解决方案:网页文字采集器(安美奇采集器) V1.6绿色免费版
优采云 发布时间: 2022-10-01 14:21解决方案:网页文字采集器(安美奇采集器) V1.6绿色免费版
1:按用户的要求,加入了各种常用规则,
1.1按百度关键字采集相关内容的规则
1.2搜搜关键字采集相关内容的规则,
1.3按有道关键字采集相关内容的规则,
1.4按yahoo关键字采集相关内容的规则,
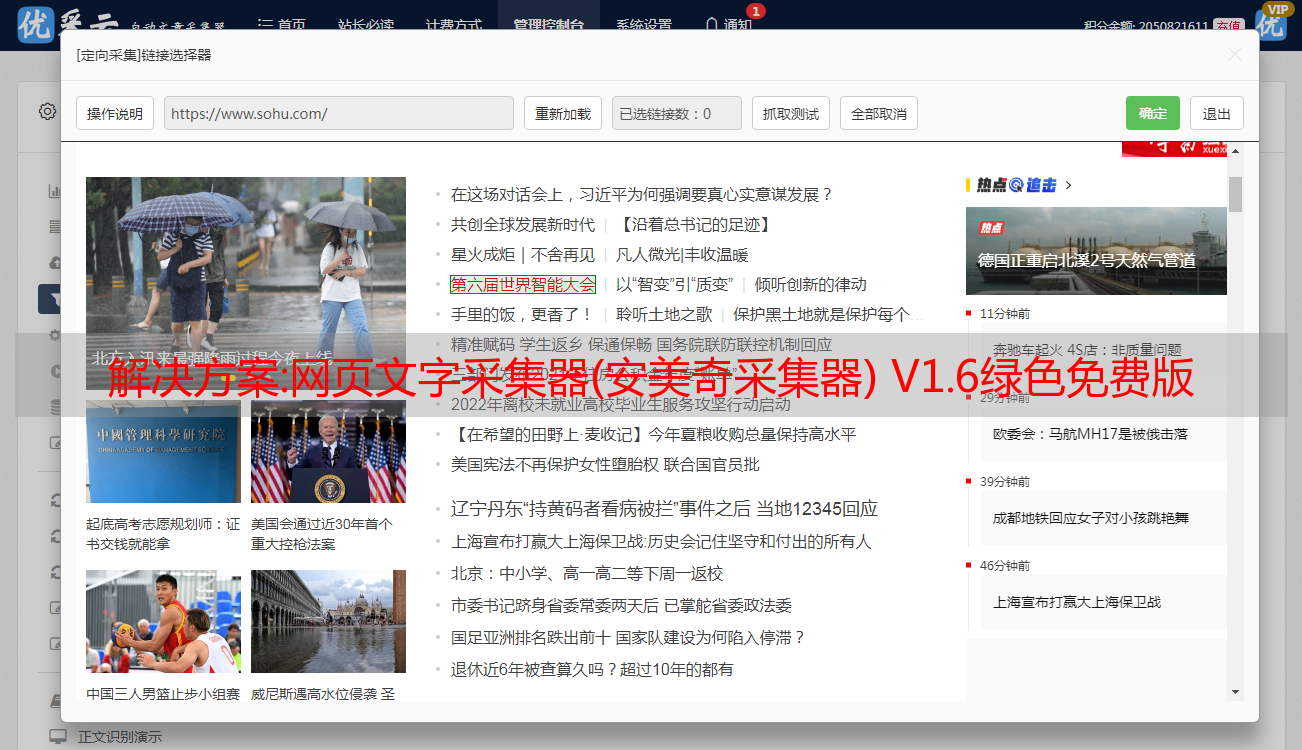
1.5按bing关键字采集相关内容的规则,
可迅速增加自身网站的内容。
2:同时支持列表类的采集,比如新闻,小说,下载之类的,都可以用本软件采集,
例子:点击"列表采集新浪规则"上面有新浪新闻的采集添写方法。
3:支持替换指定关键字,支持内容前后加入广告代码,这个大家一看就懂。
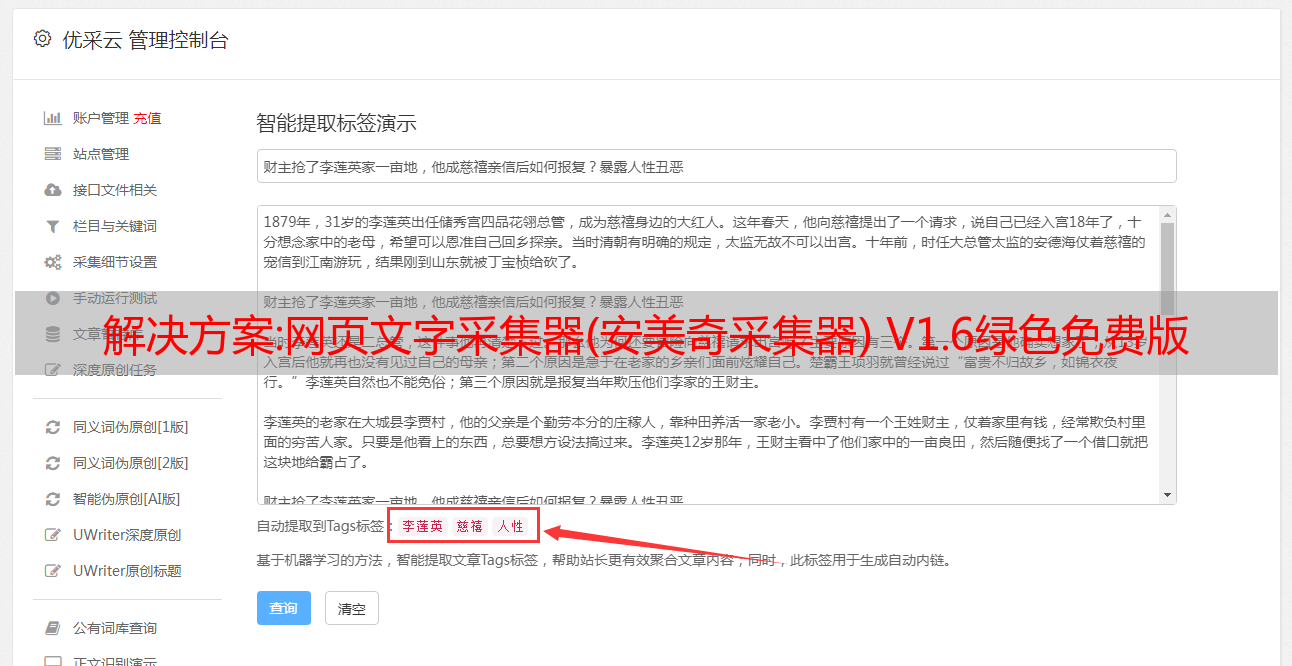
4:添加了自定义采集方式,可以自行添加采集内容和规则
5:支持大部分的语言,*敏*感*词*大部的网页均可采集,无国界限制。
6:此版本为免费版支持最基本的Access数据库,数据库名称不要修改,
采集内容在date.mdb中,数据库不同请采用数据库导入导出功能。
7:若无法运行请安装微软的.net framework,若无法采集,请及时更新最新版本
大纲:
百度如何识别采集站?伪原创 的?原理是什么?
百度知道大家都非常关心这个问题,我们一直在努力改进我们的技术,让用户能够更好地享受在线信息。
伪原创 并不是什么新鲜事,很多 网站 都在这样做。原因很简单,因为它节省了大量的精力和成本。
其实百度不是傻子,早就被发现了。所以,伪原创逃不过百度的眼睛。
