最新版:基于微博数据采集Web信息集成系统研究.doc 13页
优采云 发布时间: 2022-09-29 17:15最新版:基于微博数据采集Web信息集成系统研究.doc 13页
基于微博数据的Web信息集成系统摘要采集处理系统,通过用户提供的关键词,结合人工筛选关键词扩展,采集提取相关全网新闻和微博数据。设计并实现一种基于关键词和转发数的新闻排序方法,对特定字段采集的新闻数据进行处理和排序,选择重要信息进行定向推送。以气候变化领域为例,设计了一个Web信息集成系统。关键词:Web信息集成;微博数据采集; 气候变化;2016)11?0125?04 摘要:针对特定领域的Web信息集成系统采用模块化构建。
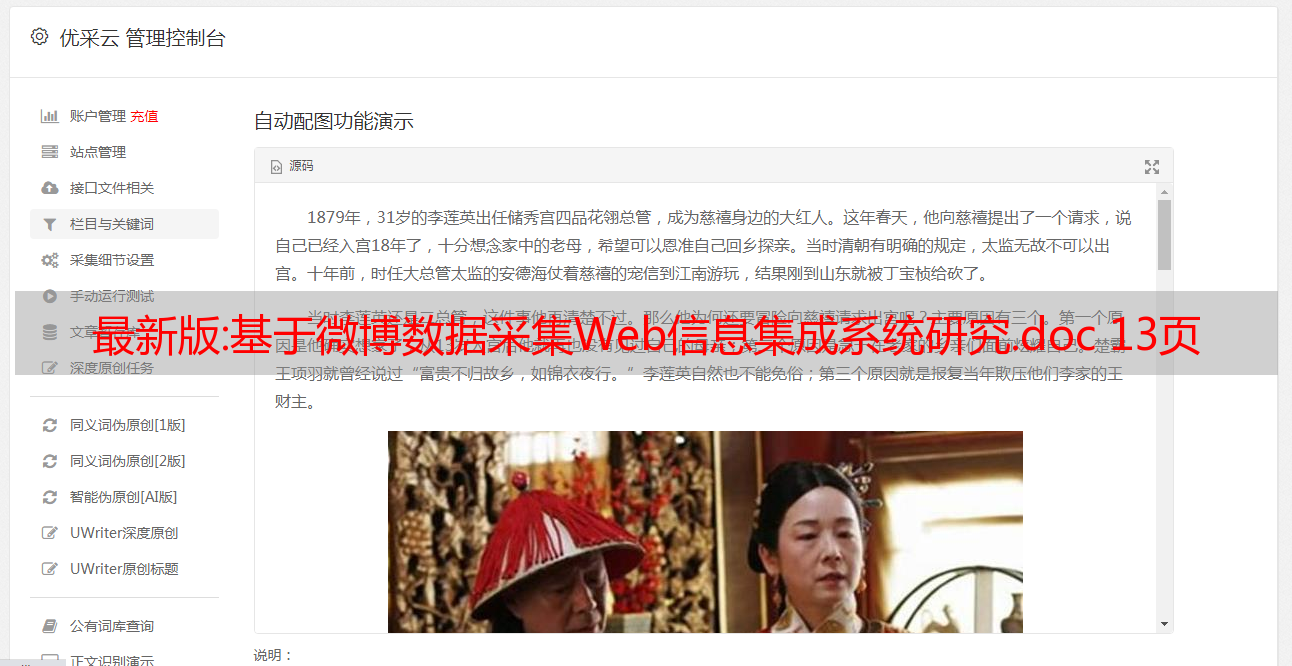
本文研究的特定领域Web信息集成系统,旨在对某一领域的Web信息进行深度挖掘,整合与Web领域相关的新闻和微博数据采集,为该领域的学者和用户提供信息支持。场地。1 特定领域Web信息集成系统设计1.1 特定领域Web信息集成系统Web信息集成系统整合Web上分散、异构、自治站点的数据信息,屏蔽所有数据源的细节. 只有用户查询的信息以统一的格式返回给用户。在设计特定领域的Web信息集成系统时,首先要做的就是分析用户对信息集成系统的需求。用户关注某个领域,掌握该领域比较重要的网站。同时,基于该领域的研究,用户可以使用一些领域本体关键词来描述该领域的研究热点、新闻热点、微博热点等。图1描述了用户之间的相互需求关系以及特定领域的Web信息集成系统。进一步细化了Web信息集成系统的内部方法流程,输入关键词和目标站点,输出三种方式的信息推送。具体方法流程如图2所示。 1.2 系统结构 为了降低系统设计的复杂度,本文在构建特定领域的Web信息集成系统时采用了模块化编程的思想。
根据每个模块的功能不同,每个模块收录一个或多个子流程。其详细的系统功能结构如图3所示。 2 关键技术2.1 新闻网络信息数据采集 与领域相关的新闻信息数据主要来自用户提供的目标网站,以及全网基于关键词采集System采集的消息是增量辅助数据。特定域的网络信息集成系统爬虫负责下载该域相关的新闻网页源代码。主要是从系统维护的URL序列中,有序提取URL,获取相应网页的HTML源代码,提取有用信息并存入数据库。2. 2 网络微博信息数据处理采集 通过对国内微博平台的调研,选择市场份额最大的新浪微博作为特定领域网络信息集成系统的微博中文数据源。国外微博舆论选择推特。图4以新浪微博为例说明了本文提出的信息数据采集提取方法。2.3 数据处理(1)数据去重处理面对的是全网信息采集,必然会遇到数据重复的问题。对重复信息的分析表明,重复的主要来源数据为:1、同一条新闻存在于同一站点的不同版块,采集系统下载两次以上;二、相同的新闻内容在不同的网站上发表或转载,新闻内容变化不大。系统有两个模块:采集期间去重和采集之后脱机去重。采集期间的去重模块主要针对同一个新闻同一个URL地址。
