEO的理解,层次不同,同一件事在不同时期可以有不同的理解,会有不同的收获。看一遍有收获,再看一遍有收获。
看完这篇文章,如果觉得不错,不妨留着,或者发给需要的朋友同事。关注博主,每天带您体验各种 SEO 体验,完成您的约会!
给力:高可用 Prometheus:问题集锦【转】
2021-06-30
监控系统历史悠久,是一个非常成熟的方向,而Prometheus作为新一代的开源监控系统,已经逐渐成为云原生系统的事实标准,这也证明了它的设计很受欢迎. 本文主要分享Prometheus在实践中遇到的一些问题和思考。如果你对 K8S 监控系统或者 Prometheus 的设计不是很了解,可以先看看容器监控系列。
几个原则 Prometheus 限制 K8S 集群中常用的 exporter
Prometheus 是一个 CNCF 项目,拥有完整的开源生态系统。与Zabbix等传统代理监控不同,它提供了丰富的exporter来满足你的各种需求。您可以在此处查看官方和非官方出口商。如果还是不能满足你的需求,你也可以自己写一个exporter,简单方便,完全开放,这是一个优势。
但是,过于开放会带来选择和试错的成本。以前只需在 zabbix 代理中进行几行配置即可完成的工作,现在您将需要大量的导出器来完成它。还维护和监控所有出口商。尤其是升级exporter版本的时候,很痛苦。非官方的exporter会有很多bug。这是一个用处,当然也是Prometheus的设计原则。
K8S 生态系统的组件将提供 /metric 接口以提供自我监控。以下是我们正在使用的:
还有各种场景下的自定义导出器,比如日志提取,后面会介绍。
K8S核心组件监控和Grafana面板
k8s集群运行过程中,需要关注核心组件的状态和性能。比如kubelet、apiserver等,根据上面提到的exporter指标,可以在Grafana中绘制如下图表:
模板可以参考dashboards-for-kubernetes-administrators,根据运行情况不断调整告警阈值。
这里提到,虽然Grafana支持模板能力,可以方便的进行多级下拉框选择,但不支持模板模式下配置告警规则。相关问题
官方解释了很多这个功能,但是最新的版本还是不支持。从 issue 中借用一句话吐出:
It would be grate to add templates support in alerts. Otherwise the feature looks useless a bit.
Grafana的基本用法可以看这个文章
采集组件多合一
Prometheus 系统中的 Exporter 是独立的,每个组件都各司其职,例如 Node-Exporter 用于机器资源,Nvidia Exporter 用于 Gpu 等。但是Exporters越多,运维压力就越大,尤其是Agent的资源控制和版本升级。我们尝试结合一些Exporters,有两种解决方案:
通过主进程拉起 N 个 Exporter 进程,您仍然可以关注社区版本的更新和错误修复。使用 Telegraf 支持各种类型的 Input,N in 1。
此外,Node-Exporter 不支持进程监控。可以添加一个Process-Exporter,也可以使用上面提到的Telegraf 来使用procstat 的输入到采集process 指标。
黄金指标的合理选择
采集的指标很多,我们应该关注哪些呢?Google 在《Sre 手册》中提出了“四个黄金信号”:延迟、流量、错误数和饱和度。在实践中,您可以使用 Use 或 Red 方法作为指导,Use 用于资源,Red 用于服务。
Prometheus 采集 中共有三个常用服务:
在线服务:如Web服务、数据库等,一般关注请求率、延迟和错误率即RED方法离线服务:如日志处理、消息队列等,一般关注队列数、正在进行的数量、处理速度和出现的错误 使用方法 批处理任务:类似于离线任务,但离线任务是长时间运行的,批处理任务是按计划运行的,比如持续集成就是批处理任务,对应job或者K8S中的cronjob,一般要注意开销时间、错误次数等,因为运行周期短,很有可能在采集到来之前运行就结束了,所以一般使用pushgateway,并将拉改为推。
Use和Red的实例请参考容器监控实践-K8S常用指标分析文章。
K8S中Cadvisor的指标兼容性问题1.16
在 K8S 1.16 版本中,Cadvisor 指标移除了 pod_Name 和 container_name 的标签,并将它们替换为 pod 和 container。如果之前使用这两个标签进行查询或Grafana绘图,则需要更改Sql。因为我们一直支持多个 K8S 版本,所以我们通过 relabel 配置继续保留原来的 **_name。
metric_relabel_configs:
- source_labels: [container]
regex: (.+)
target_label: container_name
replacement: $1
action: replace
- source_labels: [pod]
regex: (.+)
target_label: pod_name
replacement: $1
action: replace
注意使用metric_relabel_configs,而不是relabel_configs,替换在采集之后。
Prometheus 采集外接K8S集群,多集群
如果Prometheus部署在K8S集群采集,使用官方的Yaml很方便,但是因为权限和网络的关系,我们需要部署在集群外,二进制操作,采集多个K8S集群.
Pod模式在集群中运行不需要证书(In-Cluster模式),但需要在集群外声明一个token等证书,并替换地址,即使用Apiserver Proxy采集 ,以Cadvisor采集为例,Job配置为:
- job_name: cluster-cadvisor
honor_timestamps: true
scrape_interval: 30s
scrape_timeout: 10s
metrics_path: /metrics
scheme: https
kubernetes_sd_configs:
- api_server: https://xx:6443
role: node
bearer_token_file: token/cluster.token
tls_config:
insecure_skip_verify: true
bearer_token_file: token/cluster.token
tls_config:
insecure_skip_verify: true
relabel_configs:
- separator: ;
regex: __meta_kubernetes_node_label_(.+)
replacement: $1
action: labelmap
- separator: ;
regex: (.*)
target_label: __address__
replacement: xx:6443
action: replace
- source_labels: [__meta_kubernetes_node_name]
separator: ;
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
action: replace
metric_relabel_configs:
- source_labels: [container]
separator: ;
regex: (.+)
target_label: container_name
replacement: $1
action: replace
- source_labels: [pod]
separator: ;
regex: (.+)
target_label: pod_name
replacement: $1
action: replace
Bearer_token_file 需要提前生成,这个可以参考官方文档。记住base64解码。
对于cadvisor,可以将__metrics_path__转换为/api/v1/nodes/${1}/proxy/metrics/cadvisor,代表Apiserver代理到Kubelet,如果网络可以通,也可以直接使用Kubelet的10255作为目标,可以直接写成:${1}:10255/metrics/cadvisor,意思是直接请求Kubelet,在规模大的时候减轻Apiserver的压力,即使用Apiserver进行服务发现,采集Apiserver 未使用
因为cadvisor暴露了主机端口,所以配置比较简单。如果是kube-state-metric之类的Deployment,是以endpoint的形式暴露出来的,写法应该是:
- job_name: cluster-service-endpoints
honor_timestamps: true
scrape_interval: 30s
scrape_timeout: 10s
metrics_path: /metrics
scheme: https
kubernetes_sd_configs:
- api_server: https://xxx:6443
role: endpoints
bearer_token_file: token/cluster.token
tls_config:
insecure_skip_verify: true
bearer_token_file: token/cluster.token
tls_config:
insecure_skip_verify: true
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
separator: ;
regex: "true"
replacement: $1
action: keep
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
separator: ;
regex: (https?)
target_label: __scheme__
replacement: $1
action: replace
- separator: ;
regex: (.*)
target_label: __address__
replacement: xxx:6443
action: replace
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_endpoints_name,
__meta_kubernetes_service_annotation_prometheus_io_port]
separator: ;
regex: (.+);(.+);(.*)
target_label: __metrics_path__
replacement: /api/v1/namespaces/${1}/services/${2}:${3}/proxy/metrics
action: replace
- separator: ;
regex: __meta_kubernetes_service_label_(.+)
replacement: $1
action: labelmap
- source_labels: [__meta_kubernetes_namespace]
separator: ;
regex: (.*)
<p>
target_label: kubernetes_namespace
replacement: $1
action: replace
- source_labels: [__meta_kubernetes_service_name]
separator: ;
regex: (.*)
target_label: kubernetes_name
replacement: $1
action: replace
</p>
对于端点类型,需要将__metrics_path__转换为/api/v1/namespaces/${1}/services/${2}:${3}/proxy/metrics,需要替换命名空间、svc名称端口、等等,这里的写法只适用于接口为/metrics的exporter。如果你的 exporter 不是 /metrics 接口,你需要替换这个路径。或者像我们一样将此地址用于统一约束。
这里的__meta_kubernetes_service_annotation_prometheus_io_port的来源是部署exporter时写的注解。大多数 文章 只提到 prometheus.io/scrape: 'true',但它也可以定义端口、路径和协议。为了方便采集时的替换处理。
其他一些relabels比如kubernetes_namespace是为了保留原创信息,方便做promql查询时的过滤条件。
如果是多集群,可以多次编写相同的配置。一般来说,一个集群可以配置三种类型的作业:
获取 GPU 指标
nvidia-smi 可以查看机器上的 GPU 资源,而 Cadvisor 实际上暴露了 Metrics 来指示容器的 GPU 使用情况。
container_accelerator_duty_cycle
container_accelerator_memory_total_bytes
container_accelerator_memory_used_bytes
如果想要更详细的 GPU 数据,可以安装 dcgm exporter,但 K8S 1.13 只能支持。
更改 Prometheus 的显示时区
为了避免时区混淆,Prometheus 使用 Unix Time 和 Utc 专门用于在所有组件中显示。不支持在配置文件中设置时区,也无法读取原生的/etc/timezone时区。
事实上,这个限制并不影响使用:
有关时区的讨论,请参阅此问题。
如何采集 LB 后面的 RS 度量
如果你有负载均衡LB,但是网络上的Prometheus只能访问LB本身,不能访问后续的RS,采集RS应该如何暴露metrics呢?
版本选择
Prometheus当前最新版本是2.16,Prometheus还在迭代中,所以尽量使用最新版本,1.X版本不是必须的。
2.16版本有一套实验UI,可以查看TSDB的状态,包括Top 10 Label、Metric。
Prometheus 大内存问题
随着规模变大,Prometheus 所需的 CPU 和内存都会增加,内存一般会先达到瓶颈。这里我们先讨论一下*敏*感*词*Prometheus的内存问题。
原因:
我的指标需要多少内存:
以我们的其中一台 Prometheus Server 为例,本地只保留了 2 个小时的数据,950,000 系列,大概占用的内存如下:
优化方案是什么:
Prometheus 内存使用分析:
相关问题:
Prometheus 容量规划
除了上面提到的内存,容量规划还包括磁盘存储规划,这和你的 Prometheus 架构有关。
Prometheus 每 2 小时将已经缓冲在内存中的数据压缩到磁盘上的块中。包括 Chunks、Indexes、Tombstones、Metadata,这些都占用了部分存储空间。一般来说,Prometheus 中存储的每个样本大约占用 1-2 个字节大小(1.7Byte)。您可以使用 Promql 查看每个样本平均占用多少空间:
"`重击
速率(prometheus_tsdb_compaction_chunk_size_bytes_sum[1h])
/
速率(prometheus_tsdb_compaction_chunk_samples_sum[1h])
{instance="0.0.0.0:8890", job="prometheus"} 1.252747585939941
"`
如果粗略估计本地磁盘的大小,可以使用以下公式:
磁盘大小 = 保留时间 * 每秒获取样本数 * 样本大小
在保留时间(retention_time_seconds)和样本大小(bytes_per_sample)不变的情况下,如果要降低本地磁盘的容量要求,只能降低每秒的样本数(ingested_samples_per_second)。
查看当前每秒采集的样本数:
rate(prometheus_tsdb_head_samples_appended_total[1h])
有两种手段,一种是减少时间序列的数量,另一种是增加采集个样本的时间间隔。考虑到 Prometheus 压缩了时间序列,减少时间序列数量的效果更加明显。
例如:
以上磁盘容量不包括wal文件。wal文件(Raw Data)在Prometheus官方文档中说明至少会保存3个Write-Ahead Log Files,每个最大大小为128M(实际数量会更多)。
因为我们使用的是灭霸的方案,所以本地磁盘只保留2H热数据。Wal 每 2 小时生成一个块文件,每 2 小时将块文件上传到对象存储。本地磁盘基本没有压力。
对于 Prometheus 的存储机制,你可以阅读这个。
对 Apiserver 的性能影响
如果你的 Prometheus 使用 kubernetes_sd_config 进行服务发现,请求一般会通过集群的 Apiserver。随着规模的增加,您需要评估对 Apiserver 性能的影响,尤其是当 Proxy 发生故障时,会导致 CPU 增加。当然,如果单个 K8S 集群规模过大,一般会进行集群拆分,但还是需要随时监控 Apiserver 的进程变化。
在监控Cadvisor、Docker、Kube-Proxy的metrics时,我们最初选择Apiserver Proxy到节点的对应端口,统一设置比较方便,后来改成直接拉节点,Apiserver只做服务发现.
