完美:如何文章采集到的数据都是每个账号只能采集一条数据?
优采云 发布时间: 2022-09-30 14:17完美:如何文章采集到的数据都是每个账号只能采集一条数据?
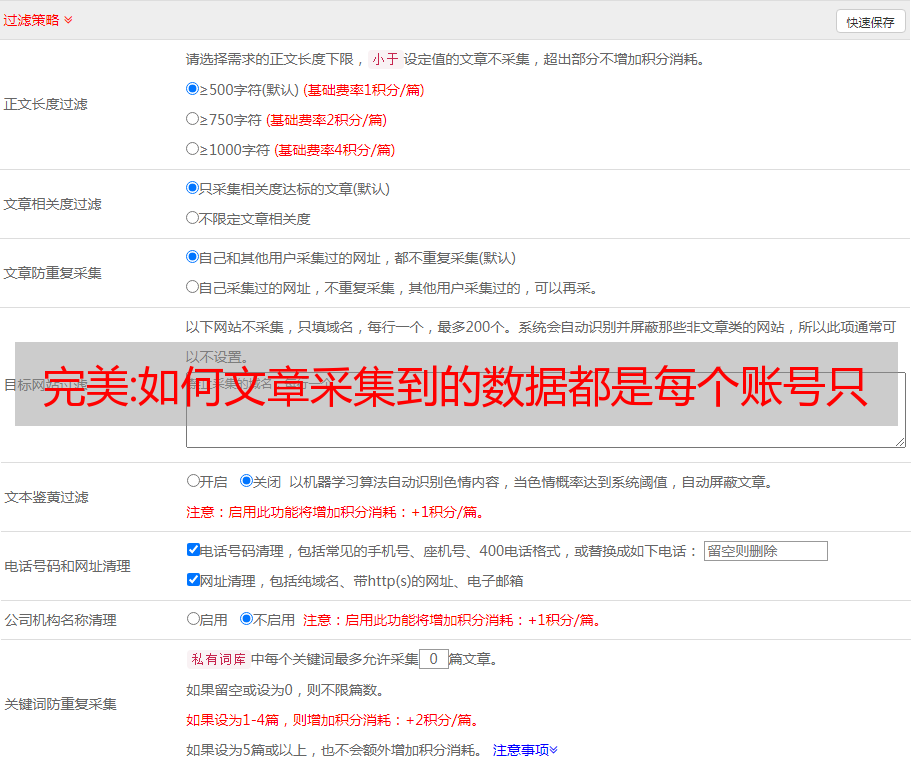
如何文章采集到的数据都是每个账号只能采集一条数据?(解决办法:1.通过爬虫软件,使用requests库和beautifulsoup库,可以自动去重。2.直接编程写爬虫软件,可能比较麻烦,建议还是在网站提供的采集界面中写程序。)采集数据的数据量、采集的次数等等是否会受限制?文章采集会不会受限制?如果你对爬虫不是特别了解,建议在网站提供的界面中写程序,先选个合适的网站,再进行采集。
请问获取网站数据的流程是怎样的?网站会根据url提供数据,比如链接之类的,用户输入信息后,会获取数据,数据来源可能是单个网站,可能是一个公众号,可能是多个。从网站获取的数据,是否会被泄露,如何规避?你获取文章的信息有可能存储在别人的服务器上,存储安全性可能存在风险。采集数据的次数没有限制,采集数据也没有次数的限制。
网站方实时在更新,如果你没有及时爬取,网站会自动停止爬取。网站一般有如下几种情况会触发爬取:1.爬取者使用了代理服务器2.爬取者出现异常或限制用户访问3.爬取者访问数据过于频繁或有一定延迟4.其他异常情况.你对爬取中碰到的问题,需要在代码中处理。采集软件只能使用windows系统操作系统。如果采集的请求参数变更,你就会需要重新安装爬虫程序,如果你爬取的请求参数变更后立刻修改,再打开爬虫爬取数据,就出现问题了。
