优化的解决方案:02.分布式日志采集ELK+Kafka
优采云 发布时间: 2022-09-30 04:11优化的解决方案:02.分布式日志采集ELK+Kafka
课程名称:
1.传统日记有什么缺点采集
2.elk+kafka log采集的原理
3.基于docker compose安装elk+kafka环境
4.基于AOP+并发队列实现日志采集
20:25准时开始
分布式日志采集 生成背景
在传统的项目中,如果生产环境中有多个不同的服务器集群,如果生产环境需要通过日志定位项目的Bug,就需要在每个节点上使用传统的命令查询,效率非常低。
因此,我们需要一个集中管理日志,ELK应运而生。
传统服务器搜索日志命令:tail -200f 日志文件名
ELK+Kafka组合
Elk E= ElasticSeach(存储日志信息)
l Logstash(搬运工)
K Kibana 连接到我们的 ElasticSeach GUI 以查询日志
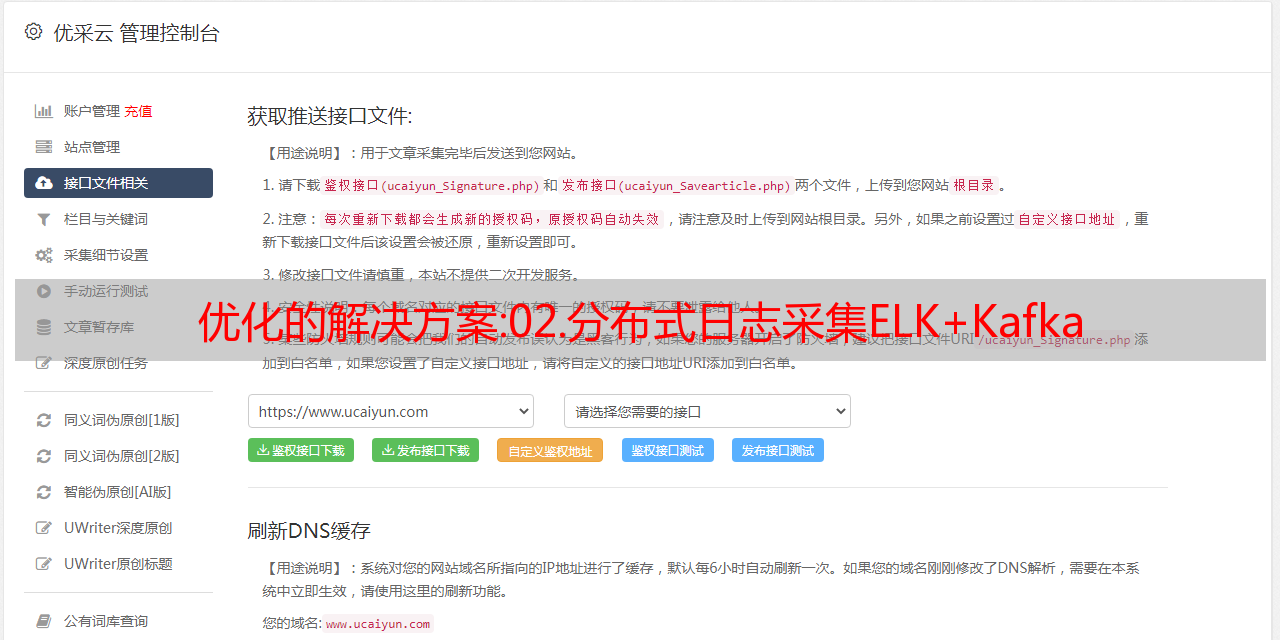
Elk+kafka 实现分布式日志采集
为什么需要将日志存储在 ElasticSeach 而不是 MySQL?
ElasticSeach 底层使用倒排索引来存储数据,在搜索日志方面比 mysql 效率更高。
elk+kafka原理
. springboot项目会基于aop拦截系统中的日志
请求和响应日志消息 - 预先或环绕通知;
优化的解决方案:02.分布式日志采集ELK+Kafka
优采云 发布时间: 2022-09-30 04:11优化的解决方案:02.分布式日志采集ELK+Kafka
课程名称:
1.传统日记有什么缺点采集
2.elk+kafka log采集的原理
3.基于docker compose安装elk+kafka环境
4.基于AOP+并发队列实现日志采集
20:25准时开始
分布式日志采集 生成背景
在传统的项目中,如果生产环境中有多个不同的服务器集群,如果生产环境需要通过日志定位项目的Bug,就需要在每个节点上使用传统的命令查询,效率非常低。
因此,我们需要一个集中管理日志,ELK应运而生。
传统服务器搜索日志命令:tail -200f 日志文件名
ELK+Kafka组合
Elk E= ElasticSeach(存储日志信息)
l Logstash(搬运工)
K Kibana 连接到我们的 ElasticSeach GUI 以查询日志
Elk+kafka 实现分布式日志采集
为什么需要将日志存储在 ElasticSeach 而不是 MySQL?
ElasticSeach 底层使用倒排索引来存储数据,在搜索日志方面比 mysql 效率更高。
elk+kafka原理
\1. springboot项目会基于aop拦截系统中的日志
请求和响应日志消息 - 预先或环绕通知;
\2. 将日志传送到我们的 kafka。请注意,该过程必须采用异步形式。如果是同步形式,会影响整体
接口的响应速度。
\3. Logstash数据源——kafka订阅kafka的topic获取日志消息内容
\4. Logstash 将日志消息内容存储在 es 中
5.开发者使用 Kibana 连接 ElasticSeach 查询存储日志内容。
为什么ELK需要和Kafka结合
如果只集成elk而没有kafka,每个服务器节点都会安装Logstash进行读写日志IO操作,可能性能不太好,是多余的。
ELK+Kafka 环境搭建 docker compose build ELK+Kafka 环境
整个环境使用docker compose搭建
注:环境cpu多核内存4GB以上
kafka环境的安装:
1.使用 docker compose 安装 kafka
如果你对 docker compose 不熟悉,可以查看:#
docker compose 安装包
Docker相关学习文档:
\2. 码头工人撰写文件
\3. mkdir dockerkakfa
4.cd dockerkakfa
5.创建 docker-compose.yml
version: '2'
services:
zookeeper:
image: wurstmeister/zookeeper
ports:
- "2181:2181"
restart: always
kafka:
image: wurstmeister/kafka:2.12-2.3.0
ports:
- "9092:9092"
environment:
- KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181
- KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.75.129:9092
- KAFKA_LISTENERS=PLAINTEXT://:9092
volumes:
- /var/run/docker.sock:/var/run/docker.sock
restart: always
kafka-manager:
image: sheepkiller/kafka-manager ## 镜像:开源的web管理kafka集群的界面
environment:
ZK_HOSTS: 192.168.75.129 ## 修改:宿主机IP
ports:
- "9001:9000" ## 暴露端口
elasticsearch:
image: daocloud.io/library/elasticsearch:6.5.4
restart: always
container_name: elasticsearch
environment:
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ports:
- 9200:9200
kibana:
image: daocloud.io/library/kibana:6.5.4
restart: always
container_name: kibana
ports:
- 5601:5601
environment:
- elasticsearch_url=http://192.168.75.129:9200
depends_on:
- elasticsearch
docker运行动物园管理员容器
docker运行kafka容器
docker 运行 kafka 容器 ElasticSeach
docker 运行 Kibana 容器
docker 运行 Logstash 容器
使用容器编排技术
6.关闭防火墙
systemctl 停止防火墙
服务 iptables 停止
7.docker-compose up 可以执行。
没有这个命令需要先安装docker-compose
注:elk+kafka环境搭建过程中,需要大量依赖镜像。
如果es启动报错:Unable to start 大多数原因是内存不足
建议虚拟机内存4G以上
es 启动错误: max virtual memory area vm.max_count(65530) is too
解决步骤:
1.先切换到root用户;
2.执行命令:
sysctl -w vm.max_map_count=262144
结果可以查看:
sysctl -a|grep vm.max_map_count
将显示以下信息:
vm.max_map_count = 262144
注意:
上面的方法修改后,如果重启虚拟机就失效了,所以:
一劳永逸的解决方案:
在 /etc/sysctl.conf 文件末尾添加一行代码:
vm.max_map_count=262144
被永久修改。
验证elk+kafka环境
码头工人ps
访问:zk 192.168.75.143:2181
访问:es:9200/
访问:kibana
安装logstash
上传logstash-6.4.3.tar.gz到服务中
tar zxvf logstash-6.4.3.tar.gz
cd logstash-6.4.3
bin/logstash-plugin install logstash-input-kafka
bin/logstash-plugin install logstash-output-elasticsearch
注意:安装
bin/logstash-plugin 安装 logstash-input-kafka
bin/logstash-plugin 安装 logstash-output-elasticsearch
本地计算机需要有JDK环境。如果没有JDK环境直接安装logstash-input-kafka或者logstash-output-elasticsearch会报错
在 logstash 配置目录中创建 kafka.conf
input {
kafka {
bootstrap_servers => "192.168.75.143:9092"
topics => "mayikt-log"
}
}
filter {
#Only matched data are send to output.