Rate的计算逻辑
Prometheus 中的 Counter 类型主要是针对 Rate 存在的,即计算速率。纯Counter计数意义不大,因为一旦Counter复位,总计数就没有意义了。
Rate 会自动处理 Counter 的重置,通常会不断变大。例如,Exporter 启动然后崩溃。最初以每秒约 10 的速率递增,但只运行半小时,rate(x_total[1h]) 将返回每秒约 5 的结果。此外,计数器的任何减少也被视为计数器重置。例如,如果时间序列的值为 [5,10,4,6],则将其视为 [5,10,14,16]。
费率值很少是准确的。由于不同目标的提取发生在不同的时间,抖动会随着时间的推移而发生,query_range 很少被计算为完全匹配提取时间,并且提取可能会失败。面对这样的挑战,Rate 的设计必须稳健。
Rate 不想捕获每个 delta,因为有时 delta 会丢失,例如实例在 fetch 间隔内死亡。如果 Counter 变化缓慢,比如每小时只增加几次,可能会导致 [artifacts]。例如,有一个值为 100 的 Counter 时间序列,Rate 不知道这些增量是否是当前值,或者目标是否已经运行了几年并且刚刚开始返回。
建议将 Rate 计算的范围向量的时间设置为至少 4 倍的 fetch 间隔。这将确保即使爬行缓慢和爬行失败,您也始终有两个可用的样本。此类问题在实践中经常出现,因此保持这种弹性很重要。例如,对于 1 分钟的爬网间隔,您可以使用 4 分钟的速率计算,但这通常四舍五入为 5 分钟。
如果Rate的时间区间有缺失数据,他会根据趋势做出推断,比如:
有关详细信息,请参阅此视频
违反直觉的 P95 统计数据
histogram_quantile 是 Prometheus 常用的一个函数,例如,一个服务的 P95 响应时间经常被用来衡量服务质量。但是,具体是什么意思很难解释,尤其是对非技术类的学生来说,会遭遇很多“灵魂拷问”。
我们常说的P95(P99,P90都可以)的响应延迟是100ms,其实就是说在所有采集到的响应延迟中,有5%的请求大于100ms,95%的请求小于100ms . Prometheus中的histogram_quantile函数接收一个0-1之间的小数,小数乘以100就可以很方便的得到对应的百分位数。比如0.95对应P95,也可以是更高的百分位精度,例如 0.9999。
当您使用 histogram_quantile 绘制响应时间趋势时,您可能会被问到:为什么 P95 大于或小于我的平均值?
正如中位数可能大于或小于平均值一样,P99 完全有可能小于平均值。通常 P99 几乎总是大于平均值,但如果数据分布极端,前 1% 可能会大到推高平均值。一个可能的例子:
1, 1, ... 1, 901 // 共 100 条数据,平均值=10,P99=1
服务X分两步完成,A和B,其中X的P99耗时100Ms,A进程的P99耗时50Ms。那么B流程的P99的预估时间是多少呢?
直觉上,既然X=A+B,答案大概是50Ms,或者至少应该小于50Ms。实际上,B可以大于50Ms。只要 A 和 B 中最大的 1% 不碰巧相遇,B 就可以有一个非常大的 P99:
A = 1, 1, ... 1, 1, 1, 50, 50 // 共 100 条数据,P99=50
B = 1, 1, ... 1, 1, 1, 99, 99 // 共 100 条数据,P99=99
X = 2, 2, ... 1, 51, 51, 100, 100 // 共 100 条数据,P99=100
如果让 A 过程最大的 1% 接近 100Ms,我们也能构造出 P99 很小的 B:
A = 50, 50, ... 50, 50, 99 // 共 100 条数据,P99=50
B = 1, 1, ... 1, 1, 50 // 共 100 条数据,P99=1
X = 51, 51, ... 51, 100, 100 // 共 100 条数据,P99=100
所以,我们从标题中唯一能确定的就是B的P99不应该超过100ms,而A的P99取50Ms的条件其实是没有用的。
类似的问题还有很多,所以对于 histogram_quantile 函数,可能会产生一些反直觉的结果。最好的处理方式就是不断调整你的 Bucket 的值,保证更多的请求次数落入更详细的范围内,这样请求时间在统计上是显着的。
查询慢问题
Promql 的基础见这个 文章
Prometheus 提供了一个自定义 Promql 作为查询语句。在Graph上调试的时候会告诉你这个Sql的返回时间。如果太慢,请注意,可能是您的使用有问题。
要评估 Prometheus 的整体响应时间,您可以使用以下默认指标:
prometheus_engine_query_duration_seconds{}
一般情况下,响应慢的原因是Promql使用不当,或者指标规划有问题,比如:
基数
高基数是数据库无法回避的话题。对于像 Mysql 这样的 DB,基数是指特定列或字段中收录的唯一值的数量。基数越低,列中重复的元素就越多。对于时间序列数据库,是标签、标签等标签值的个数。
例如,如果 Prometheus 中有一个指标 http_request_count{method="get",path="/abc",originIP="1.1.1.1"},则表示访问次数,method表示请求方法,originIP是客户端IP,method的枚举值是有限的,而originIP是无限的,再加上其他标签的排列组合是无限的,没有关联的特征,所以这种高基数不适合作为 Metric 标签,如果真的要提取 originIP,应该使用 log 的方式,而不是 Metric 监控
时间序列数据库对这些标签进行索引以提高查询性能,以便您可以快速找到与所有指定标签匹配的值。如果值的个数太大,索引就没有意义了,尤其是在做P95等计算的时候,需要扫描大量的Series数据
官方文档中对 Label 的建议
CAUTION: Remember that every unique combination of key-value label pairs represents a new time series, which can dramatically increase the amount of data stored. Do not use labels to store dimensions with high cardinality (many different label values), such as user IDs, email addresses, or other unbounded sets of values.
如何查看当前的Label分布,可以使用Prometheus提供的Tsdb工具。可以使用命令行查看,也可以在2.16版本以上的Prometheus Graph中查看
[work@xxx bin]$ ./tsdb analyze ../data/prometheus/
Block ID: 01E41588AJNGM31SPGHYA3XSXG
Duration: 2h0m0s
Series: 955372
Label names: 301
Postings (unique label pairs): 30757
Postings entries (total label pairs): 10842822
....
top10 高基数指标
Highest cardinality metric names:
87176 apiserver_request_latencies_bucket
59968 apiserver_response_sizes_bucket
39862 apiserver_request_duration_seconds_bucket
37555 container_tasks_state
....
高基数标签
Highest cardinality labels:
4271 resource_version
3670 id
3414 name
1857 container_id
1824 __name__
1297 uid
1276 pod
...
找到最大的指标或工作
top10 中的指标数量:按指标名称
topk(10, count by (__name__)({__name__=~".+"}))
apiserver_request_latencies_bucket{} 62544
apiserver_response_sizes_bucket{} 44600
top10中的metrics个数:按job name
topk(10, count by (__name__, job)({__name__=~".+"}))
{job="master-scrape"} 525667
{job="xxx-kubernetes-cadvisor"} 50817
{job="yyy-kubernetes-cadvisor"} 44261
Prometheus 重启慢且热重载
当 Prometheus 重启时,需要将 Wal 的内容加载到内存中。保留时间越长,Wal文件越大,实际重启的时间越长。这是普罗米修斯的机制,没有办法做到。因此,如果可以Reload,就不要重启,必须重启。会导致短期不可用,此时Prometheus的高可用就很重要了。
Prometheus 还优化了启动时间。在 2.6 版本中,优化了 Wal 的加载速度。我希望重启时间不会超过1分钟。
Prometheus 提供热加载能力,但需要启用 web.enable-lifecycle 配置。更改配置后,可以点击curl下的reload界面。默认情况下更改 prometheus-operator 中的配置将触发重新加载。如果你不使用算子,又想监控 configmap 配置变化来重新加载服务,可以试试这个简单的脚本
#!/bin/sh
FILE=$1
URL=$2
HASH=$(md5sum $(readlink -f $FILE))
while true; do
NEW_HASH=$(md5sum $(readlink -f $FILE))
if [ "$HASH" != "$NEW_HASH" ]; then
HASH="$NEW_HASH"
echo "[$(date +%s)] Trigger refresh"
curl -sSL -X POST "$2" > /dev/null
fi
sleep 5
done
使用时挂载和prometheus一样的configmap,传入如下参数:
args:
- /etc/prometheus/prometheus.yml
- http://prometheus.kube-system.svc.cluster.local:9090/-/reload
args:
- /etc/alertmanager/alertmanager.yml
- http://prometheus.kube-system.svc.cluster.local:9093/-/reload
您的应用需要公开多少指标
自己开发服务的时候,可能会暴露一些数据给metrics,比如具体请求的数量,goroutines的数量等等,多少metrics比较合适呢?
