测评:数据采集软件哪个好?2019数据采集软件推荐
优采云 发布时间: 2022-09-30 16:21测评:数据采集软件哪个好?2019数据采集软件推荐
数据采集软件,顾名思义,是指那些能够在互联网上快速、大量获取指定信息的软件产品。当然,很多网友更习惯称他们为“采集器”!那么,数据采集软件是什么?数据采集哪个软件比较好?针对以上问题,小编今天带来了2019年数据采集软件推荐。
1.优采云采集器
优采云采集器 是一个非常强大且易于操作的网络数据采集 工具。软件界面简洁大方,可快速自动采集导出和编辑数据。甚至网页上图片上的文字都可以解析提取,采集的内容也非常丰富。
编辑推荐:优采云采集器下载
2.优采云采集器
优采云采集器是一个非常强大的数据采集器,完美支持采集所有编码格式的网页,程序还可以自动识别网页编码,还支持所有目前主流和非主流cms、BBS等网站节目都可以通过系统的发布模块实现采集器和网站节目的完美结合。
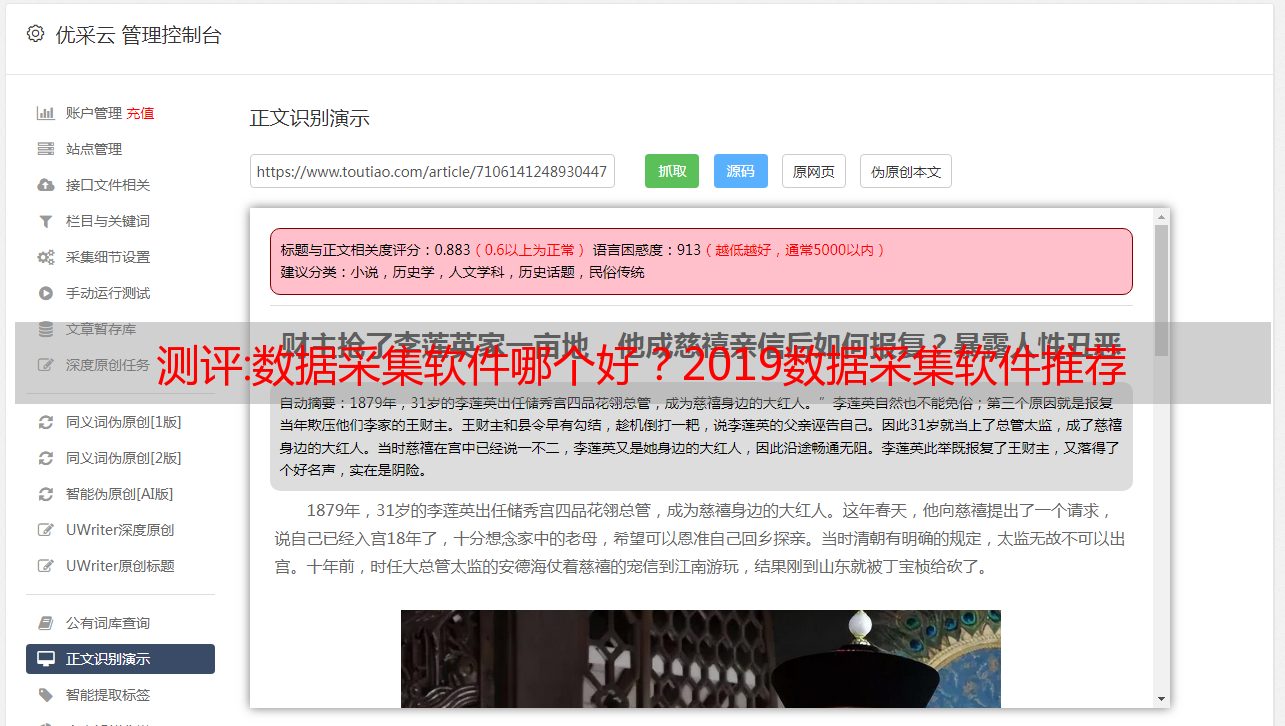
编辑推荐:优采云采集器下载
3.西蒙爱站关键词采集工具
Simon爱站关键词采集工具是一个关键词采集软件,包括爱站关键词的采集@, 爱站长尾词挖掘,可以完全自定义采集并挖掘你的词库,支持多站点多关键词、数据导出、网站登录等。
编辑推荐:Simon爱站关键词采集工具下载
4.云流媒体电影采集器
云流电影采集器可以说是影视剧的新神器。可以搜索和保存最新最热门的影视资源下载地址。用户只需要在软件中选择电影或电视剧。,点击开始工作,get即可轻松获取最新资源。
小编推荐:云流电影采集器下载
5.观察数据采集器
观看数据采集器采集规则嗅探器,只需简单的鼠标复制粘贴即可生成完美的采集规则,无需繁琐的过程。另外,软件支持采集进程断点连续获取功能,不受浏览器意外关闭影响,重启后不会重复采集;支持自动比较过滤功能,不受浏览器意外关闭的影响。链接系统不会重复采集和存储;以上两个功能可以大大减少采集时间,降低系统负载。
编辑推荐:观看资料采集器下载
最新信息:五一期间新冠疫情可视化:爬虫自动采集疫情数据及可视化
这种做法是基于丁香园发布的统计数据“链接”。通过爬虫技术,实现了2022年五一劳动节期间新冠疫情的可视化,包括疫情图、疫情增长趋势图、疫情分布图。
效果如下:
2022-05-04 当天全国现有确认数据
全国现有确认数据20220504
2022-05-04 全国累计确认数据:
上海及全国新冠病例趋势:
这是如何实现的?主要流程如下:
数据采集:
爬虫模拟浏览器-->向目标站点发送请求-->接收响应数据-->提取有用数据-->保存在本地。
requests是python实现的一个好用的http库,官网地址:
import sys
import json
import re,os
from pip import main
import requests
import datetime
import numpy as np
from pyecharts.charts import Map
from pyecharts import options as opts
from pyecharts.charts import Line
today = datetime.date.today().strftime('%Y%m%d') #20220504
COVIDA_JSON = f"./data/{today}.json"
STATICS_JSON = "./data/statistics_data.json"
def crawl_dxy_data():
"""
爬取丁香园实时统计数据,保存到data目录下,以当前日期作为文件名,存JSON文件
"""
response = requests.get('https://ncov.dxy.cn/ncovh5/view/pneumonia') #request.get()用于请求目标网站
print(response.status_code) # 打印状态码
try:
url_text = response.content.decode() #更推荐使用response.content.deocde()的方式获取响应的html页面
#print(url_text)
url_content = re.search(r'window.getAreaStat = (.*?)}]}catch', #re.search():扫描字符串以查找正则表达式模式产生匹配项的第一个位置 ,然后返回相应的match对象。
url_text, re.S) #在字符串a中,包含换行符\n,在这种情况下:如果不使用re.S参数,则只在每一行内进行匹配,如果一行没有,就换下一行重新开始;
#而使用re.S参数以后,正则表达式会将这个字符串作为一个整体,在整体中进行匹配。
texts = url_content.group() #获取匹配正则表达式的整体结果
content = texts.replace('window.getAreaStat = ', '').replace('}catch', '') #去除多余的字符
json_data = json.loads(content)
with open(COVIDA_JSON, 'w', encoding='UTF-8') as f:
json.dump(json_data, f, ensure_ascii=False)
except:
print('' % response.status_code)
def crawl_statistics_data():
"""
获取各个省份历史统计数据,保存到data目录下,存JSON文件
"""
with open(COVIDA_JSON, 'r', encoding='UTF-8') as file:
json_array = json.loads(file.read())
statistics_data = {}
for province in json_array:
response = requests.get(province['statisticsData'])
try:
statistics_data[province['provinceShortName']] = json.loads(response.content.decode())['data']