}
output {
elasticsearch {
action => "index" #The operation on ES
hosts => "192.168.75.143:9200" #ElasticSearch host, can be array.
index => "my_logs" #The index to write data to.
}
}
进入logstash bin目录,执行./logstash -f …/config/kafka.conf
springboot项目集成elk+kafka maven依赖
org.springframework.boot
spring-boot-starter-web
com.fasterxml.jackson.core
jackson-databind
org.projectlombok
lombok
provided
com.alibaba
fastjson
1.2.66
org.springframework.kafka
spring-kafka
org.springframework.boot
spring-boot-starter-aop
commons-lang
commons-lang
2.6
aop 拦截系统日志
import java.net.InetAddress;
import java.net.UnknownHostException;
import java.text.SimpleDateFormat;
import java.util.Arrays;
import java.util.Date;
import javax.servlet.http.HttpServletRequest;
import com.alibaba.fastjson.JSONObject;
import com.mayikt.container.LogContainer;
import org.aspectj.lang.JoinPoint;
import org.aspectj.lang.annotation.*;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Component;
import org.springframework.util.concurrent.ListenableFuture;
import org.springframework.web.context.request.RequestContextHolder;
import org.springframework.web.context.request.ServletRequestAttributes;
@Aspect
@Component
public class AopLogAspect {
@Value("${server.port}")
private String serverPort;
// 申明一个切点 里面是 execution表达式
@Pointcut("execution(* com.mayikt.api.service.*.*(..))")
private void serviceAspect() {
}
//
@Autowired
private LogContainer logContainer;
//
// 请求method前打印内容
@Before(value = "serviceAspect()")
public void methodBefore(JoinPoint joinPoint) {
ServletRequestAttributes requestAttributes = (ServletRequestAttributes) RequestContextHolder
.getRequestAttributes();
HttpServletRequest request = requestAttributes.getRequest();
JSONObject jsonObject = new JSONObject();
SimpleDateFormat df = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");// 设置日期格式
<p>
jsonObject.put("request_time", df.format(new Date()));
jsonObject.put("request_url", request.getRequestURL().toString());
jsonObject.put("request_method", request.getMethod());
jsonObject.put("signature", joinPoint.getSignature());
jsonObject.put("request_args", Arrays.toString(joinPoint.getArgs()));
// IP地址信息
jsonObject.put("ip_addres", getIpAddr(request) + ":" + serverPort);
JSONObject requestJsonObject = new JSONObject();
requestJsonObject.put("request", jsonObject);
jsonObject.put("request_time", df.format(new Date()));
jsonObject.put("log_type", "info");
// 将日志信息投递到kafka中
String log = requestJsonObject.toJSONString();
// ListenableFuture send = kafkaTemplate.send("mayikt-log",ctx);
logContainer.addLog(log);
}
//
// // 在方法执行完结后打印返回内容
// @AfterReturning(returning = "o", pointcut = "serviceAspect()")
// public void methodAfterReturing(Object o) {
// ServletRequestAttributes requestAttributes = (ServletRequestAttributes) RequestContextHolder
// .getRequestAttributes();
// HttpServletRequest request = requestAttributes.getRequest();
// JSONObject respJSONObject = new JSONObject();
// JSONObject jsonObject = new JSONObject();
// SimpleDateFormat df = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");// 设置日期格式
// jsonObject.put("response_time", df.format(new Date()));
// jsonObject.put("response_content", JSONObject.toJSONString(o));
// // IP地址信息
// jsonObject.put("ip_addres", getIpAddr(request) + ":" + serverPort);
// jsonObject.put("log_type", "info");
// respJSONObject.put("response", jsonObject);
// // 将日志信息投递到kafka中
kafkaTemplate.send("mayikt-log",respJSONObject.toJSONString());
logContainer.put(respJSONObject.toJSONString());
// }
//
//
/**
* 异常通知
*
* @param point
*/
@AfterThrowing(pointcut = "serviceAspect()", throwing = "e")
public void serviceAspect(JoinPoint point, Exception e) {
ServletRequestAttributes requestAttributes = (ServletRequestAttributes) RequestContextHolder
.getRequestAttributes();
HttpServletRequest request = requestAttributes.getRequest();
JSONObject jsonObject = new JSONObject();
SimpleDateFormat df = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");// 设置日期格式
jsonObject.put("request_time", df.format(new Date()));
jsonObject.put("request_url", request.getRequestURL().toString());
jsonObject.put("request_method", request.getMethod());
jsonObject.put("signature", point.getSignature());
jsonObject.put("request_args", Arrays.toString(point.getArgs()));
jsonObject.put("error", e.toString());
// IP地址信息
jsonObject.put("ip_addres", getIpAddr(request) + ":" + serverPort);
jsonObject.put("log_type", "info");
JSONObject requestJsonObject = new JSONObject();
requestJsonObject.put("request", jsonObject);
// 将日志信息投递到kafka中
String log = requestJsonObject.toJSONString();
logContainer.addLog(log);
}
//
public static String getIpAddr(HttpServletRequest request) {
//X-Forwarded-For(XFF)是用来识别通过HTTP代理或负载均衡方式连接到Web服务器的客户端最原始的IP地址的HTTP请求头字段。
String ipAddress = request.getHeader("x-forwarded-for");
if (ipAddress == null || ipAddress.length() == 0 || "unknown".equalsIgnoreCase(ipAddress)) {
ipAddress = request.getHeader("Proxy-Client-IP");
}
if (ipAddress == null || ipAddress.length() == 0 || "unknown".equalsIgnoreCase(ipAddress)) {