虽然指标的数量与您的应用程序的大小有关,但有一些建议(Brian Brazil),
比如缓存等简单的服务,类似于Pushgateway,有120个左右的指标。Prometheus 本身公开了大约 700 个指标。如果您的应用程序很大,请尽量不要超过 10,000 个指标。您需要合理控制您的标签。
node-exporter node-exporter不支持进程监控的问题,前面已经讲过了。node-exporter 只支持 unix 系统,windows 机器请使用 wmi_exporter。因此,当yaml形式不是node-exporter时,node-selector应该指明os类型。因为node_exporter是老组件,有一些最佳实践没有合并,比如符合Prometheus命名约定,所以推荐使用较新的0.16和0.17版本。
一些指标名称更改:
* node_cpu -> node_cpu_seconds_total
* node_memory_MemTotal -> node_memory_MemTotal_bytes
* node_memory_MemFree -> node_memory_MemFree_bytes
* node_filesystem_avail -> node_filesystem_avail_bytes
* node_filesystem_size -> node_filesystem_size_bytes
* node_disk_io_time_ms -> node_disk_io_time_seconds_total
* node_disk_reads_completed -> node_disk_reads_completed_total
* node_disk_sectors_written -> node_disk_written_bytes_total
* node_time -> node_time_seconds
* node_boot_time -> node_boot_time_seconds
* node_intr -> node_intr_total
如果之前使用过旧版本的exporter,绘制grafana时指标名称会有所不同。有两种解决方案:
kube-state-metric 的问题
kube-state-metric的使用和原理可以先阅读
除了文章中提到的功能,kube-state-metric还有一个很重要的使用场景,就是结合cadvisor metrics。原来的cadvisor只有pod信息,不知道属于哪个deployment或者sts,但是用kube-state-metric中的kube_pod_info可以在join查询后显示。kube-state-metric 的元数据索引在扩展 cadvisor 的标签方面起到了很大的作用。prometheus-operator 的许多记录规则使用 kube-state-metric 进行组合查询。
Pod 的标签信息也可以在 kube-state-metric 中展示,这样可以在获取 cadvisor 数据后进行分组更方便,比如根据 Pod 的运行环境进行分类。但是,kube-state-metric 不会暴露 pod 的注释。原因是下面提到的高基数问题,即注解的内容太多,不适合作为指标暴露。
relabel_configs 和 metric_relabel_configs
relabel_config 出现在 采集 之前,metric_relabel_configs 出现在 采集 之后。合理的组合可以满足很多场景的配置。
喜欢:
metric_relabel_configs:
- separator: ;
regex: instance
replacement: $1
action: labeldrop
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_endpoints_name,
__meta_kubernetes_service_annotation_prometheus_io_port]
separator: ;
regex: (.+);(.+);(.*)
target_label: __metrics_path__
replacement: /api/v1/namespaces/${1}/services/${2}:${3}/proxy/metrics
action: replace
Prometheus 的预测能力
场景一:你的磁盘剩余空间一直在减少,减少的幅度比较均匀。您想知道达到阈值需要多长时间,并且您想在某个时刻发出警报。
场景二:你的 Pod 的内存使用量一直在增加,你想知道需要多长时间才能达到 Limit 值,并在某个时间报警,并在被杀死之前检查。
Prometheus 的 Deriv 和 Predict_Linear 方法可以满足这样的需求。Promtheus 提供基本的预测能力,根据当前的变化率,推断一段时间后的值。
以 mem_free 为例,最近一小时 free 值一直在下降。
mem_free仅为举例,实际内存可用以mem_available为准
deriv 函数可以显示一段时间内指标的变化率:
predict_linear 方法就是根据这个速度来预测最终可达到的值:
predict_linear(mem_free{instanceIP="100.75.155.55"}[1h], 2*3600)/1024/1024
您可以根据设置设置合理的报警规则,例如小于10时报警:
<p>rule: predict_linear(mem_free{instanceIP="100.75.155.55"}[1h], 2*3600)/1024/1024
0 个评论
官方客服QQ群
在
线
客
服
HASH=$(md5sum $(readlink -f $FILE))
while true; do
NEW_HASH=$(md5sum $(readlink -f $FILE))
if [ "$HASH" != "$NEW_HASH" ]; then
HASH="$NEW_HASH"
echo "[$(date +%s)] Trigger refresh"
curl -sSL -X POST "
逆天:黑帽seo快速排名(单页seo快速排名)
优采云 发布时间: 2022-10-02 18:15逆天:黑帽seo快速排名(单页seo快速排名)
新手如何使用WordPress 伪原创插件快速创建原创内容,快速获取网站收录和排名关键词?新手 SEO 应该怎么做?快速开始。
从新手到高手,坚持排名优化很重要。很多新手在做SEO的时候总是会陷入误区。其实他们心里是很想学seo的,但是因为不懂seo这个行业,所以走在新手的路上越来越难了。大多数新手在刚接触 seo 行业时总是不耐烦。经过几天的SEO,我开始不耐烦了。为什么它不起作用?然后他们去找各种seo老手。一般做seo的资深人士会耐心回答等等。这还早了一个月,但这是真的。这时,新手会开始感到迷茫和不知所措。那么,让我们来看看新手不擅长SEO的原因。
我不知道从哪里开始。
有很多新手对seo还是很感兴趣的,只是不知道从哪里开始,不知道怎么入手,也不知道怎么理解它的技术点。所以在这种情况下,我建议先百度一下,对seo这个行业有一个大概的了解,然后再学一些编程语言,就不用知道学编程语言有多难了。只要学过基本的HTML语言和PHP/ASP/JAVA等一些简单的编程语言,还必须学习数据分析,这是一个很重要的课题。网站 优化的质量取决于数据分析后定制执行方法的有效性。
在大部分学习者看来,所谓的SEO就是把想要的关键词优化到首页,但真正的SEO是搜索引擎优化,而不是搜索排名优化。正是因为排名被视为SEO的整体,所以没有人整天关心排名,导致很多人半途而废。总之,您对 SEO 的了解程度取决于您可以在 SEO 中走多远。
二、缺乏毅力
由于seo是一项长期有效的工作,所以大部分放弃seo的新手都是因为坚持不了。在做了几天没有效果之后,他们总是感到受到打击。但实际上,这不仅是新手如此,老手也是如此。所有从事seo多年的人都有耐心。如果你没有耐心,无论你多么熟练,你都无法完成这项工作。但不是没有优化一下子就能看到效果,但不是优化,是作弊。黑帽seo也可以在短时间内看到效果,但是想要在一个好的关键词排名中实现长期稳定,黑帽seo做不到,所以一定要坚持,否则不会能够去。新手的方法。
第三,WordPress 伪原创 插件快速创建原创 内容并不断更新网站。
要创建大量 原创 内容,首先需要大量 文章 素材。批量创作原创内容的过程是(采集行业相关的文章-处理伪原创-通过WordPress中的SEO能力提高页面原创性能伪原创插件) - 主动推送到主要搜索引擎)。在这个WordPress伪原创插件中我们不需要学习更多的专业技能,只需几个简单的步骤就可以轻松采集内容数据。用户只需要在 WordPress 伪原创 插件上进行简单的设置。完成后,WordPress 伪原创插件会根据用户设置的关键词采集高精度的内容和图片。可以保存在本地,也可以伪原创发布,提供方便快捷的内容采集和伪原创 出版服务!!
与其他WordPress伪原创插件相比,这个WordPress伪原创插件基本没有门槛,不需要花很多时间学习正则表达式或者html标签。一分钟后即可使用,只需输入 关键词 即可添加书签(WordPress 伪原创 插件还带有 关键词 书签功能)。一路挂断!将任务设置为自动化 采集pseudo-raw 发布推送任务。(支持本地采集和手动修改)
无论你有成百上千个不同的cms网站,都可以实现统一管理。一个人维护数百个网站文章更新不是问题。这个皇家伪原创插件还配备了很多SEO功能,通过软件采集伪原创的发布的同时可以提升很多SEO优化。
比如网站主动推送(让搜索引擎更快找到我们的网站),自动匹配图片(如果文章里面没有图片,会自动配置相关图片)。设置为自动下载图片并保存在本地或第三方(使内容不存在于对方外链)。自动链接(让搜索引擎更深入地抓取你的链接),前后插入内容或标题,插入网站内容或随机作者,随机阅读等,形成“高度原创”。定期发布(定期发布文章,以便搜索引擎及时抓取您的网站内容)
这些小的 SEO 功能不仅提高了 网站 页面的 原创 性能,还间接提高了 网站 的排名。您可以直接监控管理软件工具,查看文章的收录发布和百度推送,无需每天登录网站后台。目前博主亲测软件是免费的,可以直接下载使用!
首先,给自己设定一个合理的学习时间框架。
你为什么这么说?这真的很容易。一切都必须有计划和有针对性。如果没有,最简单的事情也可以无限扩展。给自己一个最后期限是很重要的,比如两三个月。说说我自己吧。我属于励志青年。
后面两个月的学习时间有限,大概需要三个月的时间来学习上手。给自己一个截止日期是合理的。为什么要讲道理?这是因为许多学生的理解能力不同。如果讲摊位的价格,你两三个月就学会了,他们两三个月就停止学习了。
很容易产生失败感而放弃学习。有的可能需要半年,有的可能一个月就学会了。当然,这是在某人的指导下。目前,一年的效果普遍不理想。
其次,你自己必须有一个网站。
很多同学想做SEO,但是没有网站。没有网站,他们就无法练习。就像我过去学的CAD一样,他们基本上一两年就忘记了。所以如果他们只学习理论而不实践和应用,他们很快就会忘记。经验是积累的。
第三,不要做你做不到的事情网站。
不能做的事不做是什么意思?指一些你很难做到的网站,因为你作为锁泉站长,没有那么多的资金和资源去做推广和营销,有些网站不适合优化,还是需要资源做的,个人不推荐。
比如,kiosk厂商不应该做团购导航或者美谈之类的分享社区,因为很难做到。类似于我自己开发的软件,功能齐全,游戏、IP变更、外贸等。相当于做起来更轻松。
第四,学会养成数据分析的习惯。
如果一个SEO从业者不分析数据,他基本上就不是一个合格的SEOER。养成数据分析的习惯,每天了解网站的数据,比如IIS日志、页面收录、页面点击、实时访问、百度PV、UV、IP等数据统计数据。
这些数据可以反映你的一些网站情况,是否有异常等等。有时候你的网站出了问题,你也不知道怎么回事。
第五,继续研究一些官方的文章搜索引擎。
不是每个人都非常擅长搜索引擎。他们对搜索引擎了解不多,只能积累。百度和谷歌目前都有可以与网站管理员交流的社区。我的建议是多去这些地方活动,可以看到很多有用的知识。也推荐阅读百度和谷歌的空优化指南。
根据你对SEO的理解,层次不同,同一件事在不同时期可以有不同的理解,会有不同的收获。看一遍有收获,再看一遍有收获。
看完这篇文章,如果觉得不错,不妨留着,或者发给需要的朋友同事。关注博主,每天带您体验各种 SEO 体验,完成您的约会!
给力:高可用 Prometheus:问题集锦【转】
2021-06-30
监控系统历史悠久,是一个非常成熟的方向,而Prometheus作为新一代的开源监控系统,已经逐渐成为云原生系统的事实标准,这也证明了它的设计很受欢迎. 本文主要分享Prometheus在实践中遇到的一些问题和思考。如果你对 K8S 监控系统或者 Prometheus 的设计不是很了解,可以先看看容器监控系列。
几个原则 Prometheus 限制 K8S 集群中常用的 exporter
Prometheus 是一个 CNCF 项目,拥有完整的开源生态系统。与Zabbix等传统代理监控不同,它提供了丰富的exporter来满足你的各种需求。您可以在此处查看官方和非官方出口商。如果还是不能满足你的需求,你也可以自己写一个exporter,简单方便,完全开放,这是一个优势。
但是,过于开放会带来选择和试错的成本。以前只需在 zabbix 代理中进行几行配置即可完成的工作,现在您将需要大量的导出器来完成它。还维护和监控所有出口商。尤其是升级exporter版本的时候,很痛苦。非官方的exporter会有很多bug。这是一个用处,当然也是Prometheus的设计原则。
K8S 生态系统的组件将提供 /metric 接口以提供自我监控。以下是我们正在使用的:
还有各种场景下的自定义导出器,比如日志提取,后面会介绍。
K8S核心组件监控和Grafana面板
k8s集群运行过程中,需要关注核心组件的状态和性能。比如kubelet、apiserver等,根据上面提到的exporter指标,可以在Grafana中绘制如下图表:
模板可以参考dashboards-for-kubernetes-administrators,根据运行情况不断调整告警阈值。
这里提到,虽然Grafana支持模板能力,可以方便的进行多级下拉框选择,但不支持模板模式下配置告警规则。相关问题
官方解释了很多这个功能,但是最新的版本还是不支持。从 issue 中借用一句话吐出:
It would be grate to add templates support in alerts. Otherwise the feature looks useless a bit.
