最新版:优采云伪原创双标题生成php插件(适合各大CMS)
优采云 发布时间: 2022-09-30 12:12最新版:优采云伪原创双标题生成php插件(适合各大CMS)
插件处理后的标题:牙疼怎么办
插件优势:
插件选择的标题是搜索引擎中搜索量较大的相关标题。
补充标题可以增加文章的知名度,增加文章的搜索量
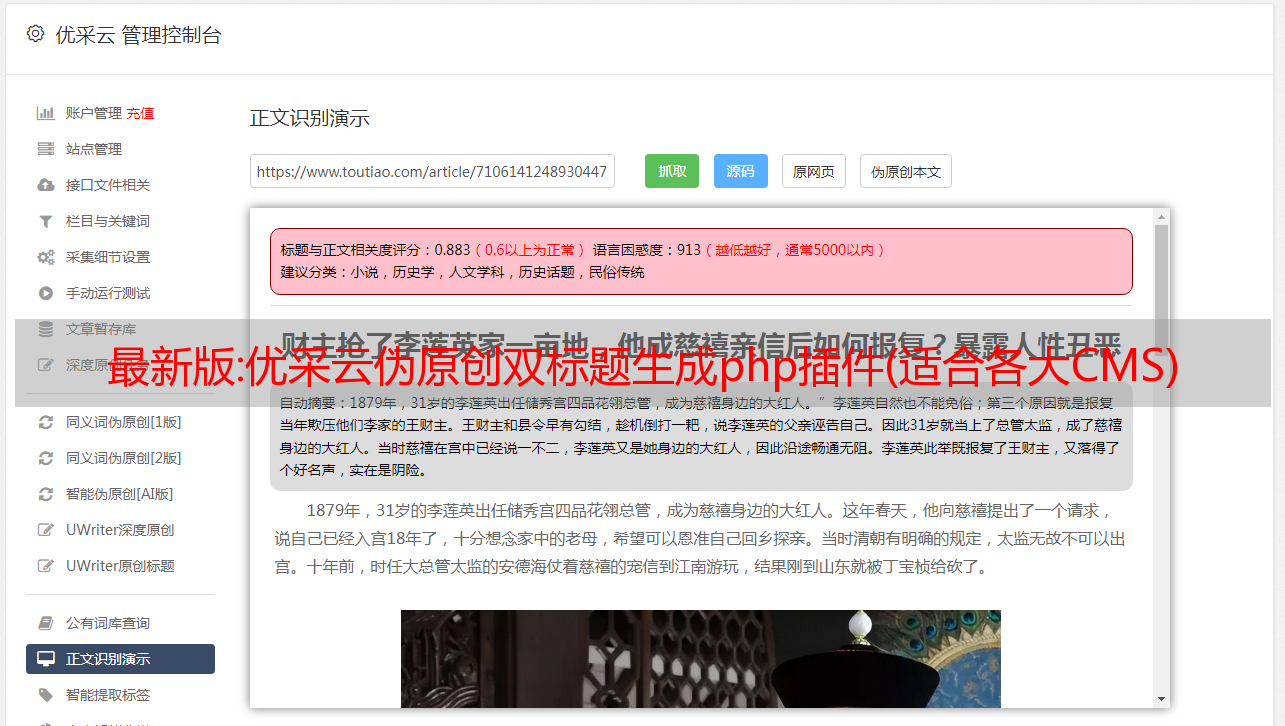
当有相关标题时,将被处理。如果没有相关标题,则保留原标题,不会出现错误信息。
指示:
下载后解压到优采云/High Speed Rail采集器的plugins文件夹
打开任意采集任务->其他设置->插件->采集结果处理插件
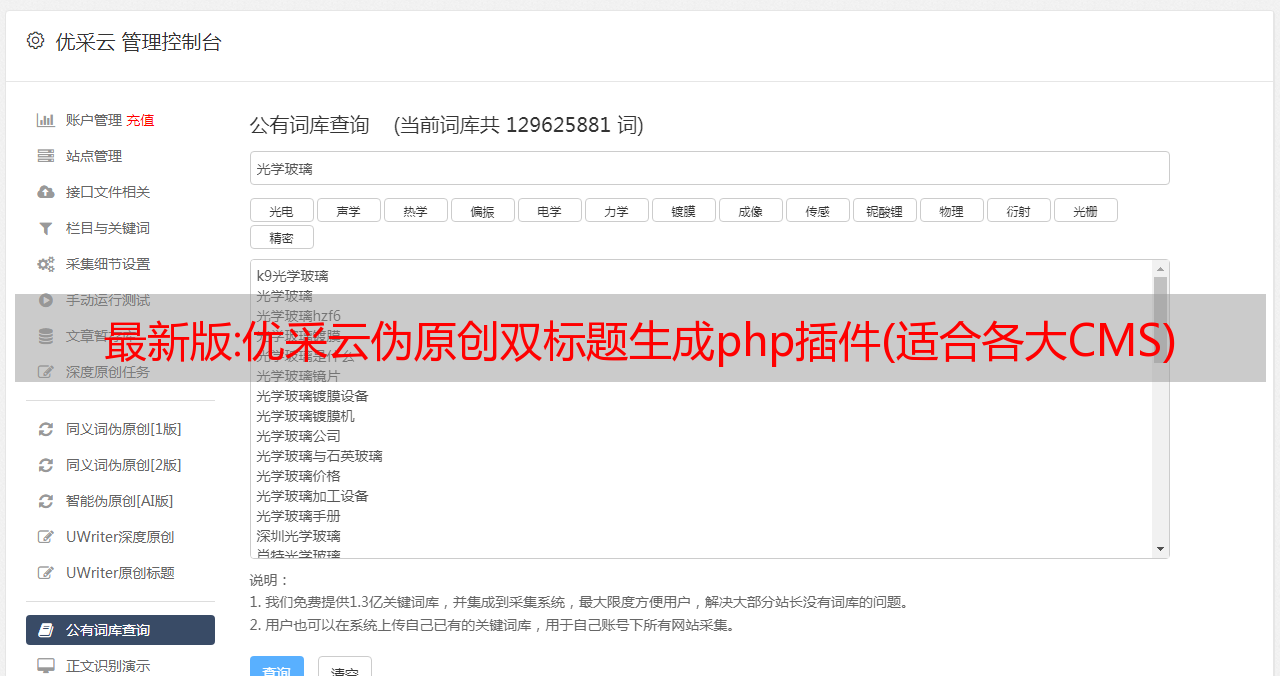
PS:结合本站的伪原创插件,效果更佳!!!!!!!优采云美文园ai伪原创插件
无加密优化版特点:
代码未加密,集成双标题生成功能。文章的内容随机插入3张以上的图片,并用title标签优化图片,内容智能伪原创!!!这个版本绝对值得拥有!
深度解析:源码剖析 - 公众号采集阅读器 Liuli
介绍
偶然发现了琉璃这个项目,项目Github:
看了它的文章,发现琉璃是用Python实现的,所以打算简单看一下它的实现细节,老规矩,看项目,先把好奇的点写下来:
是的,我对这两点很感兴趣。经过一番阅读,关于好奇心 1、其实没有人实现过漂亮的PC软件界面。琉璃只是采集,然后推送内容,所以这篇文章的重点,就看怎么了采集公众号文章,另外,在阅读的过程中,我发现LiuLi还用了一个简单的方法来识别文章是不是广告文章,这个也很有意思,也记录一下。
公众号文章采集
琉璃基于搜狗微信()对公众号文章进行采集,实现了两种方法:
我们可以通过相应的配置文件来控制琉璃使用哪种方式执行文章采集,它使用ruia默认的方式执行采集。
琉璃将功能划分为多个模块,然后通过调度器调度不同的模块。调度器启动方法代码如下:
# src/liuli_schedule.py<br /><br />def start(ll_config_name: str = ""):<br /> """调度启动函数<br /><br /> Args:<br /> task_config (dict): 调度任务配置<br /> """<br /> if not ll_config_name:<br /> freeze_support()<br /><br /> # 默认启动 liuli_config 目录下所有配置<br /> ll_config_name_list = []<br /> for each_file in os.listdir(Config.LL_CONFIG_DIR):<br /> if each_file.endswith("json"):<br /> # 加入启动列表<br /> ll_config_name_list.append(each_file.replace(".json", ""))<br /> # 进程池<br /> p = Pool(len(ll_config_name_list))<br /> for each_ll_config_name in ll_config_name_list:<br /> LOGGER.info(f"Task {each_ll_config_name} register successfully!")<br /> p.apply_async(run_liuli_schedule, args=(each_ll_config_name,))<br /> p.close()<br /> p.join()<br /><br /> else:<br /> run_liuli_schedule(ll_config_name)<br />
从代码中可以看出,调度器会启动Python进程池,然后在其中添加run_liuli_schedule异步任务。在这个异步任务中,会执行run_liuli_task方法,这是一个完整的任务流程。代码如下:
def run_liuli_task(ll_config: dict):<br /> """执行调度任务<br /><br /> Args:<br /> ll_config (dict): Liuli 任务配置<br /> """<br /> # 文章源, 用于基础查询条件<br /> doc_source: str = ll_config["doc_source"]<br /> basic_filter = {"basic_filter": {"doc_source": doc_source}}<br /> # 采集器配置<br /> collector_conf: dict = ll_config["collector"]<br /> # 处理器配置<br /> processor_conf: dict = ll_config["processor"]<br /> # 分发器配置<br /> sender_conf: dict = ll_config["sender"]<br /> sender_conf.update(basic_filter)<br /> # 备份器配置<br /> backup_conf: dict = ll_config["backup"]<br /> backup_conf.update(basic_filter)<br /><br /> # 采集器执行<br /> LOGGER.info("采集器开始执行!")<br /> for collect_type, collect_config in collector_conf.items():<br /> collect_factory(collect_type, collect_config)<br /> LOGGER.info("采集器执行完毕!")<br /> # 采集器执行<br /> LOGGER.info("处理器(after_collect): 开始执行!")<br /> for each in processor_conf["after_collect"]:<br /> func_name = each.pop("func")<br /> # 注入查询条件<br /> each.update(basic_filter)<br /> LOGGER.info(f"处理器(after_collect): {func_name} 正在执行...")<br /> processor_dict[func_name](**each)<br /> LOGGER.info("处理器(after_collect): 执行完毕!")<br /> # 分发器执行<br /> LOGGER.info("分发器开始执行!")<br /> send_doc(sender_conf)<br /> LOGGER.info("分发器执行完毕!")<br /> # 备份器执行<br /> LOGGER.info("备份器开始执行!")<br /> backup_doc(backup_conf)<br /> LOGGER.info("备份器执行完毕!")<br />
从 run_liuli_task 方法中,需要执行一个 Liuli 任务:
关于琉璃的功能大家可以阅读作者自己的文章:,这里我们只关注公众号采集的逻辑。
因为ruia和playwright实现的采集器有两种不同的方式,使用哪一种由配置文件决定,然后通过import_module方法动态导入对应的模块,然后运行模块的run方法,从而实现文章的公众号 bool:<br /> """<br /> 采集器工厂函数<br /> :param collect_type: 采集器类型<br /> :param collect_config: 采集器配置<br /> :return:<br /> """<br /> collect_status = False<br /> try:<br /> # import_module方法动态载入具体的采集模块<br /> collect_module = import_module(f"src.collector.{collect_type}")<br /> collect_status = collect_module.run(collect_config)<br /> except ModuleNotFoundError:<br /> LOGGER.error(f"采集器类型不存在 {collect_type} - {collect_config}")<br /> except Exception as e:<br /> LOGGER.error(f"采集器执行出错 {collect_type} - {collect_config} - {e}")<br /> return collect_status<br />
编剧采集模块实现
Playwright 是微软出品的自动化库。它类似于硒。它定位于网页测试,但也被人们用来获取网页信息。当然,一些前端的反爬措施,编剧是无法突破的。
与selenium相比,playwright支持python的async,性能有所提升(但还是比不上直接请求)。下面是获取公众号下最新文章的一些逻辑(完整代码太长):
async def playwright_main(wechat_name: str):<br /> """利用 playwright 获取公众号元信息,输出数据格式见上方<br /> Args:<br /> wechat_name ([str]): 公众号名称<br /> """<br /> wechat_data = {}<br /> try:<br /> async with async_playwright() as p:<br /> # browser = await p.chromium.launch(headless=False)<br /> browser = await p.chromium.launch()<br /> context = await browser.new_context(user_agent=Config.SPIDER_UA)<br /> page = await context.new_page()<br /> # 进行公众号检索<br /> await page.goto("https://weixin.sogou.com/")<br /> await page.wait_for_load_state()<br /> await page.click('input[name="query"]')<br /> await page.fill('input[name="query"]', wechat_name)<br /> await asyncio.sleep(1)<br /> await page.click("text=搜公众号")<br /> await page.wait_for_load_state()<br />
从上面的代码可以看出,playwright的用法和selenium很相似,通过自动化用户操作网站的过程可以得到对应的数据。
ruia 采集 模块实现
ruia 是一个轻量级的 Python 异步爬虫框架。因为它比较轻量级,所以我也把它的代码看成了下一篇文章文章的内容。
它的用法有点像scrapy。需要定义一个继承自ruia.Spider的子类,然后调用start方法实现对目标网站的请求,然后ruia会自动调用parse方法解析网页内容。我们来看看具体的代码,首先是入口逻辑:
def run(collect_config: dict):<br /> """微信公众号文章抓取爬虫<br /><br /> Args:<br /> collect_config (dict, optional): 采集器配置<br /> """<br /> s_nums = 0<br /> wechat_list = collect_config["wechat_list"]<br /> delta_time = collect_config.get("delta_time", 5)<br /> for wechat_name in wechat_list:<br /> SGWechatSpider.wechat_name = wechat_name<br /> SGWechatSpider.request_config = {<br /> "RETRIES": 3,<br /> "DELAY": delta_time,<br /> "TIMEOUT": 20,<br /> }<br /> sg_url = f"https://weixin.sogou.com/weixin?type=1&query={wechat_name}&ie=utf8&s_from=input&_sug_=n&_sug_type_="<br /> SGWechatSpider.start_urls = [sg_url]<br /> try:<br /> # 启动爬虫<br /> SGWechatSpider.start(middleware=ua_middleware)<br /> s_nums += 1<br /> except Exception as e:<br /> err_msg = f" 公众号->{wechat_name} 文章更新失败! 错误信息: {e}"<br /> LOGGER.error(err_msg)<br /><br /> msg = f" 微信公众号文章更新完毕({s_nums}/{len(wechat_list)})!"<br /> LOGGER.info(msg)<br />
上面代码中,爬虫是通过SGWechatSpider.start(middleware=ua_middleware)启动的,它会自动请求start_urls的url,然后回调parse方法。parse方法的代码如下:
async def parse(self, response: Response):<br /> """解析公众号原始链接数据"""<br /> html = await response.text()<br /> item_list = []<br /> async for item in SGWechatItem.get_items(html=html):<br /> if item.wechat_name == self.wechat_name:<br /> item_list.append(item)<br /> yield self.request(<br /> url=item.latest_href,<br /> metadata=item.results,<br /> # 下一个回调方法<br /> callback=self.parse_real_wechat_url,<br /> )<br /> break<br />
在parse方法中,通过self.request请求一个新的url,然后回调self.parse_real_wechat_url方法。一切都与scrapy如此相似。
至此采集模块的阅读就结束了(代码中还涉及到一些简单的数据清洗,本文不做讨论),没有特别复杂的部分,从代码来看,作者没被派去做反爬逻辑处理,搜狗微信没反爬?
广告文章标识
然后看广告文章的识别,琉璃还是会采集为广告文章,经过采集,在文章处理模块中,广告 dict:<br /> """<br /> 对文本相似度进行预测<br /> :param text: 文本<br /> :param cos_value: 阈值 默认是0.9<br /> :return:<br /> """<br /> max_pro, result = 0.0, 0<br /> for each in self.train_data:<br /> # 余弦值具体的运算逻辑<br /> cos = CosineSimilarity(self.process_text(text), each)<br /> res_dict = cos.calculate()<br /> value = res_dict["value"]<br /> # 大于等于cos_value,就返回1,则表示当前的文章是广告文章<br /> result = 1 if value >= cos_value else 0<br /> max_pro = value if value > max_pro else max_pro<br /> if result == 1:<br /> break<br /><br /> return {"result": result, "value": max_pro}<br />
余弦值的具体操作逻辑在CosineSimilarity的calculate方法中,都是和数学有关的,我就不看了。核心是判断当前文章与广告文章的相似度。可以通过TFIDF、文本聚类等算法来完成,相关库几行代码就可以搞定(所以感觉就写在这里)。
剩下的可以参考逻辑结束
琉璃是一个不错的学习项目,下一部分文章,一起来学习ruia Python轻量级异步爬虫框架的代码。