ipAddress = request.getHeader("WL-Proxy-Client-IP");
}
if (ipAddress == null || ipAddress.length() == 0 || "unknown".equalsIgnoreCase(ipAddress)) {
ipAddress = request.getRemoteAddr();
if (ipAddress.equals("127.0.0.1") || ipAddress.equals("0:0:0:0:0:0:0:1")) {
//根据网卡取本机配置的IP
InetAddress inet = null;
try {
inet = InetAddress.getLocalHost();
} catch (UnknownHostException e) {
e.printStackTrace();
}
ipAddress = inet.getHostAddress();
}
}
//对于通过多个代理的情况,第一个IP为客户端真实IP,多个IP按照','分割
if (ipAddress != null && ipAddress.length() > 15) { //"***.***.***.***".length() = 15
if (ipAddress.indexOf(",") > 0) {
ipAddress = ipAddress.substring(0, ipAddress.indexOf(","));
}
}
return ipAddress;
}
}
</p>
配置文件内容
spring:
application:
###服务的名称
name: mayikt-elkkafka
jackson:
date-format: yyyy-MM-dd HH:mm:ss
kafka:
bootstrap-servers: 192.168.75.143:9092 #指定kafka server的地址,集群配多个,中间,逗号隔开
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
consumer:
group-id: default_consumer_group #群组ID
enable-auto-commit: true
auto-commit-interval: 1000
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
server:
port: 9000
整套解决方案:中文网页自动采集与分类系统设计与实现
密级:保密期限:一锨譬工程硕士*敏*感*词*学位论文等垒号:Q 鱼B 量兰墨2姓名:王迭这专业:筮鲑王程导师:程堡主学院:筮鲑堂院20 10 年6 月本人声明成果。 尽我所收录其他人已教育机构的学何贡献均已在申请学位本人签名本人完全校攻读学位期家有关部门或可以公布学位保存、 汇编学本学位论本人签名导师签名中文网页自动采集与分类系统设计与实现摘要随着科学技术的飞速发展, 我们已经进入了数字信息化时代。 In tern et作为当今世界上最大的信息库, 也成为人们获取信息的最主要手段。 由于网络上的信息资源有着海量、 动态、 异构、 半结构化等特点, 且缺乏统一的组织和管理, 所以如何快速、 准确地从海量的信息资源中寻找到自己所需的信息已经成为网络用户需要迫切解决的一大难题。 因而基于w eb 的网络信息的采集与分类便成为人们研究的热点。传统的w eb 信息采集的目标就是尽可能多地采集信息页面, 甚至是整个w eb上的资源, 在这一过程中它并不太在意采集的顺序和被采集页面的相关主题。 这就使得所采集页面的内容过于杂乱, 其中有相当大的一部分利用率很低, 大大消耗了系统资源和网络资源。 这就需要采用有效的采集方法以减少采集网页的杂乱、 重复等情况的发生。
同时如何有效地对采集到的网页实现自动分类, 以创建更为有效、 快捷的搜索引擎也是非常必要的。 网页分类是组织和管理信息的有效手段, 它可以在较大程度上解决信息杂乱无章的现象, 并方便用户准确地定位所需要的信息。 传统的操作模式是对其人工分类后进行组织和管理。 随着In tern et上各种信息的迅猛增加, 仅靠人工的方式来处理是不切实际的。 因此, 网页自动分类是一项具有较大实用价值的方法, 也是组织和管理数据的有效手段。 这也是本文研究的一个重要内容。本文首先介绍了课题背景、 研究目的和*敏*感*词*的研究现状, 阐述了网页采集和网页分类的相关理论、 主要技术和算法, 包括网页爬虫技术、 网页去重技术、信息抽取技术、 中文分词技术、 特征提取技术、 网页分类技术等。 在综合比较了几种典型的算法之后, 本文选取了主题爬虫的方法和分类方面表现出色的K N N方法, 同时结合去重、 分词和特征提取等相关技术的配合, 并对中文网页的结构和特点进行了分析后, 提出中文网页采集和分类的设计与实现方法, 最后通过程序设计语言来实现, 在本文最后对系统进行了测试。 测试结果达到了系统设计的要求, 应用效果显著。
关键词: W eb 信息采集网页分类信息抽取分词特征提取卜●、▲。_D E S I G N A N DIM P L E Ⅳ匝N 1: A T IO NO FC H IN E S Ew E B P A G EA U T 0 ~IA T ICC O L L E C T I O NA N DC L A SS IF IC A T IO NA B S T R A C TW ith th er a p idd e v e lo p m e n to f scien ce a n dte c h n o lo g y , w eh a v e en tered th ed ig ita l in f o r m a tio na g e. In tem et, w h ichiS seen a s th e w o rld ’ Sla r g estin f o r m a tio nd a ta b a se. b eco m esth em a in t0 0 1o fo b ta in in gin f o rm a tio n . It iSam a jo rp r o b le mto b eso lv edu r g e n tlyh o w toq u ic k lya n da c c u r a te lyf r o mth em a ss o fin f o r m a tio nreso u rcesto f in d th e in f o r m a tio nth a t u se r s n e e d b e c a u seth e n e tw o r ko fin f o r m a tio n r e s o u r c e sh a s am assive, d ynam ic, heterog eneous, sem i—structuredch a ra cteristics, a n dth e la cko fau n if iedo r g a n iz a tio na n dm a n a g e m e n tpresents. J朊6in f o rm a tio n - ba sedco lle ctio na n d cla ssif ica tio nb e c o m e sth eresea rchh o tsp o t.T h eg o a lo f tra d itio n a l W 曲in f o r m a tio n co llectio n is tog a th erin f o r m a tio n a sm u c ha sp o ssib le , o rev enth e w h o ler e s o u r c e so nth e∥ 如功eo r d e r a n dto p icp a g e sa ren o t ca reda b o u tinth ep r o c e sso fco llectin g . th ep a g ec o n te n ts iS to o clu ttered , a n dala r g ep a r to fth emissp a rin g lyu se d S Oth a tsystemreso u rcesa n dn etw o rk reso u rcesa re w a sted . T IliS r e q u ir e s ef f ectiv eco llectio n m e th o d u se d to r e d u c e th e co llectedp a g eclu tter a n dd u p lic a tio n . T h ew e bp a g e sa r ea u to m a tica lycla ssif ica ted to c r e a teef f ectiv e a n d e伍cien t sea rchen g in e. O rg a n iza tio na n dm a na g em ento f w e bp a g ecla ssif ica tio n iS a n ef f ectiv em e a llSo fin f o rm a tio n , w h ichC a n so lv e ala rg eex ten tth ep h e n o m e n o n o f in f o r m a tio n clu tter a n d f a cilita te u sers toa ccu ra telylo ca te th ein f o r m a tio nth ey n eed . H o w ev er,th etra d itio n a lm o d e o fo p e r a tio niS m a n u a l. W ithth er a p idin c r e a sin go fa ll k in d s o fin f o r n la tio n in th eIn tem et, m a n u a lw a yto h a n d lea lo n e iS u n rea listic. T h eref o re. W ebcla ssif ica tio n is n o t am e th o dw ithg r e a tp ra ctica lv a lu e, b u ta lso is a n ef f ectiv e m ea n s o fo rg a n iz in ga n dm a n a g in gd a ta . T t is a nim p o rta n tresea rchp a rto fth ispa per.F ir stly ,th eto p icb a c k g r o u n d , p u r p o sea n dresea rch sta tu s a rein tro d u ced , a n dth eth e o r ie s, te c h n iq u e sa n da lg o rith m so f w e bp a g eco llectio n a n d cla ssif ica tio n a red escribed , w h ichin clu d s w e b c r a w le rtech n o lo g y ,d u p lica tedw e bp a g e sd e le tc io ntech n o lo g y ,in f o rm a tio ne x tr a ctio n tech n o lo