Grafana的基本用法可以看这个文章
采集组件多合一
Prometheus 系统中的 Exporter 是独立的,每个组件都各司其职,例如 Node-Exporter 用于机器资源,Nvidia Exporter 用于 Gpu 等。但是Exporters越多,运维压力就越大,尤其是Agent的资源控制和版本升级。我们尝试结合一些Exporters,有两种解决方案:
通过主进程拉起 N 个 Exporter 进程,您仍然可以关注社区版本的更新和错误修复。使用 Telegraf 支持各种类型的 Input,N in 1。
此外,Node-Exporter 不支持进程监控。可以添加一个Process-Exporter,也可以使用上面提到的Telegraf 来使用procstat 的输入到采集process 指标。
黄金指标的合理选择
采集的指标很多,我们应该关注哪些呢?Google 在《Sre 手册》中提出了“四个黄金信号”:延迟、流量、错误数和饱和度。在实践中,您可以使用 Use 或 Red 方法作为指导,Use 用于资源,Red 用于服务。
Prometheus 采集 中共有三个常用服务:
在线服务:如Web服务、数据库等,一般关注请求率、延迟和错误率即RED方法离线服务:如日志处理、消息队列等,一般关注队列数、正在进行的数量、处理速度和出现的错误 使用方法 批处理任务:类似于离线任务,但离线任务是长时间运行的,批处理任务是按计划运行的,比如持续集成就是批处理任务,对应job或者K8S中的cronjob,一般要注意开销时间、错误次数等,因为运行周期短,很有可能在采集到来之前运行就结束了,所以一般使用pushgateway,并将拉改为推。
Use和Red的实例请参考容器监控实践-K8S常用指标分析文章。
K8S中Cadvisor的指标兼容性问题1.16
在 K8S 1.16 版本中,Cadvisor 指标移除了 pod_Name 和 container_name 的标签,并将它们替换为 pod 和 container。如果之前使用这两个标签进行查询或Grafana绘图,则需要更改Sql。因为我们一直支持多个 K8S 版本,所以我们通过 relabel 配置继续保留原来的 **_name。
metric_relabel_configs:
- source_labels: [container]
regex: (.+)
target_label: container_name
replacement: $1
action: replace
- source_labels: [pod]
regex: (.+)
target_label: pod_name
replacement: $1
action: replace
注意使用metric_relabel_configs,而不是relabel_configs,替换在采集之后。
Prometheus 采集外接K8S集群,多集群
如果Prometheus部署在K8S集群采集,使用官方的Yaml很方便,但是因为权限和网络的关系,我们需要部署在集群外,二进制操作,采集多个K8S集群.
Pod模式在集群中运行不需要证书(In-Cluster模式),但需要在集群外声明一个token等证书,并替换地址,即使用Apiserver Proxy采集 ,以Cadvisor采集为例,Job配置为:
- job_name: cluster-cadvisor
honor_timestamps: true
scrape_interval: 30s
scrape_timeout: 10s
metrics_path: /metrics
scheme: https
kubernetes_sd_configs:
- api_server: https://xx:6443
role: node
bearer_token_file: token/cluster.token
tls_config:
insecure_skip_verify: true
bearer_token_file: token/cluster.token
tls_config:
insecure_skip_verify: true
relabel_configs:
- separator: ;
regex: __meta_kubernetes_node_label_(.+)
replacement: $1
action: labelmap
- separator: ;
regex: (.*)
target_label: __address__
replacement: xx:6443
action: replace
- source_labels: [__meta_kubernetes_node_name]
separator: ;
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
action: replace
metric_relabel_configs:
- source_labels: [container]
separator: ;
regex: (.+)
target_label: container_name
replacement: $1
action: replace
- source_labels: [pod]
separator: ;
regex: (.+)
target_label: pod_name
replacement: $1
action: replace
Bearer_token_file 需要提前生成,这个可以参考官方文档。记住base64解码。
对于cadvisor,可以将__metrics_path__转换为/api/v1/nodes/${1}/proxy/metrics/cadvisor,代表Apiserver代理到Kubelet,如果网络可以通,也可以直接使用Kubelet的10255作为目标,可以直接写成:${1}:10255/metrics/cadvisor,意思是直接请求Kubelet,在规模大的时候减轻Apiserver的压力,即使用Apiserver进行服务发现,采集Apiserver 未使用
因为cadvisor暴露了主机端口,所以配置比较简单。如果是kube-state-metric之类的Deployment,是以endpoint的形式暴露出来的,写法应该是:
- job_name: cluster-service-endpoints
honor_timestamps: true
scrape_interval: 30s
scrape_timeout: 10s
metrics_path: /metrics
scheme: https
kubernetes_sd_configs:
- api_server: https://xxx:6443
role: endpoints
bearer_token_file: token/cluster.token
tls_config:
insecure_skip_verify: true
bearer_token_file: token/cluster.token
tls_config:
insecure_skip_verify: true
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
separator: ;
regex: "true"
replacement: $1
action: keep
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
separator: ;
regex: (https?)
target_label: __scheme__
replacement: $1
action: replace
- separator: ;
regex: (.*)
target_label: __address__
replacement: xxx:6443
action: replace
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_endpoints_name,
__meta_kubernetes_service_annotation_prometheus_io_port]
separator: ;
regex: (.+);(.+);(.*)
target_label: __metrics_path__
replacement: /api/v1/namespaces/${1}/services/${2}:${3}/proxy/metrics
action: replace
- separator: ;
regex: __meta_kubernetes_service_label_(.+)
replacement: $1
action: labelmap
- source_labels: [__meta_kubernetes_namespace]
separator: ;
regex: (.*)
<p>
target_label: kubernetes_namespace
replacement: $1
action: replace
- source_labels: [__meta_kubernetes_service_name]
separator: ;
regex: (.*)
target_label: kubernetes_name
replacement: $1
action: replace
</p>
对于端点类型,需要将__metrics_path__转换为/api/v1/namespaces/${1}/services/${2}:${3}/proxy/metrics,需要替换命名空间、svc名称端口、等等,这里的写法只适用于接口为/metrics的exporter。如果你的 exporter 不是 /metrics 接口,你需要替换这个路径。或者像我们一样将此地址用于统一约束。
这里的__meta_kubernetes_service_annotation_prometheus_io_port的来源是部署exporter时写的注解。大多数 文章 只提到 prometheus.io/scrape: 'true',但它也可以定义端口、路径和协议。为了方便采集时的替换处理。
其他一些relabels比如kubernetes_namespace是为了保留原创信息,方便做promql查询时的过滤条件。
如果是多集群,可以多次编写相同的配置。一般来说,一个集群可以配置三种类型的作业:
获取 GPU 指标
nvidia-smi 可以查看机器上的 GPU 资源,而 Cadvisor 实际上暴露了 Metrics 来指示容器的 GPU 使用情况。
container_accelerator_duty_cycle
container_accelerator_memory_total_bytes
container_accelerator_memory_used_bytes
如果想要更详细的 GPU 数据,可以安装 dcgm exporter,但 K8S 1.13 只能支持。
更改 Prometheus 的显示时区
为了避免时区混淆,Prometheus 使用 Unix Time 和 Utc 专门用于在所有组件中显示。不支持在配置文件中设置时区,也无法读取原生的/etc/timezone时区。
事实上,这个限制并不影响使用:
有关时区的讨论,请参阅此问题。
如何采集 LB 后面的 RS 度量
如果你有负载均衡LB,但是网络上的Prometheus只能访问LB本身,不能访问后续的RS,采集RS应该如何暴露metrics呢?
版本选择
Prometheus当前最新版本是2.16,Prometheus还在迭代中,所以尽量使用最新版本,1.X版本不是必须的。
2.16版本有一套实验UI,可以查看TSDB的状态,包括Top 10 Label、Metric。
Prometheus 大内存问题
随着规模变大,Prometheus 所需的 CPU 和内存都会增加,内存一般会先达到瓶颈。这里我们先讨论一下*敏*感*词*Prometheus的内存问题。
原因:
我的指标需要多少内存:
以我们的其中一台 Prometheus Server 为例,本地只保留了 2 个小时的数据,950,000 系列,大概占用的内存如下:
优化方案是什么:
Prometheus 内存使用分析:
相关问题:
Prometheus 容量规划
除了上面提到的内存,容量规划还包括磁盘存储规划,这和你的 Prometheus 架构有关。
Prometheus 每 2 小时将已经缓冲在内存中的数据压缩到磁盘上的块中。包括 Chunks、Indexes、Tombstones、Metadata,这些都占用了部分存储空间。一般来说,Prometheus 中存储的每个样本大约占用 1-2 个字节大小(1.7Byte)。您可以使用 Promql 查看每个样本平均占用多少空间:
"`重击
速率(prometheus_tsdb_compaction_chunk_size_bytes_sum[1h])
/
速率(prometheus_tsdb_compaction_chunk_samples_sum[1h])
{instance="0.0.0.0:8890", job="prometheus"} 1.252747585939941
"`
如果粗略估计本地磁盘的大小,可以使用以下公式:
磁盘大小 = 保留时间 * 每秒获取样本数 * 样本大小
在保留时间(retention_time_seconds)和样本大小(bytes_per_sample)不变的情况下,如果要降低本地磁盘的容量要求,只能降低每秒的样本数(ingested_samples_per_second)。
查看当前每秒采集的样本数:
rate(prometheus_tsdb_head_samples_appended_total[1h])
有两种手段,一种是减少时间序列的数量,另一种是增加采集个样本的时间间隔。考虑到 Prometheus 压缩了时间序列,减少时间序列数量的效果更加明显。
例如:
以上磁盘容量不包括wal文件。wal文件(Raw Data)在Prometheus官方文档中说明至少会保存3个Write-Ahead Log Files,每个最大大小为128M(实际数量会更多)。
因为我们使用的是灭霸的方案,所以本地磁盘只保留2H热数据。Wal 每 2 小时生成一个块文件,每 2 小时将块文件上传到对象存储。本地磁盘基本没有压力。
对于 Prometheus 的存储机制,你可以阅读这个。
对 Apiserver 的性能影响
如果你的 Prometheus 使用 kubernetes_sd_config 进行服务发现,请求一般会通过集群的 Apiserver。随着规模的增加,您需要评估对 Apiserver 性能的影响,尤其是当 Proxy 发生故障时,会导致 CPU 增加。当然,如果单个 K8S 集群规模过大,一般会进行集群拆分,但还是需要随时监控 Apiserver 的进程变化。
在监控Cadvisor、Docker、Kube-Proxy的metrics时,我们最初选择Apiserver Proxy到节点的对应端口,统一设置比较方便,后来改成直接拉节点,Apiserver只做服务发现.
Rate的计算逻辑
Prometheus 中的 Counter 类型主要是针对 Rate 存在的,即计算速率。纯Counter计数意义不大,因为一旦Counter复位,总计数就没有意义了。
Rate 会自动处理 Counter 的重置,通常会不断变大。例如,Exporter 启动然后崩溃。最初以每秒约 10 的速率递增,但只运行半小时,rate(x_total[1h]) 将返回每秒约 5 的结果。此外,计数器的任何减少也被视为计数器重置。例如,如果时间序列的值为 [5,10,4,6],则将其视为 [5,10,14,16]。
费率值很少是准确的。由于不同目标的提取发生在不同的时间,抖动会随着时间的推移而发生,query_range 很少被计算为完全匹配提取时间,并且提取可能会失败。面对这样的挑战,Rate 的设计必须稳健。
Rate 不想捕获每个 delta,因为有时 delta 会丢失,例如实例在 fetch 间隔内死亡。如果 Counter 变化缓慢,比如每小时只增加几次,可能会导致 [artifacts]。例如,有一个值为 100 的 Counter 时间序列,Rate 不知道这些增量是否是当前值,或者目标是否已经运行了几年并且刚刚开始返回。
建议将 Rate 计算的范围向量的时间设置为至少 4 倍的 fetch 间隔。这将确保即使爬行缓慢和爬行失败,您也始终有两个可用的样本。此类问题在实践中经常出现,因此保持这种弹性很重要。例如,对于 1 分钟的爬网间隔,您可以使用 4 分钟的速率计算,但这通常四舍五入为 5 分钟。
如果Rate的时间区间有缺失数据,他会根据趋势做出推断,比如:
有关详细信息,请参阅此视频
违反直觉的 P95 统计数据
histogram_quantile 是 Prometheus 常用的一个函数,例如,一个服务的 P95 响应时间经常被用来衡量服务质量。但是,具体是什么意思很难解释,尤其是对非技术类的学生来说,会遭遇很多“灵魂拷问”。
我们常说的P95(P99,P90都可以)的响应延迟是100ms,其实就是说在所有采集到的响应延迟中,有5%的请求大于100ms,95%的请求小于100ms . Prometheus中的histogram_quantile函数接收一个0-1之间的小数,小数乘以100就可以很方便的得到对应的百分位数。比如0.95对应P95,也可以是更高的百分位精度,例如 0.9999。
当您使用 histogram_quantile 绘制响应时间趋势时,您可能会被问到:为什么 P95 大于或小于我的平均值?