except:
print(' for url: [%s]' % (response.status_code, province['statisticsData']))
with open(STATICS_JSON, "w", encoding='UTF-8') as f:
json.dump(statistics_data, f, ensure_ascii=False)
JSON_ARRAY = None
JSON_DICT = None
<p>
DefinedCity = None
if JSON_ARRAY is None or DefinedCity is None:
JSON_ARRAY, DefinedCity, JSON_DICT = load_data()</p>
2. 疫情图
echarts 是百度开源的数据可视化工具。它以其良好的交互性和复杂的图表设计得到了许多开发人员的认可。另一方面,Python 是一种非常适合数据操作的表达性语言。当数据分析遇到数据可视化,pyecharts就诞生了。pyecharts api可以参考:#/zh-cn/chart_api
获取指定省市的疫情数据,并绘制,代码:
def RetailTimeStats(province_name:str = '上海'):
""" 获取实时 新冠数据并绘图
"""
for province in JSON_ARRAY:
if province['provinceName'] == province_name or province['provinceShortName'] == province_name:
json_array_province = province['cities']
result = [(city['cityName'], city['confirmedCount']) for city in json_array_province]
result = sorted(result, key=lambda x: x[1], reverse=True)
labels = [data[0] for data in result]
counts = [data[1] for data in result]
pieces = [
{'min': 10000, 'color': '#540d0d'},
{'max': 9999, 'min': 1000, 'color': '#9c1414'},
{'max': 999, 'min': 500, 'color': '#d92727'},
{'max': 499, 'min': 100, 'color': '#ed3232'},
{'max': 99, 'min': 10, 'color': '#f27777'},
{'max': 9, 'min': 1, 'color': '#f7adad'},
{'max': 0, 'color': '#f7e4e4'},
]
m = Map()
m.add("累计确诊", [list(z) for z in zip(labels, counts)], str(province_name))
m.set_series_opts(label_opts=opts.LabelOpts(font_size=12), is_show=False)
m.set_global_opts(title_opts=opts.TitleOpts(title=f'{province_name}实时确诊数据 - {today}',
subtitle='数据来源:丁香园'),
legend_opts=opts.LegendOpts(is_show=False),
visualmap_opts=opts.VisualMapOpts(pieces=pieces,
is_piecewise=True,
is_show=True))
m.render(path=f'./{province_name}实时确诊数据.html')
影响:
全国单日现有确诊病例:
def RetailTimeChina():
def getYesterday():
""" 昨天时间 :因为丁香园当天数据第二天才公布,所以取前一天的数据。"""
today=datetime.date.today()
oneday=datetime.timedelta(days=1)
yesterday=today-oneday
return yesterday.strftime('%Y%m%d')
statist_time = int(getYesterday())
china_data = {}
for k,v in JSON_DICT.items():
china_data[k] = []
for da in v:
if da['dateId'] >= statist_time:
currentConfirmedCount = da['currentConfirmedCount']
china_data[k].append(currentConfirmedCount)
china_data = [(k, sum(v)) for k,v in china_data.items()]
china_data = sorted(china_data, key=lambda x: x[1], reverse=True)
pieces = [
{'min': 10000, 'color': '#540d0d'},
{'max': 9999, 'min': 1000, 'color': '#9c1414'},
{'max': 999, 'min': 500, 'color': '#d92727'},
{'max': 499, 'min': 100, 'color': '#ed3232'},
{'max': 99, 'min': 10, 'color': '#f27777'},
{'max': 9, 'min': 1, 'color': '#f7adad'},
{'max': 0, 'color': '#f7e4e4'},
]
labels = [data[0] for data in china_data]