对于第二种情况,系统实现中使用了基于句子的Simhash去重算法。(2)数据过滤过程需要对数据库中已经存储的信息进行过滤,以去除数据处理过程中不相关的信息。如果微博内容中收录用户域关键词相关,则认为过滤方式为域微博,如果不收录,则删除微博信息。(3)数据排序和处理新闻网络信息数据排序原理是综合新闻内容字段的相关性、时效性和内容重要性排序。①计算领域相关性权重新闻内容,在数据处理前,给域关键词分配相应的权重,然后对新闻内容进行切分,与域关键词匹配,统计匹配字段关键词及其频率,计算内容相关性权重: ②根据新闻转发次数计算新闻重要性权重。③经过以上两步,得到每条新闻的相关性和重要性,结合新闻时效性,可以很好地对数据库中的新闻数据进行排序。针对微博信息热点推荐,设计并实现了一种改进的短文本话题发现方法。该方法满足大量微博数据。微博的处理和传播特性,首先基于马尔科夫模型(Hideen Markov Model)发现新词。然后利用新词发现结果构建LDA模型实现微博热点挖掘,最后结合微博发布时间和转发次数。,
2.4 特定领域信息的监测与自动更新模块 针对新闻网页动态性强、数据更新频率不固定的问题,设计了新闻网站监测与自动更新模块并实施。通过对目标网站的监控,建立网站信息的快照,并设置更新间隔、增益和下次更新时间。具体流程信息如下: Step1:针对目标新闻网站索引页,从数据库中读取其网页快照更新间隔Gain next update time Step2:通过比较当前系统时间判断是否更新索引页以及索引页的下一次更新时间。如果系统当前时间还没有到索引页的下一次更新时间,网站的更新检查将被忽略;如果当前时间已经过了下一次更新时间,则调用系统网络爬虫下载索引页的网页信息,获取当前网页的快照。第三步:将当前网页快照与数据库中的网页快照进行比较,判断网页是否更新。将步骤2中获取的索引页面的网页快照与从数据库中读取的最后一个网页快照进行比较。如果两个网页截图完全相同,则表示该网站的信息没有更新;如果它们不同,则表示该网站不一样。新闻信息已更新,系统自动调用网络爬虫将更新后的数据下载到数据库中。Step4:在第三步之后,可以判断网页索引页的信息是否更新,然后需要修正相应的更新时间间隔,计算下一次更新时间。对于没有任何更新的网站,需要动态增加更新间隔,下次更新时间采用如下表达式: 上述监控程序定期访问更新时间早于当前时间的网站,并与网页快照判断是否更新。
通过动态增加或减少更新间隔时间,可以保证数据库中的更新时间间隔动态逼近网站的真实更新间隔,计算出的下次更新时间上下波动。这样,网络信息集成系统就可以根据预期的网站更新时间更新数据采集,合理利用有限的资源,避免大量无关的检索操作,提高检索效率。 采集。2.5 特定字段的可视化和推送(1)动态网站展示和邮件推送。通过网站展示,用户可以直观的获取整合后或感兴趣的新闻内容在微博信息中,但有限制。一旦用户离开PC,很难获得有关系统集成的信息。(2)微信公众号信息推送。微信公众平台是公众号开发菜单的高级功能之一。为移动开发者提供了两种微信公众号模式:编辑模式和开发模式。启用微信公众号在编辑模式下,管理员可以整合用户的关注点和自己的服务内容,配置对应的公众号信息库。 开发模式是腾讯推出的使用第三方服务器响应的微信公众号开发方式3 Web信息集成系统的实现与分析3.