正如中位数可能大于或小于平均值一样,P99 完全有可能小于平均值。通常 P99 几乎总是大于平均值,但如果数据分布极端,前 1% 可能会大到推高平均值。一个可能的例子:
1, 1, ... 1, 901 // 共 100 条数据,平均值=10,P99=1
服务X分两步完成,A和B,其中X的P99耗时100Ms,A进程的P99耗时50Ms。那么B流程的P99的预估时间是多少呢?
直觉上,既然X=A+B,答案大概是50Ms,或者至少应该小于50Ms。实际上,B可以大于50Ms。只要 A 和 B 中最大的 1% 不碰巧相遇,B 就可以有一个非常大的 P99:
A = 1, 1, ... 1, 1, 1, 50, 50 // 共 100 条数据,P99=50
B = 1, 1, ... 1, 1, 1, 99, 99 // 共 100 条数据,P99=99
X = 2, 2, ... 1, 51, 51, 100, 100 // 共 100 条数据,P99=100
如果让 A 过程最大的 1% 接近 100Ms,我们也能构造出 P99 很小的 B:
A = 50, 50, ... 50, 50, 99 // 共 100 条数据,P99=50
B = 1, 1, ... 1, 1, 50 // 共 100 条数据,P99=1
X = 51, 51, ... 51, 100, 100 // 共 100 条数据,P99=100
所以,我们从标题中唯一能确定的就是B的P99不应该超过100ms,而A的P99取50Ms的条件其实是没有用的。
类似的问题还有很多,所以对于 histogram_quantile 函数,可能会产生一些反直觉的结果。最好的处理方式就是不断调整你的 Bucket 的值,保证更多的请求次数落入更详细的范围内,这样请求时间在统计上是显着的。
查询慢问题
Promql 的基础见这个 文章
Prometheus 提供了一个自定义 Promql 作为查询语句。在Graph上调试的时候会告诉你这个Sql的返回时间。如果太慢,请注意,可能是您的使用有问题。
要评估 Prometheus 的整体响应时间,您可以使用以下默认指标:
prometheus_engine_query_duration_seconds{}
一般情况下,响应慢的原因是Promql使用不当,或者指标规划有问题,比如:
基数
高基数是数据库无法回避的话题。对于像 Mysql 这样的 DB,基数是指特定列或字段中收录的唯一值的数量。基数越低,列中重复的元素就越多。对于时间序列数据库,是标签、标签等标签值的个数。
例如,如果 Prometheus 中有一个指标 http_request_count{method="get",path="/abc",originIP="1.1.1.1"},则表示访问次数,method表示请求方法,originIP是客户端IP,method的枚举值是有限的,而originIP是无限的,再加上其他标签的排列组合是无限的,没有关联的特征,所以这种高基数不适合作为 Metric 标签,如果真的要提取 originIP,应该使用 log 的方式,而不是 Metric 监控
时间序列数据库对这些标签进行索引以提高查询性能,以便您可以快速找到与所有指定标签匹配的值。如果值的个数太大,索引就没有意义了,尤其是在做P95等计算的时候,需要扫描大量的Series数据
官方文档中对 Label 的建议
CAUTION: Remember that every unique combination of key-value label pairs represents a new time series, which can dramatically increase the amount of data stored. Do not use labels to store dimensions with high cardinality (many different label values), such as user IDs, email addresses, or other unbounded sets of values.
如何查看当前的Label分布,可以使用Prometheus提供的Tsdb工具。可以使用命令行查看,也可以在2.16版本以上的Prometheus Graph中查看
[work@xxx bin]$ ./tsdb analyze ../data/prometheus/
Block ID: 01E41588AJNGM31SPGHYA3XSXG
Duration: 2h0m0s
Series: 955372
Label names: 301
Postings (unique label pairs): 30757
Postings entries (total label pairs): 10842822
....
top10 高基数指标
Highest cardinality metric names:
87176 apiserver_request_latencies_bucket
59968 apiserver_response_sizes_bucket
39862 apiserver_request_duration_seconds_bucket
37555 container_tasks_state
....
高基数标签
Highest cardinality labels:
4271 resource_version
3670 id
3414 name
1857 container_id
1824 __name__
1297 uid
1276 pod
...
找到最大的指标或工作
top10 中的指标数量:按指标名称
topk(10, count by (__name__)({__name__=~".+"}))
apiserver_request_latencies_bucket{} 62544
apiserver_response_sizes_bucket{} 44600
top10中的metrics个数:按job name
topk(10, count by (__name__, job)({__name__=~".+"}))
{job="master-scrape"} 525667
{job="xxx-kubernetes-cadvisor"} 50817
{job="yyy-kubernetes-cadvisor"} 44261
Prometheus 重启慢且热重载
当 Prometheus 重启时,需要将 Wal 的内容加载到内存中。保留时间越长,Wal文件越大,实际重启的时间越长。这是普罗米修斯的机制,没有办法做到。因此,如果可以Reload,就不要重启,必须重启。会导致短期不可用,此时Prometheus的高可用就很重要了。
Prometheus 还优化了启动时间。在 2.6 版本中,优化了 Wal 的加载速度。我希望重启时间不会超过1分钟。
Prometheus 提供热加载能力,但需要启用 web.enable-lifecycle 配置。更改配置后,可以点击curl下的reload界面。默认情况下更改 prometheus-operator 中的配置将触发重新加载。如果你不使用算子,又想监控 configmap 配置变化来重新加载服务,可以试试这个简单的脚本
#!/bin/sh
FILE=$1
URL=$2
HASH=$(md5sum $(readlink -f $FILE))
while true; do
NEW_HASH=$(md5sum $(readlink -f $FILE))
if [ "$HASH" != "$NEW_HASH" ]; then
HASH="$NEW_HASH"
echo "[$(date +%s)] Trigger refresh"
curl -sSL -X POST "$2" > /dev/null
fi
sleep 5
done
使用时挂载和prometheus一样的configmap,传入如下参数:
args:
- /etc/prometheus/prometheus.yml
- http://prometheus.kube-system.svc.cluster.local:9090/-/reload
args:
- /etc/alertmanager/alertmanager.yml
- http://prometheus.kube-system.svc.cluster.local:9093/-/reload
您的应用需要公开多少指标
自己开发服务的时候,可能会暴露一些数据给metrics,比如具体请求的数量,goroutines的数量等等,多少metrics比较合适呢?
虽然指标的数量与您的应用程序的大小有关,但有一些建议(Brian Brazil),
比如缓存等简单的服务,类似于Pushgateway,有120个左右的指标。Prometheus 本身公开了大约 700 个指标。如果您的应用程序很大,请尽量不要超过 10,000 个指标。您需要合理控制您的标签。
node-exporter node-exporter不支持进程监控的问题,前面已经讲过了。node-exporter 只支持 unix 系统,windows 机器请使用 wmi_exporter。因此,当yaml形式不是node-exporter时,node-selector应该指明os类型。因为node_exporter是老组件,有一些最佳实践没有合并,比如符合Prometheus命名约定,所以推荐使用较新的0.16和0.17版本。
一些指标名称更改:
* node_cpu -> node_cpu_seconds_total
* node_memory_MemTotal -> node_memory_MemTotal_bytes
* node_memory_MemFree -> node_memory_MemFree_bytes
* node_filesystem_avail -> node_filesystem_avail_bytes
* node_filesystem_size -> node_filesystem_size_bytes
* node_disk_io_time_ms -> node_disk_io_time_seconds_total
* node_disk_reads_completed -> node_disk_reads_completed_total
* node_disk_sectors_written -> node_disk_written_bytes_total
* node_time -> node_time_seconds
* node_boot_time -> node_boot_time_seconds
* node_intr -> node_intr_total
如果之前使用过旧版本的exporter,绘制grafana时指标名称会有所不同。有两种解决方案:
kube-state-metric 的问题
kube-state-metric的使用和原理可以先阅读
除了文章中提到的功能,kube-state-metric还有一个很重要的使用场景,就是结合cadvisor metrics。原来的cadvisor只有pod信息,不知道属于哪个deployment或者sts,但是用kube-state-metric中的kube_pod_info可以在join查询后显示。kube-state-metric 的元数据索引在扩展 cadvisor 的标签方面起到了很大的作用。prometheus-operator 的许多记录规则使用 kube-state-metric 进行组合查询。
Pod 的标签信息也可以在 kube-state-metric 中展示,这样可以在获取 cadvisor 数据后进行分组更方便,比如根据 Pod 的运行环境进行分类。但是,kube-state-metric 不会暴露 pod 的注释。原因是下面提到的高基数问题,即注解的内容太多,不适合作为指标暴露。
relabel_configs 和 metric_relabel_configs
relabel_config 出现在 采集 之前,metric_relabel_configs 出现在 采集 之后。合理的组合可以满足很多场景的配置。
喜欢:
metric_relabel_configs:
- separator: ;
regex: instance
replacement: $1
action: labeldrop
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_endpoints_name,
__meta_kubernetes_service_annotation_prometheus_io_port]
separator: ;
regex: (.+);(.+);(.*)
target_label: __metrics_path__
replacement: /api/v1/namespaces/${1}/services/${2}:${3}/proxy/metrics
action: replace
Prometheus 的预测能力
场景一:你的磁盘剩余空间一直在减少,减少的幅度比较均匀。您想知道达到阈值需要多长时间,并且您想在某个时刻发出警报。
场景二:你的 Pod 的内存使用量一直在增加,你想知道需要多长时间才能达到 Limit 值,并在某个时间报警,并在被杀死之前检查。
Prometheus 的 Deriv 和 Predict_Linear 方法可以满足这样的需求。Promtheus 提供基本的预测能力,根据当前的变化率,推断一段时间后的值。
以 mem_free 为例,最近一小时 free 值一直在下降。
mem_free仅为举例,实际内存可用以mem_available为准
deriv 函数可以显示一段时间内指标的变化率:
predict_linear 方法就是根据这个速度来预测最终可达到的值:
predict_linear(mem_free{instanceIP="100.75.155.55"}[1h], 2*3600)/1024/1024
您可以根据设置设置合理的报警规则,例如小于10时报警:
<p>rule: predict_linear(mem_free{instanceIP="100.75.155.55"}[1h], 2*3600)/1024/1024
0 个评论
官方客服QQ群
在
线
客
服
fi
sleep 5
done
使用时挂载和prometheus一样的configmap,传入如下参数:
args:
- /etc/prometheus/prometheus.yml
- http://prometheus.kube-system.svc.cluster.local:9090/-/reload
args:
- /etc/alertmanager/alertmanager.yml
- http://prometheus.kube-system.svc.cluster.local:9093/-/reload
您的应用需要公开多少指标
自己开发服务的时候,可能会暴露一些数据给metrics,比如具体请求的数量,goroutines的数量等等,多少metrics比较合适呢?