在对网站进行采集时,有时因为数据量比较大,或者数据量相同,这种情况下,你在网站界面中写爬虫程序,可能会遇到两种情况:1.爬取数据网站有数据限制,你无法采集。2.网站方需要用到你采集后的数据,你无法操作。遇到这种情况,你可以打开代码编辑器,在控制台中对爬虫程序进行修改。爬虫程序中,在爬取部分,可以设置爬取次数,采集范围等,在爬取数据后,要同步修改,保证数据是最新的。
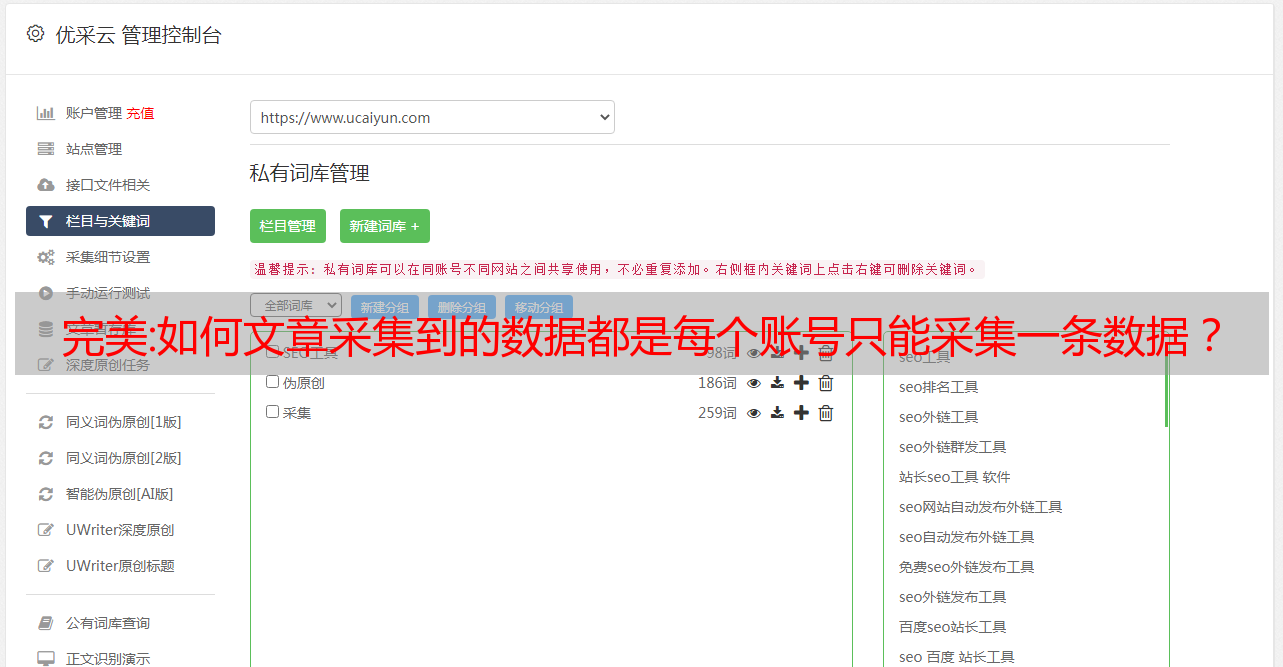
采集软件如何进行文章采集?采集软件对于文章采集的一般流程为:1.数据查找网站中是否有文章。比如搜索框中搜索文章名。2.文章查找首先我们需要下载爬虫程序,如果需要修改,则需要修改文件路径为本地的,如果你只是自己修改文件名,不修改路径,则无法保存。安装爬虫程序,为了爬取方便,可以自己修改路径,记住路径要大写,因为爬虫程序是bs4文件。
3.爬取在一次文章采集,需要同步修改路径,保证数据是最新的。你可以按照你修改的路径进行数据爬取。比如下图中的url,第一次是爬取不了的,因为搜索框没有搜索到文章信息,可以第二次爬取,或者多次的修改路径。如果你使用网站快照查找方式,是不能爬取文章的。数据提取完后,如果你有需要。