g y ,C h in esew o r dseg m en ta tio n , f ea tu ree x tr a ctio nte c h n iq u e sa n d w e bp a g ecla ssif ica tio ntech n o lo g y . A co m p reh en siv eco m p a riso no f sev era lty p ica l a lg o rith m scla ssif ica tio n is selected b e ca u seth e yh a v eo u tsta n d in gp erf o rm a n ce. 111e p ro p o seda cq u isitio na n dcla ssif ica tio n o fC h in e sew e b a red esig n eda n dim plem enta teda f terth e se tech no lo g iesa r e co m b in ed a n d th e str u c tu r e a n d ch a ra cteristics o f C h in e sela n g u a g ew e bp a g ea rea n a ly zed . F in a lly ,itis co d eda n drea lizedb yth ep r o g r a m m in gla ng u a g e. T estresu lts th a tth esy stemm e tth ed esig nreq u irem en ts, a n da p p lic a tio na red o n einm a n yfeild s.iS m a d e, to p ica l cra w ler a n d K N NK e y w o r d s: w e bin f o r m a tio nc o lle c tio n , w e b p a g ecla ssif ica tio n ,in f o r m a tio nex tra ctio n , seg m en ta tio n , ch a ra cterex tra ctio n目录第一章引言……………………………………………………………………………. . . ……………11. 1课题背景及研究现状…………………………………………………………. 11. 1. 1课题的背景及研究目的…………………………………………………. . 11. 1. 2课题的*敏*感*词*研究现状……………………………………………………21. 2课题任务………………………………………………………………………. 41. 3论文结构………………………………………………………………………. 4第二章网页采集与分类相关技术介绍……………………………………………………62. 1网页爬虫技术…………………………………………………………………. 62. 1. 1通用网络爬虫………………………………………………………………62. 1. 2聚焦网络爬虫……………………………………………………………。
82. 1. 3深度网络爬虫……………………………………………………………lO2. 2中文网页信息抽取技术………………………………………………………. 112. 2. 1中文网页特点分析………………………………………………………. 112. 2. 2信息抽取关键技术………………………………………………………122. 2. 3信息抽取评价标准………………………………………………………. 132. 3网页去重技术…………………………………………………………………132. 4 中文文本分词技术……………………………………………………………. 152. 4 . 1中文分词概述……………………………………………………………l52. 4 . 2中文分词方法……………………………………………………………。 162. 5特征提取技术…………………………………………………………………192. 5. 1特征提取概述……………………………………………………………. 192. 5. 2特征提取方法……………………………………………………………202. 6 网页分类技术概述……………………………………………………………222. 7 本章小结………………………………………………………………………22第三章网页采集与分类系统设计……………………………………………………………. 233. 1系统需求分析…………………………………………………………………233. 2系统概要设计…………………………………………………………………243. 2. 1系统总体框架设计………………………………………………………243. 2. 2采集系统结构设计………………………………………………………243. 2. 3分类系统结构设计………………………………………………………253. 3系统功能模块设计……………………………………………………………263. 3. 1系统总体模块设计………………………………………………………263. 3. 2模块功能介绍……………………………………………………………273. 4 系统流程设计…………………………………………………………………283. 4 . 1采集系统流程设计设计…………………………………………………283. 4 . 2分类系统流程设计………………………………………………………293. 5系统逻辑设计…………………………………………………………………303. 5. 1采集系统类图……………………………………………………………. . 303. 5. 2分类系统类图……………………………………………………………313. 5. 3分类处理时序图…………………………………………………………313. 5系统数据库设计………………………………………………………………3. 6本章小结………………………………………………………………………第四章网页采集与分类系统实现…………………………………………………………….4 . 1页面采集模块实现……………………………………………………………4 . 2网页信息抽取模块实现………………………………………………………4 . 3网页去重模块实现…………………………………………………………….4 . 4 中文分词模块实现……………………………………………………………4 . 5特征向量提取模块实现………………………………………………………4 . 6训练语料库模块实现…………………………………………………………4 74 . 7 分类模块实现…………………………………………………………………4 84 . 7 . 1几种典型的分类算法……………………………………………………. 4 84. 7. 2K N N 算法实现分类模块…………………………………………………. 504 . 8系统开发环境配置……………………………………………………………. 524 . 9 本章小结………………………………………………………………………52第五章网页采集与分类系统测试………………厶ooooooooooooooooooooooooooooooooooooooooooooooooooo535. 1系统运行界面…………………………………………………………………535. 2实验评测标准…………………………………………………………………565. 3实验结果分析…………………………………………………………………575. 4 本章小结………………………………………………………………………59第六章结束语………………………………………………………………………………606 . 1论文工作总结…………………………………………………………………6 06 . 2问题和展望……………………………………………………………………6 0参考文献………………………………………………………………………………………。
61鸳I[谢…………………………………………………. . ……………………………………………………。 63北京邮电大学软件工程硕上论文1. 1课题背景及研究现状第一章引言1. 1. 1课题的背景及研究目的随着互联网的普及和网络技术的飞速发展, 网络上的信息资源呈指数级增长, 我们已经进入了信息化时代。 信息技术渗透到社会生活的方方面面, 人们可以从互联网上获得越来越多的包括文本、 数字、 图形、 图像、 声音、 视频等信息。然而, 随着w eb 信息的急速膨胀, 如何快速、 准确地从浩瀚的信息资源中找到自己所需的信息却成为广大网络用户的一大难题。 因而基于互联网上的信息采集和分类日益成为人们关注的焦点。.为了解决信息检索的难题, 人们先后开发了如A rch iv e、 G o o g le、 Y a h o o 等搜索引擎。 这些搜索引擎通常使用一个或多个采集器从In tem et( 如W W W 、 F T P 、E m a il、 N ew s)上采集各种数据, 然后在本地服务器上为这些数据建立索引, 当用户检索时根据用户提交的检索条件从索引库中迅速查找到所需的信息。 W eb信息采集作为这些搜索引擎的基础和组成部分, 发挥着举足轻重的作用。
w eb信息采集是指通过W e b 页面之间的链接关系, 从W e b 上自动地获取页面信息,并且随着链接不断的向所需要的w eb 页面扩展的过程。 传统的W 曲信息采集的目标就是尽可能多地采集信息页面, 甚至是整个w eb 上的资源, 在这一过程中它并不太在意采集的顺序和被采集页面的相关主题。 这样做的一个极大好处是能够集中精力在采集的速度和数量上, 并且实现起来也相对简单。 但是, 这种传统的采集方法存在着很多缺陷。 因为基于整个W eb 的信息采集需要采集的页面数量十分浩大, 这需要消耗非常大的系统资源和网络资源, 但是它们中有相当大的一部分利用率很低。 用户往往只关心其中极少量的页面, 而采集器采集的大部分页面对于他们来说是没有用的。 这显然是对系统资源和网络资源的一个巨大浪费。 随着w eb 网页数量的迅猛增长, 即使是采用了定题采集技术来构建定题搜索引擎, 同一主题的网页数量仍然是海量的。 那么如何有效地对网页实现自动分类, 以创建更为有效、 快捷的搜索引擎是非常必要的。 传统的操作模式是对其人工分类后进行组织和管理。 这种分类方法分类比较准确, 分类质量也较高。 随着In tern et上各种信息的迅速增加, 仅靠人工的方式来处理是不切实际的。
对网页进行分类可以在很大程度上解决网页上信息杂乱的现象, 并方便用户准确地定位所需要的信息, 因此, 网页自动分类是一项具有较大实用价值的方法, 也是组织和管理数据的有效手段。 这也是本文研究的一个重要内容。北京邮电大学软件工程硕士论文1. 1. 2课题的*敏*感*词*研究现状●网页采集技术发展现状网络正在不断地改变着我们的生活, In tem et已经成为当今世晃上最大的信息资源库, 如何快速、 准确地从浩瀚的信息资源库中寻找到所需的信息已经成为网络用户的一大难题。 无论是一些通用搜索引擎( 如谷歌、 百度等), 或是一些特定主题的专用网页采集系统, 都离不开网页采集, 因而基于W eb 的网页信息采集和*敏*感*词*IG o o g le、 Y a h o o 等各种搜索引擎。 这些搜索引擎通常是通过一个或多个采集器从In tern et上采集各种数据, 然后在本地服务器上为这些数据建立索引, 当用户检索时根据用户提交的检索条件从建立的索引库中迅速查找到所需信息。 传统的采集方法存在着很多缺陷。首先, 随着网页信息的爆炸式增长, 信息采集的速度越来越不能满足实际应用的需要。 即使大型的信息...