虽然指标的数量与您的应用程序的大小有关,但有一些建议(Brian Brazil),
比如缓存等简单的服务,类似于Pushgateway,有120个左右的指标。Prometheus 本身公开了大约 700 个指标。如果您的应用程序很大,请尽量不要超过 10,000 个指标。您需要合理控制您的标签。
node-exporter node-exporter不支持进程监控的问题,前面已经讲过了。node-exporter 只支持 unix 系统,windows 机器请使用 wmi_exporter。因此,当yaml形式不是node-exporter时,node-selector应该指明os类型。因为node_exporter是老组件,有一些最佳实践没有合并,比如符合Prometheus命名约定,所以推荐使用较新的0.16和0.17版本。
一些指标名称更改:
* node_cpu -> node_cpu_seconds_total
* node_memory_MemTotal -> node_memory_MemTotal_bytes
* node_memory_MemFree -> node_memory_MemFree_bytes
* node_filesystem_avail -> node_filesystem_avail_bytes
* node_filesystem_size -> node_filesystem_size_bytes
* node_disk_io_time_ms -> node_disk_io_time_seconds_total
* node_disk_reads_completed -> node_disk_reads_completed_total
* node_disk_sectors_written -> node_disk_written_bytes_total
* node_time -> node_time_seconds
* node_boot_time -> node_boot_time_seconds
* node_intr -> node_intr_total
如果之前使用过旧版本的exporter,绘制grafana时指标名称会有所不同。有两种解决方案:
kube-state-metric 的问题
kube-state-metric的使用和原理可以先阅读
除了文章中提到的功能,kube-state-metric还有一个很重要的使用场景,就是结合cadvisor metrics。原来的cadvisor只有pod信息,不知道属于哪个deployment或者sts,但是用kube-state-metric中的kube_pod_info可以在join查询后显示。kube-state-metric 的元数据索引在扩展 cadvisor 的标签方面起到了很大的作用。prometheus-operator 的许多记录规则使用 kube-state-metric 进行组合查询。
Pod 的标签信息也可以在 kube-state-metric 中展示,这样可以在获取 cadvisor 数据后进行分组更方便,比如根据 Pod 的运行环境进行分类。但是,kube-state-metric 不会暴露 pod 的注释。原因是下面提到的高基数问题,即注解的内容太多,不适合作为指标暴露。
relabel_configs 和 metric_relabel_configs
relabel_config 出现在 采集 之前,metric_relabel_configs 出现在 采集 之后。合理的组合可以满足很多场景的配置。
喜欢:
metric_relabel_configs:
- separator: ;
regex: instance
replacement:
action: labeldrop
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_endpoints_name,
__meta_kubernetes_service_annotation_prometheus_io_port]
separator: ;
regex: (.+);(.+);(.*)
target_label: __metrics_path__
replacement: /api/v1/namespaces/
/services/逆天:黑帽seo快速排名(单页seo快速排名)
优采云 发布时间: 2022-10-02 18:15逆天:黑帽seo快速排名(单页seo快速排名)
新手如何使用WordPress 伪原创插件快速创建原创内容,快速获取网站收录和排名关键词?新手 SEO 应该怎么做?快速开始。
从新手到高手,坚持排名优化很重要。很多新手在做SEO的时候总是会陷入误区。其实他们心里是很想学seo的,但是因为不懂seo这个行业,所以走在新手的路上越来越难了。大多数新手在刚接触 seo 行业时总是不耐烦。经过几天的SEO,我开始不耐烦了。为什么它不起作用?然后他们去找各种seo老手。一般做seo的资深人士会耐心回答等等。这还早了一个月,但这是真的。这时,新手会开始感到迷茫和不知所措。那么,让我们来看看新手不擅长SEO的原因。
我不知道从哪里开始。
有很多新手对seo还是很感兴趣的,只是不知道从哪里开始,不知道怎么入手,也不知道怎么理解它的技术点。所以在这种情况下,我建议先百度一下,对seo这个行业有一个大概的了解,然后再学一些编程语言,就不用知道学编程语言有多难了。只要学过基本的HTML语言和PHP/ASP/JAVA等一些简单的编程语言,还必须学习数据分析,这是一个很重要的课题。网站 优化的质量取决于数据分析后定制执行方法的有效性。
在大部分学习者看来,所谓的SEO就是把想要的关键词优化到首页,但真正的SEO是搜索引擎优化,而不是搜索排名优化。正是因为排名被视为SEO的整体,所以没有人整天关心排名,导致很多人半途而废。总之,您对 SEO 的了解程度取决于您可以在 SEO 中走多远。
二、缺乏毅力
由于seo是一项长期有效的工作,所以大部分放弃seo的新手都是因为坚持不了。在做了几天没有效果之后,他们总是感到受到打击。但实际上,这不仅是新手如此,老手也是如此。所有从事seo多年的人都有耐心。如果你没有耐心,无论你多么熟练,你都无法完成这项工作。但不是没有优化一下子就能看到效果,但不是优化,是作弊。黑帽seo也可以在短时间内看到效果,但是想要在一个好的关键词排名中实现长期稳定,黑帽seo做不到,所以一定要坚持,否则不会能够去。新手的方法。
第三,WordPress 伪原创 插件快速创建原创 内容并不断更新网站。
要创建大量 原创 内容,首先需要大量 文章 素材。批量创作原创内容的过程是(采集行业相关的文章-处理伪原创-通过WordPress中的SEO能力提高页面原创性能伪原创插件) - 主动推送到主要搜索引擎)。在这个WordPress伪原创插件中我们不需要学习更多的专业技能,只需几个简单的步骤就可以轻松采集内容数据。用户只需要在 WordPress 伪原创 插件上进行简单的设置。完成后,WordPress 伪原创插件会根据用户设置的关键词采集高精度的内容和图片。可以保存在本地,也可以伪原创发布,提供方便快捷的内容采集和伪原创 出版服务!!
与其他WordPress伪原创插件相比,这个WordPress伪原创插件基本没有门槛,不需要花很多时间学习正则表达式或者html标签。一分钟后即可使用,只需输入 关键词 即可添加书签(WordPress 伪原创 插件还带有 关键词 书签功能)。一路挂断!将任务设置为自动化 采集pseudo-raw 发布推送任务。(支持本地采集和手动修改)
无论你有成百上千个不同的cms网站,都可以实现统一管理。一个人维护数百个网站文章更新不是问题。这个皇家伪原创插件还配备了很多SEO功能,通过软件采集伪原创的发布的同时可以提升很多SEO优化。
比如网站主动推送(让搜索引擎更快找到我们的网站),自动匹配图片(如果文章里面没有图片,会自动配置相关图片)。设置为自动下载图片并保存在本地或第三方(使内容不存在于对方外链)。自动链接(让搜索引擎更深入地抓取你的链接),前后插入内容或标题,插入网站内容或随机作者,随机阅读等,形成“高度原创”。定期发布(定期发布文章,以便搜索引擎及时抓取您的网站内容)
这些小的 SEO 功能不仅提高了 网站 页面的 原创 性能,还间接提高了 网站 的排名。您可以直接监控管理软件工具,查看文章的收录发布和百度推送,无需每天登录网站后台。目前博主亲测软件是免费的,可以直接下载使用!
首先,给自己设定一个合理的学习时间框架。
你为什么这么说?这真的很容易。一切都必须有计划和有针对性。如果没有,最简单的事情也可以无限扩展。给自己一个最后期限是很重要的,比如两三个月。说说我自己吧。我属于励志青年。
后面两个月的学习时间有限,大概需要三个月的时间来学习上手。给自己一个截止日期是合理的。为什么要讲道理?这是因为许多学生的理解能力不同。如果讲摊位的价格,你两三个月就学会了,他们两三个月就停止学习了。
很容易产生失败感而放弃学习。有的可能需要半年,有的可能一个月就学会了。当然,这是在某人的指导下。目前,一年的效果普遍不理想。
其次,你自己必须有一个网站。
很多同学想做SEO,但是没有网站。没有网站,他们就无法练习。就像我过去学的CAD一样,他们基本上一两年就忘记了。所以如果他们只学习理论而不实践和应用,他们很快就会忘记。经验是积累的。
第三,不要做你做不到的事情网站。
不能做的事不做是什么意思?指一些你很难做到的网站,因为你作为锁泉站长,没有那么多的资金和资源去做推广和营销,有些网站不适合优化,还是需要资源做的,个人不推荐。
比如,kiosk厂商不应该做团购导航或者美谈之类的分享社区,因为很难做到。类似于我自己开发的软件,功能齐全,游戏、IP变更、外贸等。相当于做起来更轻松。
第四,学会养成数据分析的习惯。
如果一个SEO从业者不分析数据,他基本上就不是一个合格的SEOER。养成数据分析的习惯,每天了解网站的数据,比如IIS日志、页面收录、页面点击、实时访问、百度PV、UV、IP等数据统计数据。
这些数据可以反映你的一些网站情况,是否有异常等等。有时候你的网站出了问题,你也不知道怎么回事。
第五,继续研究一些官方的文章搜索引擎。
不是每个人都非常擅长搜索引擎。他们对搜索引擎了解不多,只能积累。百度和谷歌目前都有可以与网站管理员交流的社区。我的建议是多去这些地方活动,可以看到很多有用的知识。也推荐阅读百度和谷歌的空优化指南。
根据你对SEO的理解,层次不同,同一件事在不同时期可以有不同的理解,会有不同的收获。看一遍有收获,再看一遍有收获。
看完这篇文章,如果觉得不错,不妨留着,或者发给需要的朋友同事。关注博主,每天带您体验各种 SEO 体验,完成您的约会!
给力:高可用 Prometheus:问题集锦【转】
2021-06-30
监控系统历史悠久,是一个非常成熟的方向,而Prometheus作为新一代的开源监控系统,已经逐渐成为云原生系统的事实标准,这也证明了它的设计很受欢迎. 本文主要分享Prometheus在实践中遇到的一些问题和思考。如果你对 K8S 监控系统或者 Prometheus 的设计不是很了解,可以先看看容器监控系列。
几个原则 Prometheus 限制 K8S 集群中常用的 exporter
Prometheus 是一个 CNCF 项目,拥有完整的开源生态系统。与Zabbix等传统代理监控不同,它提供了丰富的exporter来满足你的各种需求。您可以在此处查看官方和非官方出口商。如果还是不能满足你的需求,你也可以自己写一个exporter,简单方便,完全开放,这是一个优势。
但是,过于开放会带来选择和试错的成本。以前只需在 zabbix 代理中进行几行配置即可完成的工作,现在您将需要大量的导出器来完成它。还维护和监控所有出口商。尤其是升级exporter版本的时候,很痛苦。非官方的exporter会有很多bug。这是一个用处,当然也是Prometheus的设计原则。
K8S 生态系统的组件将提供 /metric 接口以提供自我监控。以下是我们正在使用的:
还有各种场景下的自定义导出器,比如日志提取,后面会介绍。
K8S核心组件监控和Grafana面板
k8s集群运行过程中,需要关注核心组件的状态和性能。比如kubelet、apiserver等,根据上面提到的exporter指标,可以在Grafana中绘制如下图表:
模板可以参考dashboards-for-kubernetes-administrators,根据运行情况不断调整告警阈值。
这里提到,虽然Grafana支持模板能力,可以方便的进行多级下拉框选择,但不支持模板模式下配置告警规则。相关问题
官方解释了很多这个功能,但是最新的版本还是不支持。从 issue 中借用一句话吐出:
It would be grate to add templates support in alerts. Otherwise the feature looks useless a bit.