系统在预处理模块中将这些配置文件加载到系统中,同时初始化数据库、显示网站、通过邮件推送订阅用户列表等。在预处理阶段,根据关键词由用户和用户需要提供,字段关键词的词集可以有针对性的扩展,提供后续数据采集,处理提供支持。(3)数据采集及处理模块①Web数据采集模块气候变化领域Web信息集成系统数据源分为新闻数据源和微博数据源,其中新闻Web数据源主要使用用户自定义的方式来指定与领域相关的Web新闻站点,以保证新闻的准确性和相关性。微博数据的主要来源是新浪微博和推特,并将以新浪微博和推特为基础。微博搜索引擎获取的腾讯微博和搜狐微博作为微博数据的补充。系统数据信息采集模块包括领域新闻采集和微博舆情信息采集模块。领域新闻信息采集分为基于气候变化领域相关新闻网站索引页的新闻信息采集和基于气候变化领域的全网新闻信息采集气候变化领域关键词,通过索引页面识别和翻页模块,采集提取新闻网页链接的URL,然后采用文本提取方法提取文本信息采集@ >,
两者的主要区别在于网站的信息来源不同。前者有学者和专家指定气候变化领域的新闻网站,而后者则依靠搜索引擎在全网搜索气候变化领域的新闻信息。后者主要作为前者信息的补充,同时通过关键词进行扩展,对新闻事件检索有较好的效果。网络爬虫采集过程中对两个新闻URL去重,过滤重复新闻信息。②Web数据处理模块信息集成系统采集模块采集本地数据库存储大量气候变化相关新闻和微博数据。虽然在采集的过程中进行了URL去重和Simhash指纹算法去重,但是这些数据还需要进一步综合处理才能交给展示推送模块推送给用户。气候变化领域Web信息集成系统数据处理模块中收录的几个子模块如图5所示。 ③领域信息监测与自动更新模块网站信息更新时间是不同的。通过监控和自动更新模块,系统可以调用采集模块更新相应站点信息中的网站信息采集时间更新时间上下波动,避免过于频繁采集 @> 在目标站点的更新周期内进行操作,造成不必要的资源浪费。气候变化领域网络信息集成系统运行后,监测与自动更新模块会为某个网站的索引页面创建网页快照,并设置默认更新间隔T和增益K,并在同时根据当前时间和更新间隔计算下一个S,并将这些数据保存到库下载任务表中。
域关键词等信息,方便系统迁移到不同域,满足不同用户的需求。在采集用户设置目标站点的同时,系统可以采集处理全网相关新闻和微博数据,并将相关信息存入数据库进行展示。推送模块调用。在介绍系统设计的同时,阐述了各个模块的实现技术和功能,研究了关键技术,以及基于XPath的索引翻页方法、通用新闻网页文本方法和采集系统基于关键词现场新闻数据和微博舆情信息等。参考文献[1]吴斌杰,徐子伟,于飞华。基于API的微博信息采集系统设计与实现[J]. RIBEIRO?NETO BA、DA SILVA AS 等人。Web数据抽取工具概述[J]. ACM SIGMOD record, 2002, 31 (2): 84?93. [7] FLESCA S, MANCO G, MASCIARI E, et al. Web Wrapper Induction: a Brief Survey [J]. AI Communications , 2004, 17 (2): 57?61.