0 个评论
官方客服QQ群


在
线
客
服
接口的响应速度。
. Logstash数据源——kafka订阅kafka的topic获取日志消息内容
. Logstash 将日志消息内容存储在 es 中
5.开发者使用 Kibana 连接 ElasticSeach 查询存储日志内容。
为什么ELK需要和Kafka结合
如果只集成elk而没有kafka,每个服务器节点都会安装Logstash进行读写日志IO操作,可能性能不太好,是多余的。
ELK+Kafka 环境搭建 docker compose build ELK+Kafka 环境
整个环境使用docker compose搭建
注:环境cpu多核内存4GB以上
kafka环境的安装:
1.使用 docker compose 安装 kafka
如果你对 docker compose 不熟悉,可以查看:#
docker compose 安装包
Docker相关学习文档:
优化的解决方案:02.分布式日志采集ELK+Kafka
优采云 发布时间: 2022-09-30 04:11优化的解决方案:02.分布式日志采集ELK+Kafka
课程名称:
1.传统日记有什么缺点采集
2.elk+kafka log采集的原理
3.基于docker compose安装elk+kafka环境
4.基于AOP+并发队列实现日志采集
20:25准时开始
分布式日志采集 生成背景
在传统的项目中,如果生产环境中有多个不同的服务器集群,如果生产环境需要通过日志定位项目的Bug,就需要在每个节点上使用传统的命令查询,效率非常低。
因此,我们需要一个集中管理日志,ELK应运而生。
传统服务器搜索日志命令:tail -200f 日志文件名
ELK+Kafka组合
Elk E= ElasticSeach(存储日志信息)
l Logstash(搬运工)
K Kibana 连接到我们的 ElasticSeach GUI 以查询日志
Elk+kafka 实现分布式日志采集
为什么需要将日志存储在 ElasticSeach 而不是 MySQL?
ElasticSeach 底层使用倒排索引来存储数据,在搜索日志方面比 mysql 效率更高。
elk+kafka原理
\1. springboot项目会基于aop拦截系统中的日志
请求和响应日志消息 - 预先或环绕通知;
\2. 将日志传送到我们的 kafka。请注意,该过程必须采用异步形式。如果是同步形式,会影响整体
接口的响应速度。
\3. Logstash数据源——kafka订阅kafka的topic获取日志消息内容
\4. Logstash 将日志消息内容存储在 es 中
5.开发者使用 Kibana 连接 ElasticSeach 查询存储日志内容。
为什么ELK需要和Kafka结合
如果只集成elk而没有kafka,每个服务器节点都会安装Logstash进行读写日志IO操作,可能性能不太好,是多余的。
ELK+Kafka 环境搭建 docker compose build ELK+Kafka 环境
整个环境使用docker compose搭建
注:环境cpu多核内存4GB以上
kafka环境的安装:
1.使用 docker compose 安装 kafka
如果你对 docker compose 不熟悉,可以查看:#
docker compose 安装包
Docker相关学习文档:
\2. 码头工人撰写文件
\3. mkdir dockerkakfa
4.cd dockerkakfa
5.创建 docker-compose.yml
version: '2'
services:
zookeeper:
image: wurstmeister/zookeeper
ports:
- "2181:2181"
restart: always
kafka:
image: wurstmeister/kafka:2.12-2.3.0
ports:
- "9092:9092"
environment:
- KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181
- KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.75.129:9092
- KAFKA_LISTENERS=PLAINTEXT://:9092
volumes:
- /var/run/docker.sock:/var/run/docker.sock
restart: always
kafka-manager:
image: sheepkiller/kafka-manager ## 镜像:开源的web管理kafka集群的界面
environment:
ZK_HOSTS: 192.168.75.129 ## 修改:宿主机IP
ports:
- "9001:9000" ## 暴露端口
elasticsearch:
image: daocloud.io/library/elasticsearch:6.5.4
restart: always
container_name: elasticsearch
environment:
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ports:
- 9200:9200
kibana:
image: daocloud.io/library/kibana:6.5.4
restart: always
container_name: kibana
ports:
- 5601:5601
environment:
- elasticsearch_url=http://192.168.75.129:9200
depends_on:
- elasticsearch
docker运行动物园管理员容器
docker运行kafka容器
docker 运行 kafka 容器 ElasticSeach
docker 运行 Kibana 容器
docker 运行 Logstash 容器
使用容器编排技术
6.关闭防火墙
systemctl 停止防火墙
服务 iptables 停止
7.docker-compose up 可以执行。
没有这个命令需要先安装docker-compose
注:elk+kafka环境搭建过程中,需要大量依赖镜像。
如果es启动报错:Unable to start 大多数原因是内存不足
建议虚拟机内存4G以上
es 启动错误: max virtual memory area vm.max_count(65530) is too
解决步骤:
1.先切换到root用户;
2.执行命令:
sysctl -w vm.max_map_count=262144
结果可以查看:
sysctl -a|grep vm.max_map_count
将显示以下信息:
vm.max_map_count = 262144
注意:
上面的方法修改后,如果重启虚拟机就失效了,所以:
一劳永逸的解决方案:
在 /etc/sysctl.conf 文件末尾添加一行代码:
vm.max_map_count=262144
被永久修改。
验证elk+kafka环境
码头工人ps
访问:zk 192.168.75.143:2181
访问:es:9200/
访问:kibana
安装logstash
上传logstash-6.4.3.tar.gz到服务中
tar zxvf logstash-6.4.3.tar.gz
cd logstash-6.4.3
bin/logstash-plugin install logstash-input-kafka
bin/logstash-plugin install logstash-output-elasticsearch
注意:安装
bin/logstash-plugin 安装 logstash-input-kafka
bin/logstash-plugin 安装 logstash-output-elasticsearch
本地计算机需要有JDK环境。如果没有JDK环境直接安装logstash-input-kafka或者logstash-output-elasticsearch会报错
在 logstash 配置目录中创建 kafka.conf
input {
kafka {
bootstrap_servers => "192.168.75.143:9092"
topics => "mayikt-log"
}
}
filter {
#Only matched data are send to output.