counts = [data[1] for data in china_data]
m = Map()
<p>
m.add("累计确诊", [list(z) for z in zip(labels, counts)], 'china')
#系列配置项,可配置图元样式、文字样式、标签样式、点线样式等
m.set_series_opts(label_opts=opts.LabelOpts(font_size=12),
is_show=False)
#全局配置项,可配置标题、*敏*感*词*、坐标轴、图例等
m.set_global_opts(title_opts=opts.TitleOpts(title=f'全国现存确诊数据-{statist_time}',
subtitle='数据来源:丁香园'),
legend_opts=opts.LegendOpts(is_show=False),
visualmap_opts=opts.VisualMapOpts(pieces=pieces,
is_piecewise=True, #是否为分段型
is_show=True)) #是否显示视觉映射配置
#render()会生成本地 HTML 文件,默认会在当前目录生成 render.html 文件,也可以传入路径参数,如 m.render("mycharts.html")
m.render(path=f'./全国实时确诊数据-{statist_time}.html')
</p>
流行趋势:
def CovidTrend(province_name: str='上海', statist_time = 20220201):
# 获取日期列表
dateId = [str(da['dateId'])[4:6] + '-' + str(da['dateId'])[6:8] for da in JSON_DICT[province_name] if da['dateId'] >= statist_time]
# 分析各省份2月1日至今的新增确诊数据:'confirmedIncr'
statistics__data = {}
for province in JSON_DICT:
statistics__data[province] = []
for da in JSON_DICT[province]:
if da['dateId'] >= statist_time:
statistics__data[province].append(da['confirmedIncr'])
#若当天该省数据没有更新,则默认为0
if(len(statistics__data[province])!=len(dateId)):
statistics__data[province].append(0)
# 全国新增趋势
all_statis = np.array([0] * len(dateId))
for province in statistics__data:
all_statis = all_statis + np.array(statistics__data[province])
all_statis = all_statis.tolist()
# 湖北新增趋势
hubei_statis = statistics__data[province_name]
# 湖北以外的新增趋势
other_statis = [all_statis[i] - hubei_statis[i] for i in range(len(dateId))]
line = Line()
line.add_xaxis(dateId)
line.add_yaxis("全国新增确诊病例", #图例
all_statis, #数据
is_smooth=True, #是否平滑曲线
linestyle_opts=opts.LineStyleOpts(width=4, color='#B44038'),#线样式配置项
itemstyle_opts=opts.ItemStyleOpts(color='#B44038', #图元样式配置项
border_color="#B44038", #颜色
border_width=10)) #图元的大小
line.add_yaxis(f"{province_name}新增确诊病例", hubei_statis, is_smooth=True,
linestyle_opts=opts.LineStyleOpts(width=2, color='#4E87ED'),
label_opts=opts.LabelOpts(position='bottom'), #标签在折线的底部
itemstyle_opts=opts.ItemStyleOpts(color='#4E87ED',
border_color="#4E87ED",
border_width=3))
line.add_yaxis("其他省份新增病例", other_statis, is_smooth=True,
linestyle_opts=opts.LineStyleOpts(width=2, color='#F1A846'),
label_opts=opts.LabelOpts(position='bottom'), #标签在折线的底部
itemstyle_opts=opts.ItemStyleOpts(color='#F1A846',
border_color="#F1A846",
border_width=3))
line.set_global_opts(title_opts=opts.TitleOpts(title=f"{province_name}新增确诊病例-{today}", subtitle='数据来源:丁香园'),
yaxis_opts=opts.AxisOpts(max_=16000, min_=1, type_="log", #坐标轴配置项
splitline_opts=opts.SplitLineOpts(is_show=True),#分割线配置项
axisline_opts=opts.AxisLineOpts(is_show=True)))#坐标轴刻度线配置项
line.render(path=f'./{province_name}-新增确诊趋势图.html')
北京实时新冠情况:

