总结:伪原创工具推荐,伪原创代写怎么月赚过万?
优采云 发布时间: 2022-09-30 06:14总结:伪原创工具推荐,伪原创代写怎么月赚过万?
我们在介绍SEO相关知识的时候提到,百度排名的一个很重要的原则就是你的网站内容在百度之前是没有的,用户阅读体验很好,所以文章@的内容> 一定是原创的内容,尤其是新手期的前三个月,更要注意文章@>的更新频率。
但是很多人就是不想写原创的文章@>,或者写不出来,所以需要用到伪原创的工具,本文将介绍几个< @伪原创 市面上的工具,文章@>伪原创 怎么更好,伪原创文章@> 怎么赚钱等等。
伪原创工具推荐与选择:
市面上有很多在线伪原创软件,比如奶盘SEO、AL在线伪原创工具,基本原理是利用系统的同义词库来替换文中的一些词,并使用收费模式,扩大同义词替换的数量,例如可以免费替换100个,付费替换300个。
还有一些SEO伪原创软件,比如我一直在用的博君伪原创,功能非常强大。除了免费,还可以提供原创文章@>的合成功能,需要的可以加我微信咨询。
懂SEO的人都知道,百度对文章@>的原创度数检测并不是全文检测。它使用在文本中搜索一些高频的关键词,然后使其给出关键词的组合,然后与关键词进行对比,在这方面,伪原创 可能会起到一点作用。
但是伪原创的工具会增加用户的阅读负担,导致跳出率高,pv低,实际上不利于排名。
伪原创如何写出更好的内容?
事实上,最好的伪原创内容必须经过自己的大脑,重新组织文章@>结构。