Grafana的基本用法可以看这个文章
采集组件多合一
Prometheus 系统中的 Exporter 是独立的,每个组件都各司其职,例如 Node-Exporter 用于机器资源,Nvidia Exporter 用于 Gpu 等。但是Exporters越多,运维压力就越大,尤其是Agent的资源控制和版本升级。我们尝试结合一些Exporters,有两种解决方案:
通过主进程拉起 N 个 Exporter 进程,您仍然可以关注社区版本的更新和错误修复。使用 Telegraf 支持各种类型的 Input,N in 1。
此外,Node-Exporter 不支持进程监控。可以添加一个Process-Exporter,也可以使用上面提到的Telegraf 来使用procstat 的输入到采集process 指标。
黄金指标的合理选择
采集的指标很多,我们应该关注哪些呢?Google 在《Sre 手册》中提出了“四个黄金信号”:延迟、流量、错误数和饱和度。在实践中,您可以使用 Use 或 Red 方法作为指导,Use 用于资源,Red 用于服务。
Prometheus 采集 中共有三个常用服务:
在线服务:如Web服务、数据库等,一般关注请求率、延迟和错误率即RED方法离线服务:如日志处理、消息队列等,一般关注队列数、正在进行的数量、处理速度和出现的错误 使用方法 批处理任务:类似于离线任务,但离线任务是长时间运行的,批处理任务是按计划运行的,比如持续集成就是批处理任务,对应job或者K8S中的cronjob,一般要注意开销时间、错误次数等,因为运行周期短,很有可能在采集到来之前运行就结束了,所以一般使用pushgateway,并将拉改为推。
Use和Red的实例请参考容器监控实践-K8S常用指标分析文章。
K8S中Cadvisor的指标兼容性问题1.16
在 K8S 1.16 版本中,Cadvisor 指标移除了 pod_Name 和 container_name 的标签,并将它们替换为 pod 和 container。如果之前使用这两个标签进行查询或Grafana绘图,则需要更改Sql。因为我们一直支持多个 K8S 版本,所以我们通过 relabel 配置继续保留原来的 **_name。
metric_relabel_configs:
- source_labels: [container]
regex: (.+)
target_label: container_name
replacement: $1
action: replace
- source_labels: [pod]
regex: (.+)
target_label: pod_name
replacement: $1
action: replace
注意使用metric_relabel_configs,而不是relabel_configs,替换在采集之后。
Prometheus 采集外接K8S集群,多集群
如果Prometheus部署在K8S集群采集,使用官方的Yaml很方便,但是因为权限和网络的关系,我们需要部署在集群外,二进制操作,采集多个K8S集群.
Pod模式在集群中运行不需要证书(In-Cluster模式),但需要在集群外声明一个token等证书,并替换地址,即使用Apiserver Proxy采集 ,以Cadvisor采集为例,Job配置为:
- job_name: cluster-cadvisor
honor_timestamps: true
scrape_interval: 30s
scrape_timeout: 10s
metrics_path: /metrics
scheme: https
kubernetes_sd_configs:
- api_server: https://xx:6443
role: node
bearer_token_file: token/cluster.token
tls_config:
insecure_skip_verify: true
bearer_token_file: token/cluster.token
tls_config:
insecure_skip_verify: true
relabel_configs:
- separator: ;
regex: __meta_kubernetes_node_label_(.+)
replacement: $1
action: labelmap
- separator: ;
regex: (.*)
target_label: __address__
replacement: xx:6443
action: replace
- source_labels: [__meta_kubernetes_node_name]
separator: ;
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
action: replace
metric_relabel_configs:
- source_labels: [container]
separator: ;
regex: (.+)
target_label: container_name
replacement: $1
action: replace
- source_labels: [pod]
separator: ;
regex: (.+)
target_label: pod_name
replacement: $1
action: replace
Bearer_token_file 需要提前生成,这个可以参考官方文档。记住base64解码。
对于cadvisor,可以将__metrics_path__转换为/api/v1/nodes/${1}/proxy/metrics/cadvisor,代表Apiserver代理到Kubelet,如果网络可以通,也可以直接使用Kubelet的10255作为目标,可以直接写成:${1}:10255/metrics/cadvisor,意思是直接请求Kubelet,在规模大的时候减轻Apiserver的压力,即使用Apiserver进行服务发现,采集Apiserver 未使用
因为cadvisor暴露了主机端口,所以配置比较简单。如果是kube-state-metric之类的Deployment,是以endpoint的形式暴露出来的,写法应该是:
- job_name: cluster-service-endpoints
honor_timestamps: true
scrape_interval: 30s
scrape_timeout: 10s
metrics_path: /metrics
scheme: https
kubernetes_sd_configs:
- api_server: https://xxx:6443
role: endpoints
bearer_token_file: token/cluster.token
tls_config:
insecure_skip_verify: true
bearer_token_file: token/cluster.token
tls_config:
insecure_skip_verify: true
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
separator: ;
regex: "true"
replacement: $1
action: keep
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
separator: ;
regex: (https?)
target_label: __scheme__
replacement: $1
action: replace
- separator: ;
regex: (.*)
target_label: __address__
replacement: xxx:6443
action: replace
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_endpoints_name,
__meta_kubernetes_service_annotation_prometheus_io_port]
separator: ;
regex: (.+);(.+);(.*)
target_label: __metrics_path__
replacement: /api/v1/namespaces/${1}/services/${2}:${3}/proxy/metrics
action: replace
- separator: ;
regex: __meta_kubernetes_service_label_(.+)
replacement: $1
action: labelmap
- source_labels: [__meta_kubernetes_namespace]
separator: ;
regex: (.*)
<p>
target_label: kubernetes_namespace
replacement: $1
action: replace
- source_labels: [__meta_kubernetes_service_name]
separator: ;
regex: (.*)
target_label: kubernetes_name
replacement: $1
action: replace
</p>
对于端点类型,需要将__metrics_path__转换为/api/v1/namespaces/${1}/services/${2}:${3}/proxy/metrics,需要替换命名空间、svc名称端口、等等,这里的写法只适用于接口为/metrics的exporter。如果你的 exporter 不是 /metrics 接口,你需要替换这个路径。或者像我们一样将此地址用于统一约束。
这里的__meta_kubernetes_service_annotation_prometheus_io_port的来源是部署exporter时写的注解。大多数 文章 只提到 prometheus.io/scrape: 'true',但它也可以定义端口、路径和协议。为了方便采集时的替换处理。
其他一些relabels比如kubernetes_namespace是为了保留原创信息,方便做promql查询时的过滤条件。
如果是多集群,可以多次编写相同的配置。一般来说,一个集群可以配置三种类型的作业:
获取 GPU 指标
nvidia-smi 可以查看机器上的 GPU 资源,而 Cadvisor 实际上暴露了 Metrics 来指示容器的 GPU 使用情况。
container_accelerator_duty_cycle
container_accelerator_memory_total_bytes
container_accelerator_memory_used_bytes
如果想要更详细的 GPU 数据,可以安装 dcgm exporter,但 K8S 1.13 只能支持。
更改 Prometheus 的显示时区
为了避免时区混淆,Prometheus 使用 Unix Time 和 Utc 专门用于在所有组件中显示。不支持在配置文件中设置时区,也无法读取原生的/etc/timezone时区。
事实上,这个限制并不影响使用:
有关时区的讨论,请参阅此问题。
如何采集 LB 后面的 RS 度量
如果你有负载均衡LB,但是网络上的Prometheus只能访问LB本身,不能访问后续的RS,采集RS应该如何暴露metrics呢?
版本选择
Prometheus当前最新版本是2.16,Prometheus还在迭代中,所以尽量使用最新版本,1.X版本不是必须的。
2.16版本有一套实验UI,可以查看TSDB的状态,包括Top 10 Label、Metric。
Prometheus 大内存问题
随着规模变大,Prometheus 所需的 CPU 和内存都会增加,内存一般会先达到瓶颈。这里我们先讨论一下*敏*感*词*Prometheus的内存问题。
原因:
我的指标需要多少内存:
以我们的其中一台 Prometheus Server 为例,本地只保留了 2 个小时的数据,950,000 系列,大概占用的内存如下:
优化方案是什么:
Prometheus 内存使用分析:
相关问题:
Prometheus 容量规划
除了上面提到的内存,容量规划还包括磁盘存储规划,这和你的 Prometheus 架构有关。
Prometheus 每 2 小时将已经缓冲在内存中的数据压缩到磁盘上的块中。包括 Chunks、Indexes、Tombstones、Metadata,这些都占用了部分存储空间。一般来说,Prometheus 中存储的每个样本大约占用 1-2 个字节大小(1.7Byte)。您可以使用 Promql 查看每个样本平均占用多少空间:
"`重击
速率(prometheus_tsdb_compaction_chunk_size_bytes_sum[1h])
/
速率(prometheus_tsdb_compaction_chunk_samples_sum[1h])
{instance="0.0.0.0:8890", job="prometheus"} 1.252747585939941
"`
如果粗略估计本地磁盘的大小,可以使用以下公式:
磁盘大小 = 保留时间 * 每秒获取样本数 * 样本大小
在保留时间(retention_time_seconds)和样本大小(bytes_per_sample)不变的情况下,如果要降低本地磁盘的容量要求,只能降低每秒的样本数(ingested_samples_per_second)。
查看当前每秒采集的样本数:
rate(prometheus_tsdb_head_samples_appended_total[1h])
有两种手段,一种是减少时间序列的数量,另一种是增加采集个样本的时间间隔。考虑到 Prometheus 压缩了时间序列,减少时间序列数量的效果更加明显。
例如:
以上磁盘容量不包括wal文件。wal文件(Raw Data)在Prometheus官方文档中说明至少会保存3个Write-Ahead Log Files,每个最大大小为128M(实际数量会更多)。
因为我们使用的是灭霸的方案,所以本地磁盘只保留2H热数据。Wal 每 2 小时生成一个块文件,每 2 小时将块文件上传到对象存储。本地磁盘基本没有压力。
对于 Prometheus 的存储机制,你可以阅读这个。
对 Apiserver 的性能影响
如果你的 Prometheus 使用 kubernetes_sd_config 进行服务发现,请求一般会通过集群的 Apiserver。随着规模的增加,您需要评估对 Apiserver 性能的影响,尤其是当 Proxy 发生故障时,会导致 CPU 增加。当然,如果单个 K8S 集群规模过大,一般会进行集群拆分,但还是需要随时监控 Apiserver 的进程变化。
在监控Cadvisor、Docker、Kube-Proxy的metrics时,我们最初选择Apiserver Proxy到节点的对应端口,统一设置比较方便,后来改成直接拉节点,Apiserver只做服务发现.
Rate的计算逻辑
Prometheus 中的 Counter 类型主要是针对 Rate 存在的,即计算速率。纯Counter计数意义不大,因为一旦Counter复位,总计数就没有意义了。
Rate 会自动处理 Counter 的重置,通常会不断变大。例如,Exporter 启动然后崩溃。最初以每秒约 10 的速率递增,但只运行半小时,rate(x_total[1h]) 将返回每秒约 5 的结果。此外,计数器的任何减少也被视为计数器重置。例如,如果时间序列的值为 [5,10,4,6],则将其视为 [5,10,14,16]。
费率值很少是准确的。由于不同目标的提取发生在不同的时间,抖动会随着时间的推移而发生,query_range 很少被计算为完全匹配提取时间,并且提取可能会失败。面对这样的挑战,Rate 的设计必须稳健。
Rate 不想捕获每个 delta,因为有时 delta 会丢失,例如实例在 fetch 间隔内死亡。如果 Counter 变化缓慢,比如每小时只增加几次,可能会导致 [artifacts]。例如,有一个值为 100 的 Counter 时间序列,Rate 不知道这些增量是否是当前值,或者目标是否已经运行了几年并且刚刚开始返回。
建议将 Rate 计算的范围向量的时间设置为至少 4 倍的 fetch 间隔。这将确保即使爬行缓慢和爬行失败,您也始终有两个可用的样本。此类问题在实践中经常出现,因此保持这种弹性很重要。例如,对于 1 分钟的爬网间隔,您可以使用 4 分钟的速率计算,但这通常四舍五入为 5 分钟。
如果Rate的时间区间有缺失数据,他会根据趋势做出推断,比如:
有关详细信息,请参阅此视频
违反直觉的 P95 统计数据
histogram_quantile 是 Prometheus 常用的一个函数,例如,一个服务的 P95 响应时间经常被用来衡量服务质量。但是,具体是什么意思很难解释,尤其是对非技术类的学生来说,会遭遇很多“灵魂拷问”。
我们常说的P95(P99,P90都可以)的响应延迟是100ms,其实就是说在所有采集到的响应延迟中,有5%的请求大于100ms,95%的请求小于100ms . Prometheus中的histogram_quantile函数接收一个0-1之间的小数,小数乘以100就可以很方便的得到对应的百分位数。比如0.95对应P95,也可以是更高的百分位精度,例如 0.9999。
当您使用 histogram_quantile 绘制响应时间趋势时,您可能会被问到:为什么 P95 大于或小于我的平均值?