}
output {
elasticsearch {
action => "index" #The operation on ES
hosts => "192.168.75.143:9200" #ElasticSearch host, can be array.
index => "my_logs" #The index to write data to.
}
}
进入logstash bin目录,执行./logstash -f …/config/kafka.conf
springboot项目集成elk+kafka maven依赖
org.springframework.boot
spring-boot-starter-web
com.fasterxml.jackson.core
jackson-databind
org.projectlombok
lombok
provided
com.alibaba
fastjson
1.2.66
org.springframework.kafka
spring-kafka
org.springframework.boot
spring-boot-starter-aop
commons-lang
commons-lang
2.6
aop 拦截系统日志
import java.net.InetAddress;
import java.net.UnknownHostException;
import java.text.SimpleDateFormat;
import java.util.Arrays;
import java.util.Date;
import javax.servlet.http.HttpServletRequest;
import com.alibaba.fastjson.JSONObject;
import com.mayikt.container.LogContainer;
import org.aspectj.lang.JoinPoint;
import org.aspectj.lang.annotation.*;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Component;
import org.springframework.util.concurrent.ListenableFuture;
import org.springframework.web.context.request.RequestContextHolder;
import org.springframework.web.context.request.ServletRequestAttributes;
@Aspect
@Component
public class AopLogAspect {
@Value("${server.port}")
private String serverPort;
// 申明一个切点 里面是 execution表达式
@Pointcut("execution(* com.mayikt.api.service.*.*(..))")
private void serviceAspect() {
}
//
@Autowired
private LogContainer logContainer;
//
// 请求method前打印内容
@Before(value = "serviceAspect()")
public void methodBefore(JoinPoint joinPoint) {
ServletRequestAttributes requestAttributes = (ServletRequestAttributes) RequestContextHolder
.getRequestAttributes();
HttpServletRequest request = requestAttributes.getRequest();
JSONObject jsonObject = new JSONObject();
SimpleDateFormat df = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");// 设置日期格式
<p>
jsonObject.put("request_time", df.format(new Date()));
jsonObject.put("request_url", request.getRequestURL().toString());
jsonObject.put("request_method", request.getMethod());
jsonObject.put("signature", joinPoint.getSignature());
jsonObject.put("request_args", Arrays.toString(joinPoint.getArgs()));
// IP地址信息
jsonObject.put("ip_addres", getIpAddr(request) + ":" + serverPort);
JSONObject requestJsonObject = new JSONObject();
requestJsonObject.put("request", jsonObject);
jsonObject.put("request_time", df.format(new Date()));
jsonObject.put("log_type", "info");
// 将日志信息投递到kafka中
String log = requestJsonObject.toJSONString();
// ListenableFuture send = kafkaTemplate.send("mayikt-log",ctx);
logContainer.addLog(log);
}
//
// // 在方法执行完结后打印返回内容
// @AfterReturning(returning = "o", pointcut = "serviceAspect()")
// public void methodAfterReturing(Object o) {
// ServletRequestAttributes requestAttributes = (ServletRequestAttributes) RequestContextHolder
// .getRequestAttributes();
// HttpServletRequest request = requestAttributes.getRequest();
// JSONObject respJSONObject = new JSONObject();
// JSONObject jsonObject = new JSONObject();
// SimpleDateFormat df = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");// 设置日期格式
// jsonObject.put("response_time", df.format(new Date()));
// jsonObject.put("response_content", JSONObject.toJSONString(o));
// // IP地址信息
// jsonObject.put("ip_addres", getIpAddr(request) + ":" + serverPort);
// jsonObject.put("log_type", "info");
// respJSONObject.put("response", jsonObject);
// // 将日志信息投递到kafka中
kafkaTemplate.send("mayikt-log",respJSONObject.toJSONString());
logContainer.put(respJSONObject.toJSONString());
// }
//
//
/**
* 异常通知
*
* @param point
*/
@AfterThrowing(pointcut = "serviceAspect()", throwing = "e")
public void serviceAspect(JoinPoint point, Exception e) {
ServletRequestAttributes requestAttributes = (ServletRequestAttributes) RequestContextHolder
.getRequestAttributes();
HttpServletRequest request = requestAttributes.getRequest();
JSONObject jsonObject = new JSONObject();
SimpleDateFormat df = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");// 设置日期格式
jsonObject.put("request_time", df.format(new Date()));
jsonObject.put("request_url", request.getRequestURL().toString());
jsonObject.put("request_method", request.getMethod());
jsonObject.put("signature", point.getSignature());
jsonObject.put("request_args", Arrays.toString(point.getArgs()));
jsonObject.put("error", e.toString());
// IP地址信息
jsonObject.put("ip_addres", getIpAddr(request) + ":" + serverPort);
jsonObject.put("log_type", "info");
JSONObject requestJsonObject = new JSONObject();
requestJsonObject.put("request", jsonObject);
// 将日志信息投递到kafka中
String log = requestJsonObject.toJSONString();
logContainer.addLog(log);
}
//
public static String getIpAddr(HttpServletRequest request) {
//X-Forwarded-For(XFF)是用来识别通过HTTP代理或负载均衡方式连接到Web服务器的客户端最原始的IP地址的HTTP请求头字段。
String ipAddress = request.getHeader("x-forwarded-for");
if (ipAddress == null || ipAddress.length() == 0 || "unknown".equalsIgnoreCase(ipAddress)) {
ipAddress = request.getHeader("Proxy-Client-IP");
}
if (ipAddress == null || ipAddress.length() == 0 || "unknown".equalsIgnoreCase(ipAddress)) {