比如写过网赚博客,没有网赚经验,只能在老板的博客中找到对应的文章@>。如果您了解SEO知识,您就知道复制是不够的。,你要处理文章@>,可以用伪原创的软件,不过我说了,效果其实对seo不好,是为了原创< @文章 由 文章@> 编写。
而我们seo的目的不是为了原创,我们是为了排名。
于是我们看到了一篇文章文章@>,发现搜索索引还可以,于是我们就可以在脑海中过一遍,用自己的话输出。
这里有几个关键点:
一、整理原文的结构
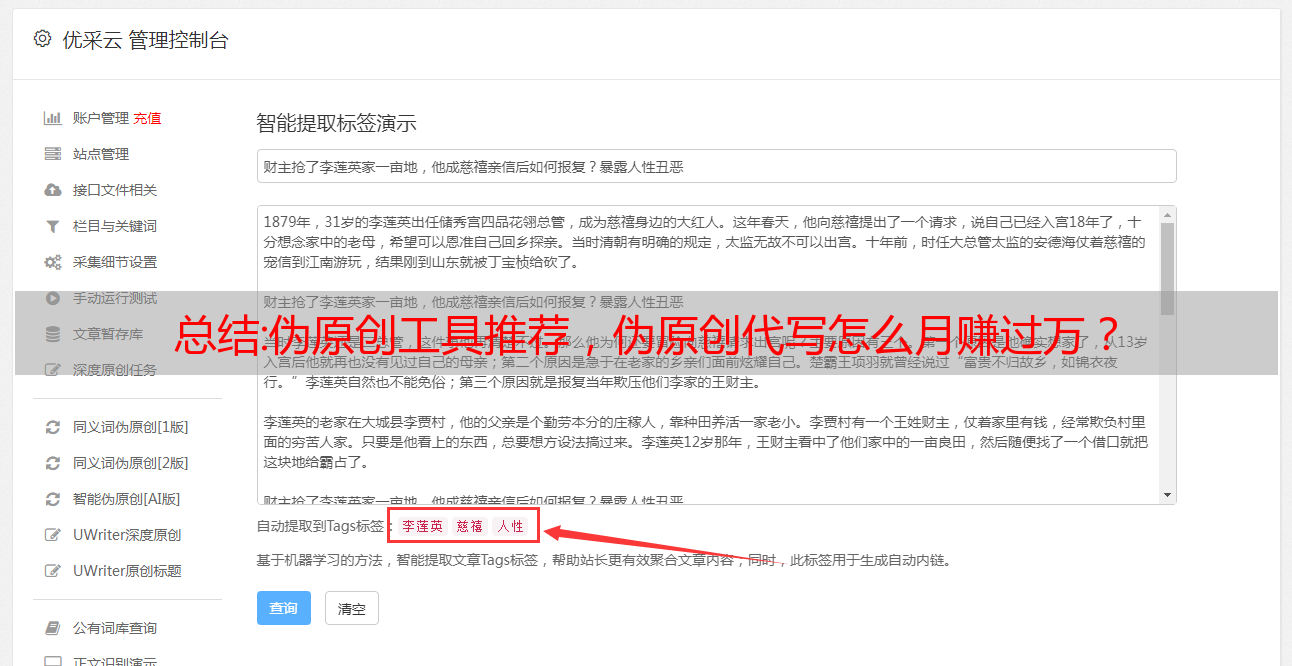
把文章@>的关键词提取出来,看看这个关键词有没有其他可以提及的关键词,比如网赚关键词,可以在线替换赚钱、网络*敏*感*词*等
根据关键词的内容和结构,整理出文章@>,然后用自己的话写出来。如果懒得写,可以只写前200字,然后用伪原创,文章@的前200字>是判断原创@程度的一个很重要的标准>。
如何使用伪原创通过技能赚钱?
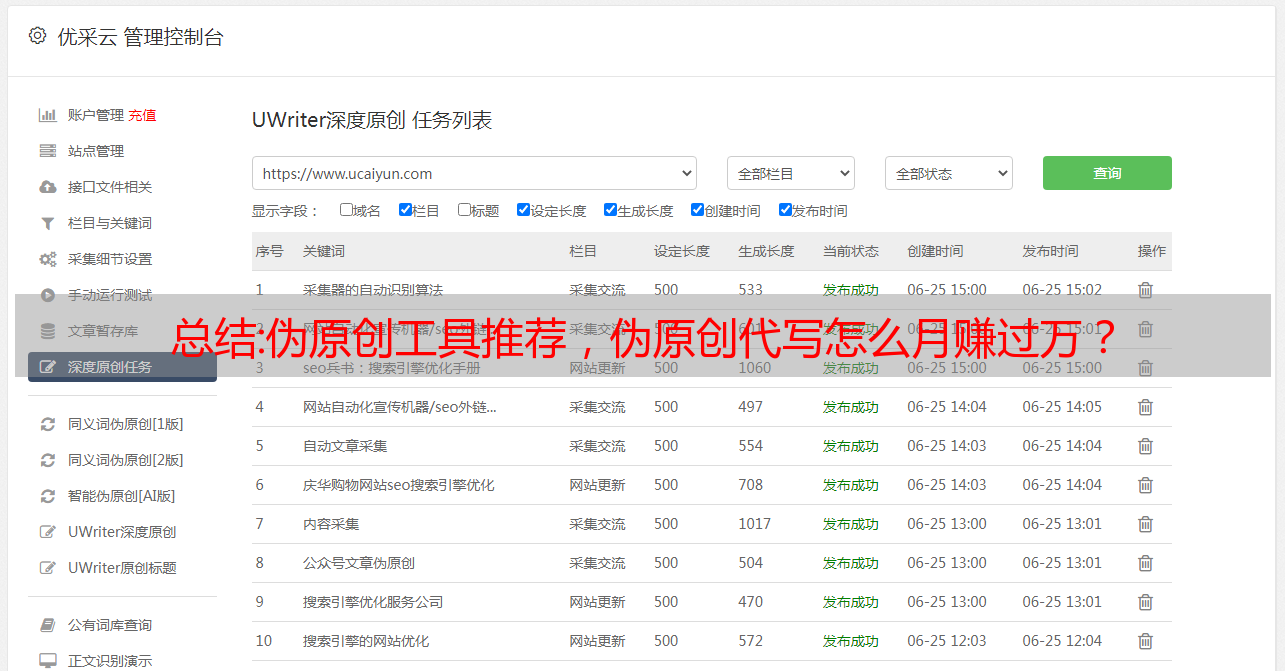
拿到这个项目后,我可能会专门为百度文章@>写网赚文章@>做一个页面提供给大家。这个思路其实和上一篇我写的百度熊掌赚钱项目是一样的。和熊掌一样,对原创文章@>的需求也是巨大的,所以我们可以利用这个需求来创造价值。一篇文章文章@>收费40元左右是没问题的。我基本上可以在30分钟内写出绝对是原创的文章@>,如果只是伪原创,15分钟左右就可以完成。
当然,这些都是赚小钱的项目。要想真正赚钱,还是得靠自己的项目,比如自己做博客,在网上赚钱。
行业见闻:我就想写个爬虫,到底要学多少东西啊?