那么问题来了,伪原创怎么能逃过百度的眼睛呢?
其实很简单,只需执行以下操作:
1.文章内容必须是原创性质。
2.文章标题需要吸引人。
3.文章 包括一些 关键词。
4.文章能够引起读者的兴趣。
1:百度采集站的识别方法是什么
百度如何识别采集站?伪原创 的?原理是什么?
百度采集站的识别方法是什么?这是一个更复杂的问题。百度可能会使用多种方法来识别采集网站。
一方面是通过综合判断页面内容、链接、代码等信息来识别采集网站。例如,如果一个页面有很多相同的内容或链接,这可能是一个 采集 站点。当然,这不是 100% 准确的站点是否是 采集 站点。因此,百度可能会使用其他方法进行识别。
另一方面是根据用户行为识别采集站。例如,如果大量用户在查看页面后不久就离开了站点,这表明用户对站点的内容不感兴趣,很可能是因为站点的内容不完整或 原创。因此,这也可以作为标识 采集 站的标记。
总之,要准确判断一个站点是否为采集 站点并不容易。最好的办法是自己测试和观察。
2:百度识别的原理是什么伪原创
百度如何识别采集站?伪原创 的?原理是什么?
百度在判断一个网页的内容是否为伪原创时,主要基于三个因素。
首先,百度将页面内容的文本长度与标题长度进行比较。如果文本长度远小于标题长度,则认为文章可能是伪原创。其次,百度会比较文章的内容与标题的相似度。如果相似度超过80%,则认为文章可能是伪原创。最后,百度还对整个网页的内容进行分词。如果出现大量重复词或词出现次数过多,也认为文章可能是伪原创。
以上三个因素是百度判断文章是否为伪原创的依据。这并不是说如果一个因素失败了,那一定是伪原创。相反,它需要以多种方式加以考虑和评估。