正如中位数可能大于或小于平均值一样,P99 完全有可能小于平均值。通常 P99 几乎总是大于平均值,但如果数据分布极端,前 1% 可能会大到推高平均值。一个可能的例子:
1, 1, ... 1, 901 // 共 100 条数据,平均值=10,P99=1
服务X分两步完成,A和B,其中X的P99耗时100Ms,A进程的P99耗时50Ms。那么B流程的P99的预估时间是多少呢?
直觉上,既然X=A+B,答案大概是50Ms,或者至少应该小于50Ms。实际上,B可以大于50Ms。只要 A 和 B 中最大的 1% 不碰巧相遇,B 就可以有一个非常大的 P99:
A = 1, 1, ... 1, 1, 1, 50, 50 // 共 100 条数据,P99=50
B = 1, 1, ... 1, 1, 1, 99, 99 // 共 100 条数据,P99=99
X = 2, 2, ... 1, 51, 51, 100, 100 // 共 100 条数据,P99=100
如果让 A 过程最大的 1% 接近 100Ms,我们也能构造出 P99 很小的 B:
A = 50, 50, ... 50, 50, 99 // 共 100 条数据,P99=50
B = 1, 1, ... 1, 1, 50 // 共 100 条数据,P99=1
X = 51, 51, ... 51, 100, 100 // 共 100 条数据,P99=100
所以,我们从标题中唯一能确定的就是B的P99不应该超过100ms,而A的P99取50Ms的条件其实是没有用的。
类似的问题还有很多,所以对于 histogram_quantile 函数,可能会产生一些反直觉的结果。最好的处理方式就是不断调整你的 Bucket 的值,保证更多的请求次数落入更详细的范围内,这样请求时间在统计上是显着的。
查询慢问题
Promql 的基础见这个 文章
Prometheus 提供了一个自定义 Promql 作为查询语句。在Graph上调试的时候会告诉你这个Sql的返回时间。如果太慢,请注意,可能是您的使用有问题。
要评估 Prometheus 的整体响应时间,您可以使用以下默认指标:
prometheus_engine_query_duration_seconds{}
一般情况下,响应慢的原因是Promql使用不当,或者指标规划有问题,比如:
基数
高基数是数据库无法回避的话题。对于像 Mysql 这样的 DB,基数是指特定列或字段中收录的唯一值的数量。基数越低,列中重复的元素就越多。对于时间序列数据库,是标签、标签等标签值的个数。
例如,如果 Prometheus 中有一个指标 http_request_count{method="get",path="/abc",originIP="1.1.1.1"},则表示访问次数,method表示请求方法,originIP是客户端IP,method的枚举值是有限的,而originIP是无限的,再加上其他标签的排列组合是无限的,没有关联的特征,所以这种高基数不适合作为 Metric 标签,如果真的要提取 originIP,应该使用 log 的方式,而不是 Metric 监控
时间序列数据库对这些标签进行索引以提高查询性能,以便您可以快速找到与所有指定标签匹配的值。如果值的个数太大,索引就没有意义了,尤其是在做P95等计算的时候,需要扫描大量的Series数据
官方文档中对 Label 的建议
CAUTION: Remember that every unique combination of key-value label pairs represents a new time series, which can dramatically increase the amount of data stored. Do not use labels to store dimensions with high cardinality (many different label values), such as user IDs, email addresses, or other unbounded sets of values.
如何查看当前的Label分布,可以使用Prometheus提供的Tsdb工具。可以使用命令行查看,也可以在2.16版本以上的Prometheus Graph中查看
[work@xxx bin]$ ./tsdb analyze ../data/prometheus/
Block ID: 01E41588AJNGM31SPGHYA3XSXG
Duration: 2h0m0s
Series: 955372
Label names: 301
Postings (unique label pairs): 30757
Postings entries (total label pairs): 10842822
....
top10 高基数指标
Highest cardinality metric names:
87176 apiserver_request_latencies_bucket
59968 apiserver_response_sizes_bucket
39862 apiserver_request_duration_seconds_bucket
37555 container_tasks_state
....
高基数标签
Highest cardinality labels:
4271 resource_version
3670 id
3414 name
1857 container_id
1824 __name__
1297 uid
1276 pod
...
找到最大的指标或工作
top10 中的指标数量:按指标名称
topk(10, count by (__name__)({__name__=~".+"}))
apiserver_request_latencies_bucket{} 62544
apiserver_response_sizes_bucket{} 44600
top10中的metrics个数:按job name
topk(10, count by (__name__, job)({__name__=~".+"}))
{job="master-scrape"} 525667
{job="xxx-kubernetes-cadvisor"} 50817
{job="yyy-kubernetes-cadvisor"} 44261
Prometheus 重启慢且热重载
当 Prometheus 重启时,需要将 Wal 的内容加载到内存中。保留时间越长,Wal文件越大,实际重启的时间越长。这是普罗米修斯的机制,没有办法做到。因此,如果可以Reload,就不要重启,必须重启。会导致短期不可用,此时Prometheus的高可用就很重要了。
Prometheus 还优化了启动时间。在 2.6 版本中,优化了 Wal 的加载速度。我希望重启时间不会超过1分钟。
Prometheus 提供热加载能力,但需要启用 web.enable-lifecycle 配置。更改配置后,可以点击curl下的reload界面。默认情况下更改 prometheus-operator 中的配置将触发重新加载。如果你不使用算子,又想监控 configmap 配置变化来重新加载服务,可以试试这个简单的脚本
#!/bin/sh
FILE=$1
URL=$2
HASH=$(md5sum $(readlink -f $FILE))
while true; do
NEW_HASH=$(md5sum $(readlink -f $FILE))
if [ "$HASH" != "$NEW_HASH" ]; then
HASH="$NEW_HASH"
echo "[$(date +%s)] Trigger refresh"
curl -sSL -X POST "$2" > /dev/null
fi
sleep 5
done
使用时挂载和prometheus一样的configmap,传入如下参数:
args:
- /etc/prometheus/prometheus.yml
- http://prometheus.kube-system.svc.cluster.local:9090/-/reload
args:
- /etc/alertmanager/alertmanager.yml
- http://prometheus.kube-system.svc.cluster.local:9093/-/reload
您的应用需要公开多少指标
自己开发服务的时候,可能会暴露一些数据给metrics,比如具体请求的数量,goroutines的数量等等,多少metrics比较合适呢?
虽然指标的数量与您的应用程序的大小有关,但有一些建议(Brian Brazil),
比如缓存等简单的服务,类似于Pushgateway,有120个左右的指标。Prometheus 本身公开了大约 700 个指标。如果您的应用程序很大,请尽量不要超过 10,000 个指标。您需要合理控制您的标签。
node-exporter node-exporter不支持进程监控的问题,前面已经讲过了。node-exporter 只支持 unix 系统,windows 机器请使用 wmi_exporter。因此,当yaml形式不是node-exporter时,node-selector应该指明os类型。因为node_exporter是老组件,有一些最佳实践没有合并,比如符合Prometheus命名约定,所以推荐使用较新的0.16和0.17版本。
一些指标名称更改:
* node_cpu -> node_cpu_seconds_total
* node_memory_MemTotal -> node_memory_MemTotal_bytes
* node_memory_MemFree -> node_memory_MemFree_bytes
* node_filesystem_avail -> node_filesystem_avail_bytes
* node_filesystem_size -> node_filesystem_size_bytes
* node_disk_io_time_ms -> node_disk_io_time_seconds_total
* node_disk_reads_completed -> node_disk_reads_completed_total
* node_disk_sectors_written -> node_disk_written_bytes_total
* node_time -> node_time_seconds
* node_boot_time -> node_boot_time_seconds
* node_intr -> node_intr_total
如果之前使用过旧版本的exporter,绘制grafana时指标名称会有所不同。有两种解决方案:
kube-state-metric 的问题
kube-state-metric的使用和原理可以先阅读
除了文章中提到的功能,kube-state-metric还有一个很重要的使用场景,就是结合cadvisor metrics。原来的cadvisor只有pod信息,不知道属于哪个deployment或者sts,但是用kube-state-metric中的kube_pod_info可以在join查询后显示。kube-state-metric 的元数据索引在扩展 cadvisor 的标签方面起到了很大的作用。prometheus-operator 的许多记录规则使用 kube-state-metric 进行组合查询。
Pod 的标签信息也可以在 kube-state-metric 中展示,这样可以在获取 cadvisor 数据后进行分组更方便,比如根据 Pod 的运行环境进行分类。但是,kube-state-metric 不会暴露 pod 的注释。原因是下面提到的高基数问题,即注解的内容太多,不适合作为指标暴露。
relabel_configs 和 metric_relabel_configs
relabel_config 出现在 采集 之前,metric_relabel_configs 出现在 采集 之后。合理的组合可以满足很多场景的配置。
喜欢:
metric_relabel_configs:
- separator: ;
regex: instance
replacement: $1
action: labeldrop
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_endpoints_name,
__meta_kubernetes_service_annotation_prometheus_io_port]
separator: ;
regex: (.+);(.+);(.*)
target_label: __metrics_path__
replacement: /api/v1/namespaces/${1}/services/${2}:${3}/proxy/metrics
action: replace
Prometheus 的预测能力
场景一:你的磁盘剩余空间一直在减少,减少的幅度比较均匀。您想知道达到阈值需要多长时间,并且您想在某个时刻发出警报。
场景二:你的 Pod 的内存使用量一直在增加,你想知道需要多长时间才能达到 Limit 值,并在某个时间报警,并在被杀死之前检查。
Prometheus 的 Deriv 和 Predict_Linear 方法可以满足这样的需求。Promtheus 提供基本的预测能力,根据当前的变化率,推断一段时间后的值。
以 mem_free 为例,最近一小时 free 值一直在下降。
mem_free仅为举例,实际内存可用以mem_available为准
deriv 函数可以显示一段时间内指标的变化率:
predict_linear 方法就是根据这个速度来预测最终可达到的值:
predict_linear(mem_free{instanceIP="100.75.155.55"}[1h], 2*3600)/1024/1024
您可以根据设置设置合理的报警规则,例如小于10时报警:
<p>rule: predict_linear(mem_free{instanceIP="100.75.155.55"}[1h], 2*3600)/1024/1024
0 个评论
官方客服QQ群
在
线
客
服
action: replace
Prometheus 的预测能力
场景一:你的磁盘剩余空间一直在减少,减少的幅度比较均匀。您想知道达到阈值需要多长时间,并且您想在某个时刻发出警报。
场景二:你的 Pod 的内存使用量一直在增加,你想知道需要多长时间才能达到 Limit 值,并在某个时间报警,并在被杀死之前检查。
Prometheus 的 Deriv 和 Predict_Linear 方法可以满足这样的需求。Promtheus 提供基本的预测能力,根据当前的变化率,推断一段时间后的值。
以 mem_free 为例,最近一小时 free 值一直在下降。
mem_free仅为举例,实际内存可用以mem_available为准
deriv 函数可以显示一段时间内指标的变化率:
predict_linear 方法就是根据这个速度来预测最终可达到的值:
predict_linear(mem_free{instanceIP="100.75.155.55"}[1h], 2*3600)/1024/1024
您可以根据设置设置合理的报警规则,例如小于10时报警:
<p>rule: predict_linear(mem_free{instanceIP="100.75.155.55"}[1h], 2*3600)/1024/1024