在当今大数据时代,网络爬虫已经成为获取数据的重要手段。
但学习成为一只优秀的爬行动物并不是那么简单。首先,知识点和方向太多了。涉及计算机网络、编程基础、前端开发、后端开发、App开发与逆向工程、网络安全、数据库、运维、机器学习、数据分析等,连接了一些主流技术栈在一起就像一个大网络。因为涉及的方向很多,所以要学的东西也很分散,很乱。很多初学者不知道该学什么知识,在学习过程中不知道如何解决防爬问题。我们会做这篇文章。一些概括和总结。一些最基本的网站初级爬虫,往往没有任何反爬措施。例如,对于一个博客站点,如果我们要爬取整个站点,可以沿着列表页面爬到文章页面,然后向下爬取文章的时间、作者、文字等信息@>。如何编写代码?使用 Python 的 requests 等库就够了,写一个基本的逻辑,按照每个文章的源码,用XPath、BeautifulSoup、PyQuery或者正则表达式,或者粗鲁的字符串进行解析。匹配所需的内容,然后添加要编写的文本并保存,就完成了。代码很简单,就是几个方法调用。逻辑很简单,几个周期加存储。最后,我们可以看到文章 文章 已经保存到我们的计算机上。当然有的同学可能代码写得不是很好或者懒得写,那就用基本的可视化爬虫工具,
如果存储方面稍微扩展,可以连接 MySQL、MongoDB、Elasticsearch、Kafka 等来保存数据,实现持久化存储。以后查询或操作会更方便。反正不管效率如何,一个完全没有反爬的网站可以用最基本的方式完成。此时,你说你可以爬了吗?不,还有很长的路要走。Ajax与动态渲染随着互联网的发展,前端技术也在发生变化,数据加载的方式不再是单纯的服务器端渲染。现在可以看到很多网站数据可能是以接口的形式传输的,或者即使不是接口也是一些JSON数据,然后通过JavaScript渲染。这时候再想用requests去爬是没用的,因为request爬下来的源码是服务端渲染的,浏览器在页面上看到的结果和request得到的结果是不一样的。真实数据由 JavaScript 执行。数据源可能是ajax,也可能是页面中的一些数据,也可能是一些ifame页面等,但大多数情况下,可能是通过ajax接口获取的。因此,很多时候需要对Ajax进行分析,知道这些接口的调用方式后,再用程序进行模拟。但有些接口携带加密参数,如token、sign等,不易模拟。应该做什么?一种方法是分析网站的JavaScript逻辑,挖掘里面的代码,找出这些参数是如何构造的,找到思路后再用爬虫模拟或者重写。
如果你解决了,那么直接模拟的方法会效率更高,这需要一些 JavaScript 基础。当然,有些网站的加密逻辑太牛了,你可能要花一个星期。出来了,最后放弃了。如果想不通或不想想通,该怎么办?这时候有一种简单粗暴的方式直接模拟浏览器爬取,比如Puppeteer、Pyppeteer、Selenium、Splash等。这样爬取的源码就是真正的网页代码,数据可以被自然提取。它还绕过了分析 Ajax 和一些 JavaScript 逻辑的过程。这样一来,既能看又能爬,也不难。同时,它模拟了一个浏览器,并没有太多的法律问题。但实际上,后一种方法也会遇到各种反爬情况。现在很多网站会识别webdriver,看你用的是Selenium之类的工具,直接kill或者不返回数据,所以你摸到这种网站,我得来解决这个问题. 用单线程爬虫模拟多进程、多线程、协程的情况还是比较简单的,但是有个问题就是速度慢。爬虫是 IO 密集型任务,所以大部分情况下它可能在等待网络响应。如果网络响应速度慢,则必须一直等待。但是这个空闲时间实际上可以让CPU做更多的事情。所以你摸到这种网站,我得来解决这个问题。用单线程爬虫模拟多进程、多线程、协程的情况还是比较简单的,但是有个问题就是速度慢。爬虫是 IO 密集型任务,所以大部分情况下它可能在等待网络响应。如果网络响应速度慢,则必须一直等待。但是这个空闲时间实际上可以让CPU做更多的事情。所以你摸到这种网站,我得来解决这个问题。用单线程爬虫模拟多进程、多线程、协程的情况还是比较简单的,但是有个问题就是速度慢。爬虫是 IO 密集型任务,所以大部分情况下它可能在等待网络响应。如果网络响应速度慢,则必须一直等待。但是这个空闲时间实际上可以让CPU做更多的事情。它必须一直等待。但是这个空闲时间实际上可以让CPU做更多的事情。它必须一直等待。但是这个空闲时间实际上可以让CPU做更多的事情。
