汇总:自动采集文章网站域名(robots.txt)和实际网站地址
优采云 发布时间: 2022-10-01 21:08汇总:自动采集文章网站域名(robots.txt)和实际网站地址
自动采集文章网站域名(robots.txt)和实际网站地址,采集完成后,在浏览器端解析域名,链接到指定网站,就可以正常访问了。对于robots文件,必须添加文件才行。
一、解析a记录与url解析域名和解析url有什么区别?解析域名,指的是实际的网站地址,不是robots.txt记录里面所定义的;url是所定义的。解析域名需要添加域名,解析url不需要添加,因为url是写死的。解析域名,要获取的是真实网站的地址,而url不是网站的地址。百度也不会直接告诉你,域名被一个字符占用,解析成url的结果,是百度的服务器告诉你的。
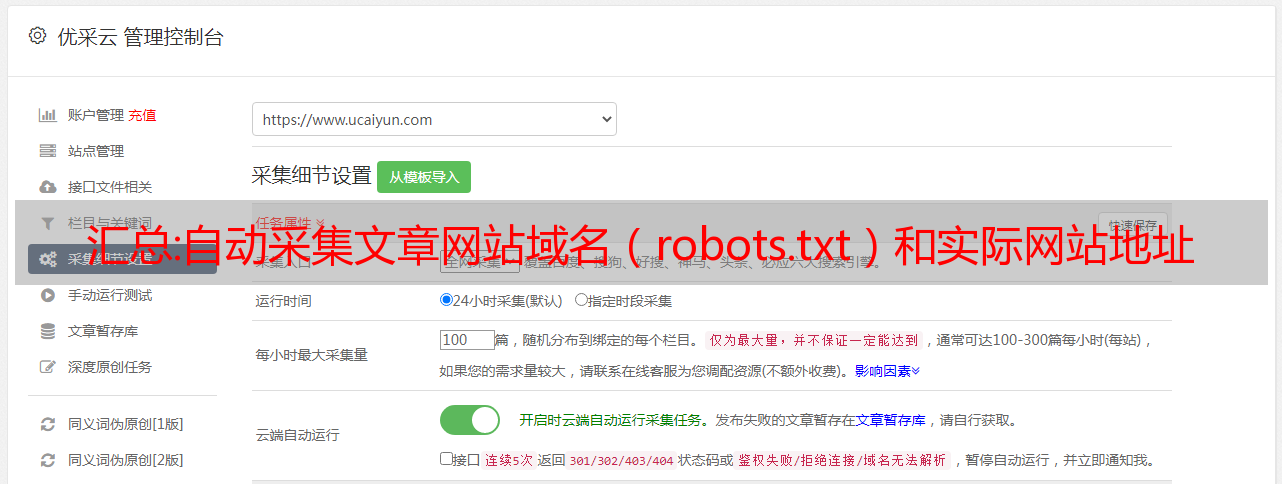
解析域名,要对应的内容,而url不是内容。解析域名要自己写,获取域名需要百度的代码实现。url不是网站的内容。
二、解析url,需要使用哪些工具?如果只是要获取网站的访问链接,就用serverify就行。如果想知道这些url是通过哪个服务器获取的,就要使用一些免费工具。
安装这些工具如下:
1、serverify
2、seepi
3、pgsqlserverify工具是利用serverify的接口,对第三方库进行获取。其他工具是自己去搜集。seepi工具是用putty工具配置a记录,爬虫。pgsqlserverify工具是自己抓包自己写sql语句。如果想使用专业爬虫工具,可以看下我的公众号:guopuyuliuzhihui。

