免费提供:免费织梦CMS文章采集器之采集聚合
优采云 发布时间: 2022-10-01 16:47免费提供:免费织梦CMS文章采集器之采集聚合
织梦CMS采集聚合之文章采集器,是基于织梦DEDECMS的网站采集和站群采集,可以根据关键词、RSS和页面监控等方式定时定量采集,进行伪原创SEO优化后更新发布,无需编写采集规则!织梦CMS采集规则之文章采集器不知道大伙有没有了解过,可能有些站长没有接触吧!采集工具一般是网站内容填充或者一些站群或者大型门户站使用的,企业站也在使用的,当然了有一些个人站也有人在用采集的,因为一些情况不想自己去更新文章或者是大站需要更新的文章多又杂,比如新闻站这些,他们都是利用采集的。
先说下织梦内容管理系统(DedeCMS) 以简单、实用、开源而闻名,是国内最知名的PHP开源网站管理系统,也是使用用户最多的PHP类CMS系统,但是相关的采集不多,很多PHP初学者在网络上到处寻找织梦CMS的采集,很多织梦CMS采集教程不是最新的、有些是收费的,有些流出来的采集教程是存储在百度云,对站长来说很不方便!关于织梦CMS类型的网站采集,织梦CMS采集规则之文章采集器完美解决了网站内容填充的问题。
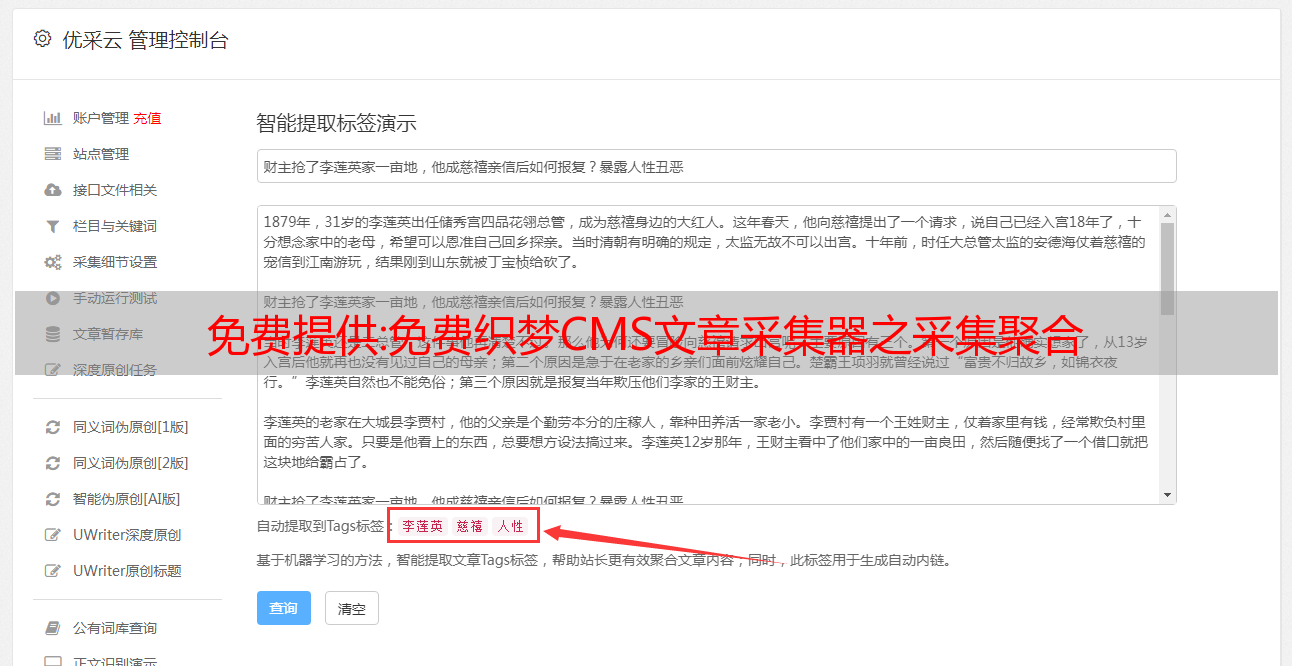
织梦文章采集器有什么优势:
无须编写采集规则设定关键词后自动采集:和传统的采集模式不同的是可以根据用户设定的关键词进行泛采集,泛采集的优势在于通过采集该关键词的不同搜索结果,实现不对指定的一个或几个被采集站点进行采集,减少采集站点被搜索引擎判定为镜像站点被搜索引擎惩罚的危险。
多种伪原创及优化方式,提高收录率及关键词排名:自动标题、段落重排、高级混淆、自动内链、内容过滤、网址过滤和同义词替换等多种方法手段增强采集文章原创性,提高搜索引擎收录、网站权重及关键词排名。
全自动采集,无需人工干预:当有用户访问网站时,触发程序运行,根据所设定的关键字通过搜索引擎(可以自定义)采集网址,然后自动抓取网页内容,程序通过精确计算分析网页,丢弃掉不是文章内容页的网址,提取出优秀文章内容,最后进行伪原创,导入,生成,这一切操作程序都是全自动完成,无需人工干预。当进行大量内容采集的时候,还可以挂在VPS服务器上采集,加快采集速度。
效果明显,网站采集首选:只需简单的进行配置即可进行自动采集发布,熟悉织梦DedeCms的站长轻松上手。
织梦CMS采集规则之文章采集器优势在于就算不在线上,都能保持网站每天都有新内容发布,因为是配置好自动发布,只要设置好了,就能定时定量更新。多种伪原创及优化方式,提高收录率及排名自动标题、段落重排、高级混淆、自动内链、内容过滤、网址过滤、同义词替换、插入seo词语、关键词添加链接等多种方法手段对采集回来的文章加工处理,增强采集文章原创性,利于搜索引擎优化,提高搜索引擎收录、网站权重及关键词排名。
织梦采集节点是织梦后台程序自动带的,采集节点是完全免费的,但是采集并不是很强大,有很多东西无法实现。
我们要知道站点基本上都是有采集需求的,身为一个SEO优化人员我们并没有那么强大的技术支持,所以只能使用一些工具来实现采集。填充内容,实现网站SEO优化,促进网站的收录,关键词的新增以及关键词排名,最终达成流量的累计,实现流量转化。
内容分享:微服务下链路追踪与日志埋点第二篇-链路追踪
上面简单解释了什么是链接跟踪和日志埋藏,以及它们想要达到什么效果。
本来主要讲的是链接的最终实现。
链接跟踪的概念
tranceID:全局基于id,可以理解为请求整个过程的唯一标识
spanID:调用者的ID,可以理解为一个链接在整个请求过程中的唯一标识
parentSpanId:调用端的父ID,即当前链接的上一个链接的标识
cs(client send):客户端发送请求标识符,
cr(client receive):客户端接收返回请求标识,两个用户计算通话结束时间。
ss(服务器发送):服务器返回请求标识符:两者用于计算服务调用的结束时间。
sr(服务器接收):服务器接收请求标识符