那我们该怎么办?打开更多线程。所以,这个时候,我们可以在一些场景下加入多进程和多线程。多线程虽然有GIL锁,但对爬虫影响不大,所以使用多进程多线程可以成倍增加。为了提高爬取速度,相应的库有线程和多处理。异步协程更加强大。有了aiohttp、gevent、tornado等,基本上你可以做你想做的并发,但是你要放轻松,不要让其他人网站挂掉。总之,有了这几个,爬虫的速度就会提高。但是提速不一定是好事,反爬肯定很快就会来,封IP、封账号、打验证码、返回假数据,所以有时它似乎是一个解决方案?分布式多线程、多处理、协程都可以加速,但毕竟还是单机爬虫。要真正实现规模化,我们必须依赖分布式爬虫。分布式的核心是什么?资源共享。比如爬虫队列共享、去重指纹共享等。我们可以使用一些基本的队列或者组件来实现分布式,比如RabbitMQ、Celery、Kafka、Redis等,但是经过很多人尝试实现分布式爬虫后,出现了总会有一些性能和可扩展性的问题。当然,傲慢的除外。很多公司其实都有一套自己开发的分布式爬虫,更贴近业务。当然,这是最好的。
现在主流的Python分布式爬虫还是基于Scrapy,对接Scrapy-Redis、Scrapy-Redis-BloomFilter或者使用Scrapy-Cluster等,都是基于Redis共享爬取队列的,总会多多少少遭遇。内存问题。所以也有人考虑连接其他的消息队列,比如RabbitMQ、Kafka等,解决一些问题,效率还不错。总之,要想提高爬取效率,就必须掌握分布。验证码爬虫难免会遇到反爬,验证码就是其中之一。要想爬回来,必须先解码验证码。现在可以看到很多网站都会有各种各样的验证码,比如最简单的图形验证码。如果验证码的文字是规则的,可以被OCR或者基础模型库识别。如果不想做,可以直接去编码平台做,准确率还是有的。但是,您现在可能看不到任何图形验证码。都是行为验证码,比如一个测试,一个盾牌等等。国外也有很多,比如reCaptcha等等。对于一些比较简单的,比如滑动,可以找一些方法来识别差距,比如图像处理比较,深度学习识别都是可以的。轨迹就是写一个模拟正常人的行为,加上一些jitter之类的。有了轨迹后如何模拟?如果你牛逼,那你可以直接分析验证码的JavaScript逻辑,输入轨迹数据,然后就可以在里面得到一些加密的参数,直接把这些参数放到表单或者界面中。可以直接使用。
当然也可以模拟浏览器拖动,通过某种方式获取加密参数,或者模拟浏览器直接登录,也可以用cookies爬取。当然,拖拽只是验证码,还有文字选择、逻辑推理等,如果实在不想做,可以找个编码平台解决,模拟一下,但毕竟有些专家会选择自己训练深度学习。相关模型,采集数据,标注,训练,针对不同的业务训练不同的模型。这样,有了核心技术,就不用花钱找编码平台,再研究验证码的逻辑模拟,加密参数就可以解决了。但是,有些验证码非常难,有些我无法理解。当然也可能会因为请求太频繁而弹出一些验证码,这可以通过更换IP来解决。封IP 封IP也是一件很头疼的事,最有效的办法就是换代理。代理的种类很多,市面上有免费的,收费的也太多了。首先你可以使用市面上的免费代理,自己搭建一个代理池,采集全网所有的免费代理,然后加一个测试者持续测试,测试的网址可以改成你的网址想爬。这样,通过测试的人通常可以直接用来攀登你的目标网站。我自己也建了一个代理池,现在连接了一些免费的代理,定期爬取测试,写了一个API来获取,放到GitHub上:,