ipAddress = request.getHeader("WL-Proxy-Client-IP");
}
if (ipAddress == null || ipAddress.length() == 0 || "unknown".equalsIgnoreCase(ipAddress)) {
ipAddress = request.getRemoteAddr();
if (ipAddress.equals("127.0.0.1") || ipAddress.equals("0:0:0:0:0:0:0:1")) {
//根据网卡取本机配置的IP
InetAddress inet = null;
try {
inet = InetAddress.getLocalHost();
} catch (UnknownHostException e) {
e.printStackTrace();
}
ipAddress = inet.getHostAddress();
}
}
//对于通过多个代理的情况,第一个IP为客户端真实IP,多个IP按照','分割
if (ipAddress != null && ipAddress.length() > 15) { //"***.***.***.***".length() = 15
if (ipAddress.indexOf(",") > 0) {
ipAddress = ipAddress.substring(0, ipAddress.indexOf(","));
}
}
return ipAddress;
}
}
</p>
配置文件内容
spring:
application:
###服务的名称
name: mayikt-elkkafka
jackson:
date-format: yyyy-MM-dd HH:mm:ss
kafka:
bootstrap-servers: 192.168.75.143:9092 #指定kafka server的地址,集群配多个,中间,逗号隔开
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
consumer:
group-id: default_consumer_group #群组ID
enable-auto-commit: true
auto-commit-interval: 1000
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
server:
port: 9000
整套解决方案:中文网页自动采集与分类系统设计与实现
密级:保密期限:一锨譬工程硕士*敏*感*词*学位论文等垒号:Q 鱼B 量兰墨2姓名:王迭这专业:筮鲑王程导师:程堡主学院:筮鲑堂院20 10 年6 月本人声明成果。 尽我所收录其他人已教育机构的学何贡献均已在申请学位本人签名本人完全校攻读学位期家有关部门或可以公布学位保存、 汇编学本学位论本人签名导师签名中文网页自动采集与分类系统设计与实现摘要随着科学技术的飞速发展, 我们已经进入了数字信息化时代。 In tern et作为当今世界上最大的信息库, 也成为人们获取信息的最主要手段。 由于网络上的信息资源有着海量、 动态、 异构、 半结构化等特点, 且缺乏统一的组织和管理, 所以如何快速、 准确地从海量的信息资源中寻找到自己所需的信息已经成为网络用户需要迫切解决的一大难题。 因而基于w eb 的网络信息的采集与分类便成为人们研究的热点。传统的w eb 信息采集的目标就是尽可能多地采集信息页面, 甚至是整个w eb上的资源, 在这一过程中它并不太在意采集的顺序和被采集页面的相关主题。 这就使得所采集页面的内容过于杂乱, 其中有相当大的一部分利用率很低, 大大消耗了系统资源和网络资源。 这就需要采用有效的采集方法以减少采集网页的杂乱、 重复等情况的发生。
同时如何有效地对采集到的网页实现自动分类, 以创建更为有效、 快捷的搜索引擎也是非常必要的。 网页分类是组织和管理信息的有效手段, 它可以在较大程度上解决信息杂乱无章的现象, 并方便用户准确地定位所需要的信息。 传统的操作模式是对其人工分类后进行组织和管理。 随着In tern et上各种信息的迅猛增加, 仅靠人工的方式来处理是不切实际的。 因此, 网页自动分类是一项具有较大实用价值的方法, 也是组织和管理数据的有效手段。 这也是本文研究的一个重要内容。本文首先介绍了课题背景、 研究目的和*敏*感*词*的研究现状, 阐述了网页采集和网页分类的相关理论、 主要技术和算法, 包括网页爬虫技术、 网页去重技术、信息抽取技术、 中文分词技术、 特征提取技术、 网页分类技术等。 在综合比较了几种典型的算法之后, 本文选取了主题爬虫的方法和分类方面表现出色的K N N方法, 同时结合去重、 分词和特征提取等相关技术的配合, 并对中文网页的结构和特点进行了分析后, 提出中文网页采集和分类的设计与实现方法, 最后通过程序设计语言来实现, 在本文最后对系统进行了测试。 测试结果达到了系统设计的要求, 应用效果显著。
关键词: W eb 信息采集网页分类信息抽取分词特征提取卜●、▲。_D E S I G N A N DIM P L E Ⅳ匝N 1: A T IO NO FC H IN E S Ew E B P A G EA U T 0 ~IA T ICC O L L E C T I O NA N DC L A SS IF IC A T IO NA B S T R A C TW ith th er a p idd e v e lo p m e n to f scien ce a n dte c h n o lo g y , w eh a v e en tered th ed ig ita l in f o r m a tio na g e. In tem et, w h ichiS seen a s th e w o rld ’ Sla r g estin f o r m a tio nd a ta b a se. b eco m esth em a in t0 0 1o fo b ta in in gin f o rm a tio n . It iSam a jo rp r o b le mto b eso lv edu r g e n tlyh o w toq u ic k lya n da c c u r a te lyf r o mth em a ss o fin f o r m a tio nreso u rcesto f in d th e in f o r m a tio nth a t u se r s n e e d b e c a u seth e n e tw o r ko fin f o r m a tio n r e s o u r c e sh a s am assive, d ynam ic, heterog eneous, sem i—structuredch a ra cteristics, a n dth e la cko fau n if iedo r g a n iz a tio na n dm a n a g e m e n tpresents. J朊6in f o rm a tio n - ba sedco lle ctio na n d cla ssif ica tio nb e c o m e sth eresea rchh o tsp o t.T h eg o a lo f tra d itio n a l W 曲in f o r m a tio n co llectio n is tog a th erin f o r m a tio n a sm u c ha sp o ssib le , o rev enth e w h o ler e s o u r c e so nth e∥ 如功eo r d e r a n dto p icp a g e sa ren o t ca reda b o u tinth ep r o c e sso fco llectin g . th ep a g ec o n te n ts iS to o clu ttered , a n dala r g ep a r to fth emissp a rin g lyu se d S Oth a tsystemreso u rcesa n dn etw o rk reso u rcesa re w a sted . T IliS r e q u ir e s ef f ectiv eco llectio n m e th o d u se d to r e d u c e th e co llectedp a g eclu tter a n dd u p lic a tio n . T h ew e bp a g e sa r ea u to m a tica lycla ssif ica ted to c r e a teef f ectiv e a n d e伍cien t sea rchen g in e. O rg a n iza tio na n dm a na g em ento f w e bp a g ecla ssif ica tio n iS a n ef f ectiv em e a llSo fin f o rm a tio n , w h ichC a n so lv e ala rg eex ten tth ep h e n o m e n o n o f in f o r m a tio n clu tter a n d f a cilita te u sers toa ccu ra telylo ca te th ein f o r m a tio nth ey n eed . H o w ev er,th etra d itio n a lm o d e o fo p e r a tio niS m a n u a l. W ithth er a p idin c r e a sin go fa ll k in d s o fin f o r n la tio n in th eIn tem et, m a n u a lw a yto h a n d lea lo n e iS u n rea listic. T h eref o re. W ebcla ssif ica tio n is n o t am e th o dw ithg r e a tp ra ctica lv a lu e, b u ta lso is a n ef f ectiv e m ea n s o fo rg a n iz in ga n dm a n a g in gd a ta . T t is a nim p o rta n tresea rchp a rto fth ispa per.F ir stly ,th eto p icb a c k g r o u n d , p u r p o sea n dresea rch sta tu s a rein tro d u ced , a n dth eth e o r ie s, te c h n iq u e sa n da lg o rith m so f w e bp a g eco llectio n a n d cla ssif ica tio n a red escribed , w h ichin clu d s w e b c r a w le rtech n o lo g y ,d u p lica tedw e bp a g e sd e le tc io ntech n o lo g y ,in f o rm a tio ne x tr a ctio n tech n o lo g y ,C h in