采样率:控制链路组接口的采样量
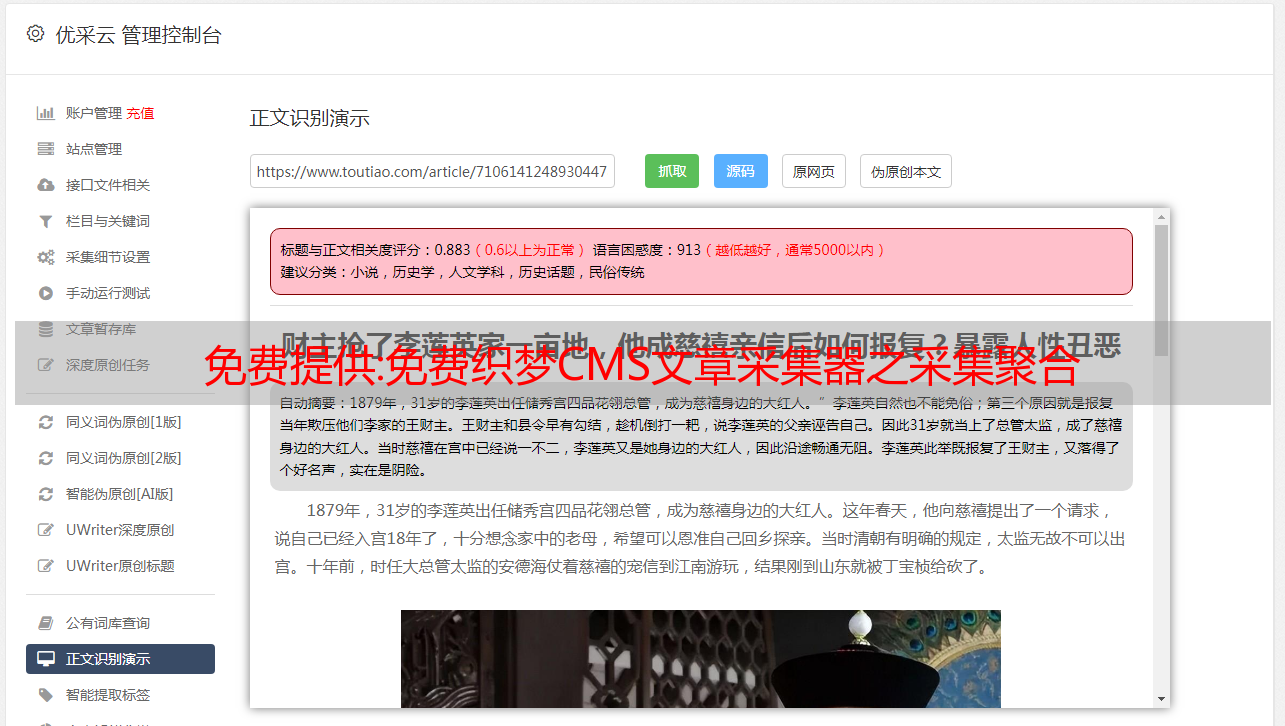
这里只提取主要概念,具体内容可以在以下地址找到
链接跟踪的基本实现
链接跟踪的框架有很多,我个人接触过的有pinpoint和zipkin。
Pinpoint 以探针的形式实现链路跟踪。虽然对代码没有侵入,但对探针开发的要求比较高。
而zipkin,作为spring-cloud-sleuth背书的解决方案,显然已经成为了我的首选。毕竟,强大的社区是一件严肃的事情,剩下的只是不必要的麻烦。
通过查看spring-could-sleuth的文档可以知道,我们可以通过依赖加载来实现链接跟踪。他会自动为我们添加tranceID和spanID到日志中,并且可以通过配置将日志发送到zipkin。链接可视化界面通过zipkin展示。我们可以配置更多的东西发送到 zipkin,比如 sql 执行状态等。【详情见官方文档】。
随着默认配置的实现,我还需要两件事
在链接跟踪中,我需要能够操纵链接上下文以添加一些自定义参数,这将为将来的页面掩埋铺平道路。在spring-cloud-sleuth中,是通过bagage来实现的。链接信息集成到ES中,可以通过zipkin实现,为后续ELK的集成提供方便。注意:上面提到的bagage不能被zipkin采集访问,但是sleuth已经想到了这个问题,并且打通了bagage和MDG和zipkin的TAG的关系,所以不用担心. 综上所述
至此,我认为上一篇文章提到的调用链埋点的问题已经解决了,我们现在有了以下能力
可以为日志埋点提供唯一标识【通过阅读spring-cloud-sleuth的文档可以知道这是通过MDC实现的】
通过zipkin获取可视化调用链提供日志嵌入的tranceID和spanID【通过阅读spring-cloud-sleuth的文档可以知道这是通过MDC实现的】提供页面嵌入添加参数的能力【通过bagage】
和平与爱