付费代理也是如此。很多商家都提供了代理提取接口,一个请求就可以获得几十上百个代理。我们还可以将它们访问到代理池中。不过这个代理也分为各种套餐,开放代理、独家代理等的质量,被封杀的概率也不同。有些商家也使用隧道技术设置代理,所以我们不知道代理的地址和端口,而代理池是他们维护的,比如云,所以用起来比较省心,但是可控性较小。更差。有比较稳定的代理,比如拨号代理、蜂窝代理等,访问成本会更高一些,但也能在一定程度上解决一些IP阻塞问题。但这些事情的背后并不简单,为什么一个好的高密特工就是无缘无故爬不上去,后面的一些事情我就不说了。##Blocking a account 一些信息需要模拟登录才能爬。如果你爬得太快,人家网站会直接封你号,没啥好说的。比如你爬了公众号,如果他们屏蔽了你的WX账号,那就完蛋了。当然,一种解决方案是减慢频率并控制节奏。另一种方法是查看其他终端,例如手机页面、App页面、wap页面,看看有没有绕过登录的方法。另一种更好的方法是转移。如果你有足够的账户,建立一个池,例如 Cookies 池、Token 池、Sign 池。反正不管是哪个池子,来自多个账户的 Cookies 和 Tokens 都放到这个池子里,
如果要保持爬取效率不变,那么100个账号对比20个账号,每个账号对应的Cookies和Tokens的访问频率变成原来的1/5,因此被屏蔽的概率也随之降低。诡异的反爬上面说的是比较主流的几个反爬,当然还有很多精彩的反爬。比如返回假数据、返回图像数据、返回乱序数据、返回诅咒数据、返回求饶数据,这要看具体情况。你必须小心这些防攀爬。之前看到反爬直接返回 rm -rf / 的情况并不少见。如果碰巧有一个脚本来模拟执行并返回结果,那后果可想而知。JavaScript 逆向工程脱颖而出。随着前端技术的进步和网站反爬意识的增强,很多网站选择在前端工作,即对前端的一些逻辑或代码进行加密或混淆处理-结尾。当然,这不仅仅是为了保护前端代码不被轻易窃取,更重要的是防爬虫。比如很多Ajax接口都会携带一些参数,比如sign、token等,在上一篇文章中也提到过。我们可以使用上面提到的方法来爬取这种数据,比如Selenium,但是总的来说效率太低了。毕竟它模拟了网页渲染的全过程,真实的数据可能只是隐藏在一个小界面中。
但问题是什么?难的。webpack一方面是前端代码被压缩转码成一些bundle文件,丢失了一些变量的意义,不容易恢复。然后一些网站和一些混淆器机制会把前端代码变成你根本看不懂的东西,比如字符串拆解、变量十六进制化、控制流扁平化、无限调试、控制台被禁用等。 ,前端代码和逻辑都变的面目全非。有的使用 WebAssembly 等技术直接编译前端核心逻辑,然后只能慢慢做。虽然有些人有一定的技能,但还是需要很多时间。但是一旦你弄清楚了,一切都会好起来的。怎么说?就像奥数题,如果你解决了,就上天堂,但是你解决不了GG。很多招聘爬虫工程师的公司会问有没有JavaScript逆向基础,有哪些网站被破解了,比如某宝、某多、某篇文章等,如果找到自己需要的,可能直接雇佣你。每个网站都有不同的逻辑和难度。当然,应用爬虫不仅仅是网络爬虫。随着互联网时代的发展,越来越多的企业选择将数据放到app上,甚至有的企业只有app没有网站。所以只能通过App抓取数据。你怎么爬?基本的工具是抓包。查尔斯和提琴手可以使用班车。抓到接口后,就可以直接用它来模拟了。很多招聘爬虫工程师的公司会问有没有JavaScript逆向基础,有哪些网站被破解了,比如某宝、某多、某篇文章等,如果找到自己需要的,可能直接雇佣你。每个网站都有不同的逻辑和难度。当然,应用爬虫不仅仅是网络爬虫。随着互联网时代的发展,越来越多的企业选择将数据放到app上,甚至有的企业只有app没有网站。所以只能通过App抓取数据。你怎么爬?