esew o r dseg m en ta tio n , f ea tu ree x tr a ctio nte c h n iq u e sa n d w e bp a g ecla ssif ica tio ntech n o lo g y . A co m p reh en siv eco m p a riso no f sev era lty p ica l a lg o rith m scla ssif ica tio n is selected b e ca u seth e yh a v eo u tsta n d in gp erf o rm a n ce. 111e p ro p o seda cq u isitio na n dcla ssif ica tio n o fC h in e sew e b a red esig n eda n dim plem enta teda f terth e se tech no lo g iesa r e co m b in ed a n d th e str u c tu r e a n d ch a ra cteristics o f C h in e sela n g u a g ew e bp a g ea rea n a ly zed . F in a lly ,itis co d eda n drea lizedb yth ep r o g r a m m in gla ng u a g e. T estresu lts th a tth esy stemm e tth ed esig nreq u irem en ts, a n da p p lic a tio na red o n einm a n yfeild s.iS m a d e, to p ica l cra w ler a n d K N NK e y w o r d s: w e bin f o r m a tio nc o lle c tio n , w e b p a g ecla ssif ica tio n ,in f o r m a tio nex tra ctio n , seg m en ta tio n , ch a ra cterex tra ctio n目录第一章引言……………………………………………………………………………. . . ……………11. 1课题背景及研究现状…………………………………………………………. 11. 1. 1课题的背景及研究目的…………………………………………………. . 11. 1. 2课题的*敏*感*词*研究现状……………………………………………………21. 2课题任务………………………………………………………………………. 41. 3论文结构………………………………………………………………………. 4第二章网页采集与分类相关技术介绍……………………………………………………62. 1网页爬虫技术…………………………………………………………………. 62. 1. 1通用网络爬虫………………………………………………………………62. 1. 2聚焦网络爬虫……………………………………………………………。
82. 1. 3深度网络爬虫……………………………………………………………lO2. 2中文网页信息抽取技术………………………………………………………. 112. 2. 1中文网页特点分析………………………………………………………. 112. 2. 2信息抽取关键技术………………………………………………………122. 2. 3信息抽取评价标准………………………………………………………. 132. 3网页去重技术…………………………………………………………………132. 4 中文文本分词技术……………………………………………………………. 152. 4 . 1中文分词概述……………………………………………………………l52. 4 . 2中文分词方法……………………………………………………………。 162. 5特征提取技术…………………………………………………………………192. 5. 1特征提取概述……………………………………………………………. 192. 5. 2特征提取方法……………………………………………………………202. 6 网页分类技术概述……………………………………………………………222. 7 本章小结………………………………………………………………………22第三章网页采集与分类系统设计……………………………………………………………. 233. 1系统需求分析…………………………………………………………………233. 2系统概要设计…………………………………………………………………243. 2. 1系统总体框架设计………………………………………………………243. 2. 2采集系统结构设计………………………………………………………243. 2. 3分类系统结构设计………………………………………………………253. 3系统功能模块设计……………………………………………………………263. 3. 1系统总体模块设计………………………………………………………263. 3. 2模块功能介绍……………………………………………………………273. 4 系统流程设计…………………………………………………………………283. 4 . 1采集系统流程设计设计…………………………………………………283. 4 . 2分类系统流程设计………………………………………………………293. 5系统逻辑设计…………………………………………………………………303. 5. 1采集系统类图……………………………………………………………. . 303. 5. 2分类系统类图……………………………………………………………313. 5. 3分类处理时序图…………………………………………………………313. 5系统数据库设计………………………………………………………………3. 6本章小结………………………………………………………………………第四章网页采集与分类系统实现…………………………………………………………….4 . 1页面采集模块实现……………………………………………………………4 . 2网页信息抽取模块实现………………………………………………………4 . 3网页去重模块实现…………………………………………………………….4 . 4 中文分词模块实现……………………………………………………………4 . 5特征向量提取模块实现………………………………………………………4 . 6训练语料库模块实现…………………………………………………………4 74 . 7 分类模块实现…………………………………………………………………4 84 . 7 . 1几种典型的分类算法……………………………………………………. 4 84. 7. 2K N N 算法实现分类模块…………………………………………………. 504 . 8系统开发环境配置……………………………………………………………. 524 . 9 本章小结………………………………………………………………………52第五章网页采集与分类系统测试………………厶ooooooooooooooooooooooooooooooooooooooooooooooooooo535. 1系统运行界面…………………………………………………………………535. 2实验评测标准…………………………………………………………………565. 3实验结果分析…………………………………………………………………575. 4 本章小结………………………………………………………………………59第六章结束语………………………………………………………………………………606 . 1论文工作总结…………………………………………………………………6 06 . 2问题和展望……………………………………………………………………6 0参考文献………………………………………………………………………………………。
61鸳I[谢…………………………………………………. . ……………………………………………………。 63北京邮电大学软件工程硕上论文1. 1课题背景及研究现状第一章引言1. 1. 1课题的背景及研究目的随着互联网的普及和网络技术的飞速发展, 网络上的信息资源呈指数级增长, 我们已经进入了信息化时代。 信息技术渗透到社会生活的方方面面, 人们可以从互联网上获得越来越多的包括文本、 数字、 图形、 图像、 声音、 视频等信息。然而, 随着w eb 信息的急速膨胀, 如何快速、 准确地从浩瀚的信息资源中找到自己所需的信息却成为广大网络用户的一大难题。 因而基于互联网上的信息采集和分类日益成为人们关注的焦点。.为了解决信息检索的难题, 人们先后开发了如A rch iv e、 G o o g le、 Y a h o o 等搜索引擎。 这些搜索引擎通常使用一个或多个采集器从In tem et( 如W W W 、 F T P 、E m a il、 N ew s)上采集各种数据, 然后在本地服务器上为这些数据建立索引, 当用户检索时根据用户提交的检索条件从索引库中迅速查找到所需的信息。 W eb信息采集作为这些搜索引擎的基础和组成部分, 发挥着举足轻重的作用。
w eb信息采集是指通过W e b 页面之间的链接关系, 从W e b 上自动地获取页面信息,并且随着链接不断的向所需要的w eb 页面扩展的过程。 传统的W 曲信息采集的目标就是尽可能多地采集信息页面, 甚至是整个w eb 上的资源, 在这一过程中它并不太在意采集的顺序和被采集页面的相关主题。 这样做的一个极大好处是能够集中精力在采集的速度和数量上, 并且实现起来也相对简单。 但是, 这种传统的采集方法存在着很多缺陷。 因为基于整个W eb 的信息采集需要采集的页面数量十分浩大, 这需要消耗非常大的系统资源和网络资源, 但是它们中有相当大的一部分利用率很低。 用户往往只关心其中极少量的页面, 而采集器采集的大部分页面对于他们来说是没有用的。 这显然是对系统资源和网络资源的一个巨大浪费。 随着w eb 网页数量的迅猛增长, 即使是采用了定题采集技术来构建定题搜索引擎, 同一主题的网页数量仍然是海量的。 那么如何有效地对网页实现自动分类, 以创建更为有效、 快捷的搜索引擎是非常必要的。 传统的操作模式是对其人工分类后进行组织和管理。 这种分类方法分类比较准确, 分类质量也较高。 随着In tern et上各种信息的迅速增加, 仅靠人工的方式来处理是不切实际的。
对网页进行分类可以在很大程度上解决网页上信息杂乱的现象, 并方便用户准确地定位所需要的信息, 因此, 网页自动分类是一项具有较大实用价值的方法, 也是组织和管理数据的有效手段。 这也是本文研究的一个重要内容。北京邮电大学软件工程硕士论文1. 1. 2课题的*敏*感*词*研究现状●网页采集技术发展现状网络正在不断地改变着我们的生活, In tem et已经成为当今世晃上最大的信息资源库, 如何快速、 准确地从浩瀚的信息资源库中寻找到所需的信息已经成为网络用户的一大难题。 无论是一些通用搜索引擎( 如谷歌、 百度等), 或是一些特定主题的专用网页采集系统, 都离不开网页采集, 因而基于W eb 的网页信息采集和*敏*感*词*IG o o g le、 Y a h o o 等各种搜索引擎。 这些搜索引擎通常是通过一个或多个采集器从In tern et上采集各种数据, 然后在本地服务器上为这些数据建立索引, 当用户检索时根据用户提交的检索条件从建立的索引库中迅速查找到所需信息。 传统的采集方法存在着很多缺陷。首先, 随着网页信息的爆炸式增长, 信息采集的速度越来越不能满足实际应用的需要。 即使大型的信息...
0 个评论
官方客服QQ群
在
线
客
服