基本的工具是抓包。查尔斯和提琴手可以使用班车。抓到接口后,就可以直接用它来模拟了。很多招聘爬虫工程师的公司会问有没有JavaScript逆向基础,有哪些网站被破解了,比如某宝、某多、某篇文章等,如果找到自己需要的,可能直接雇佣你。每个网站都有不同的逻辑和难度。当然,应用爬虫不仅仅是网络爬虫。随着互联网时代的发展,越来越多的企业选择将数据放到app上,甚至有的企业只有app没有网站。所以只能通过App抓取数据。你怎么爬?基本的工具是抓包。查尔斯和提琴手可以使用班车。抓到接口后,就可以直接用它来模拟了。某篇文章等。如果他们发现他们需要什么,他们可能会直接雇用你。每个网站都有不同的逻辑和难度。当然,应用爬虫不仅仅是网络爬虫。随着互联网时代的发展,越来越多的企业选择将数据放到app上,甚至有的企业只有app没有网站。所以只能通过App抓取数据。你怎么爬?基本的工具是抓包。查尔斯和提琴手可以使用班车。抓到接口后,就可以直接用它来模拟了。某篇文章等。如果他们发现他们需要什么,他们可能会直接雇用你。每个网站都有不同的逻辑和难度。当然,应用爬虫不仅仅是网络爬虫。随着互联网时代的发展,越来越多的企业选择将数据放到app上,甚至有的企业只有app没有网站。所以只能通过App抓取数据。你怎么爬?基本的工具是抓包。查尔斯和提琴手可以使用班车。抓到接口后,就可以直接用它来模拟了。甚至有些公司只有没有 网站 的应用程序。所以只能通过App抓取数据。你怎么爬?基本的工具是抓包。查尔斯和提琴手可以使用班车。抓到接口后,就可以直接用它来模拟了。甚至有些公司只有没有 网站 的应用程序。所以只能通过App抓取数据。你怎么爬?基本的工具是抓包。查尔斯和提琴手可以使用班车。抓到接口后,就可以直接用它来模拟了。
如果接口有加密参数怎么办?爬取时可以处理的一种方法,例如 mitmproxy 直接*敏*感*词*接口数据。另一方面,你可以拿Hook,比如Xposed,你也可以拿到。攀爬时如何实现自动化?你不能总是得到它。其实工具很多,Android原生的adb工具也可以,Appium是现在比较主流的方案,当然还有其他的向导可以实现。最后,有时我真的不想自动化这个过程。我只是想把里面的一些接口逻辑抽出来,所以只好逆向了。IDA Pro、jdax 和 FRIDA 等工具就派上用场了。当然,这个过程和 JavaScript 逆向工程一样痛苦,甚至可能需要阅读汇编指令。它' 失去一束头发的情况并非不可能。上面的情报你们都熟悉。恭喜,你已经超过了 80% 到 90% 的爬虫玩家。当然,专门从事 JavaScript 逆向工程和 App 逆向工程的人,都是站在食物链顶端的人。据说已经不在爬虫类的范畴了,我们也不属于这种神,反正我不是。除了以上一些技巧,在某些场合,我们可能还需要结合一些机器学习技术,让我们的爬虫更加智能。例如,现在很多博客和新闻文章在页面结构和要提取的相似信息上都有比较高的相似度。例如,如何区分一个页面是索引页还是详情页?如何提取 文章 详情页的链接?如何解析文章页面的页面内容?这些实际上可以通过一些算法来计算。
因此,一些智能解析技术也被开发出来,例如提取详情页。朋友写的GeneralNewsExtractor表现很好。假设我有一个请求,我要爬10000条新闻网站数据,是不是需要一一写XPath?把我写下来。如果有智能分析技术,在容忍一定误差的情况下,几分钟就可以完成。总之,如果我们能学会这一点,我们的爬虫技术将会更加强大。运维也是一件大事。爬虫与运维也密切相关。比如写了一个爬虫后,如何快速部署到100台主机上运行。比如如何灵活监控各个爬虫的运行状态。比如爬虫有代码改动,如何快速更新它。比如,如何监控一些爬虫的占用内存和CPU消耗。比如如何科学的控制爬虫的时序,比如当爬虫出现问题时如何及时接收通知,如何设置科学的报警机制。在这里,每个人都有自己的部署方式,例如使用 Ansible,当然。如果使用Scrapy,就有Scrapyd,然后配合一些管理工具,也可以完成一些监控和定时任务。不过我现在更多的使用Docker+Kubernetes,加上一套DevOps,比如GitHub Actions、Azure Pipelines、Jenkins等,快速实现分发部署。比如爬虫出现问题时如何及时接收通知,如何设置科学的报警机制等。在这里,每个人都有自己的部署方式,例如使用 Ansible,当然。如果使用Scrapy,就有Scrapyd,然后配合一些管理工具,也可以完成一些监控和定时任务。不过我现在更多的使用Docker+Kubernetes,加上一套DevOps,比如GitHub Actions、Azure Pipelines、Jenkins等,快速实现分发部署。比如爬虫出现问题时如何及时接收通知,如何设置科学的报警机制等。在这里,每个人都有自己的部署方式,例如使用 Ansible,当然。如果使用Scrapy,就有Scrapyd,然后配合一些管理工具,也可以完成一些监控和定时任务。不过我现在更多的使用Docker+Kubernetes,加上一套DevOps,比如GitHub Actions、Azure Pipelines、Jenkins等,快速实现分发部署。
你们中的一些人使用 crontab 执行计划任务,一些人使用 apscheduler,一些人使用管理工具,还有一些人使用 Kubernetes。就我而言,我使用 Kubernetes 比较多,定时任务也很容易实现。至于监控,有很多,一些专门的爬虫管理工具自带一些监控和报警功能。一些云服务还带来了一些监控功能。我使用 Kubernetes + Prometheus + Grafana。CPU、内存、运行状态是什么,一目了然。在 Grafana 中配置报警机制也很方便,支持 Webhook、email 甚至是钉钉。对于数据存储和监控,使用Kafka和Elasticsearch非常方便。我主要用后者,然后配合Grafana,监控数据爬取量、爬取速度等一目了然。结论此时,爬虫覆盖的一些知识点几乎是一样的。怎么梳理,是否涵盖了计算机网络、编程基础、前端开发、后端开发、App开发与逆向工程、网络安全、数据库、运维、机器学习?以上总结可视为爬虫新手到爬虫高手的路径。其实每个方向都有很多可以研究的点,每一个点如果提炼出来都会非常了不起。爬虫经常学会学习,成为全栈工程师或者全职工程师,因为你可能真的什么都懂。但是没有办法。他们都是爬行动物强迫的。如果不困于生活,谁愿意成为天才?但是天赋呢?摸我的头顶,该死,我的头发呢?出色地,每个人都知道。最后一点,珍惜生命,珍惜每一根头发。
<p style="max-width: 100%;min-height: 1em;letter-spacing: 0.544px;text-align: center;widows: 1;word-spacing: 2px;color: rgb(255, 97, 149);box-sizing: border-box !important;overflow-wrap: break-word !important;">推荐阅读
<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
程序员有了孩子,老大叫玲玲,老二叫玲依,老三叫...<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
一个程序员要被打多少次脸?<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
<br style="max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
亲爱的,给我一个在看哈!</p>