最新发布:PbootCMS采集插件提升网站收录排名
在我们选择了Pbootcms之后,网站内容构建和网站收录排名是大家比较关心的问题,很多网站在页面的过程中布局,往往更注重布局新颖、气派,但能否满足用户的实际需求?搜索引擎可以识别 网站关键词 主题吗?这些根本不考虑,如果不能,就堆积关键词。结果往往是页面布局完成后,页面上只能找到一些关键词,既没有解决用户的相应需求,也没有从搜索引擎规则上调整内容,导致没有排名,没有网站 的转换。
在我们实际操作中,要注意关键词的布局和选择,可以通过以下方法进行优化。
一、明确你想吸引和可以吸引的用户群
1、根据用户组的特点确定关键词。
2、网站越小,需要对核心用户群进行细分越精准,使用的长尾关键词越多。
3、网站 越大,核心用户组的范围越大。您可以更多地使用核心 关键词。
二、选择合适的关键词
1、关键词选品原则:高人气、低竞争、高商业价值
2、竞争分析
(1)搜索结果首页的内容是反映关键词竞争的重要元素之一。
(2)进行竞争对手分析,估计关键词优化难度,分析首页10个结果和20个可能与你有竞争关系的结果。
(3)收录在一定程度上反映了竞争的程度。
三、关键词密度(2%-4%更好)
(1)关键词一般建议密度为2%-8%。
(2)关键词密度太低,会影响关键词的排名。
(3)任何页面都应该尽量保持一个合理的关键词密度。
四、长尾关键词布局内页
长尾 关键词 理论并不陌生。对于做SEO的人来说,重要的是要有长尾关键词意识,在网站结构排列、内部链接、文章页面原创方面,要考虑长尾尾巴的概念就足够了。真正能充分发挥长尾关键词优势的网站都需要海量优质文章的支持。这样的网站long-tail关键词效果自然得到,全面的长尾关键词研究是不可能的。所以在小网站的构建过程中,长尾的重点布局不需要太刻意的布置。
五、避免使用相同布局的多个页面关键词
很多网站SEOER 犯了一个错误,网站具有相同的多个页面目标关键词。可能这些人认为同一组关键词针对首页和几个栏目页面进行了优化,这样排名的机会就更高了。其实根本不是这样的,应该尽量避免。在同一个网站中竞争一个关键词应该只有一页,目标明确,精力集中。这样重量就不会散开。
如果觉得上面的方法太繁琐,我们也可以通过Pbootcms采集插件完成上面的关键词布局。
一、 利用免费的 Pbootcms采集插件采集Industry关键词
关键词主要来自用户输入的行业关键词和自动生成的下拉词、相关搜索词、长尾词。一次可以创建几十上百个采集任务,可以同时执行多个域名任务。可以在插件中进行以下设置:
1、设置屏蔽不相关的词,
2、自动过滤其他网站促销信息
3、多平台采集(覆盖全网头部平台,不断更新覆盖新平台)
4、支持图片本地化或存储到其他云平台
5、支持各大cms发布者,采集自动发布推送到搜索引擎
二、Pbootcms采集内容SEO优化功能
1、标题前缀和后缀设置(区分标题会有更好的收录)
2、在内容中插入关键词(合理增加关键词密度)
3、产品图片随机自动插入(插入自己的产品图片可以让内容展示更清晰)
4、搜索引擎主动推送(主动向搜索引擎推送已发布的文章,以缩短新链接被搜索引擎收录的时间)
5、设置随机点赞-随机阅读-随机作者(增加页面度数原创)
6、设置内容匹配标题(让内容完全匹配标题)
7、设置自动内链(在执行发布任务时自动在文章的内容中生成内链,有助于引导页面蜘蛛抓取,提高页面权限)
8、设置定时发布(网站内容的定时发布可以让搜索引擎养成定时爬取网页的习惯,从而提高网站的收录)
三、免费Pbootcms采集-Visual Batch网站管理
1、批量监控不同的cms网站数据(你的网站是Empire, Yiyou, ZBLOG, 织梦, WP, Xiaocyclone, 站群 、PB、Apple、搜外等主要cms工具,可同时管理和批量发布)
2、设置批量发布次数(可以设置发布间隔/单日总发布次数)
3、不同关键词文章可设置发布不同栏目
4、伪原创保留字(当文章原创未被伪原创使用时设置核心字)
5、软件直接监控是否已发布、即将发布、是否为伪原创、发布状态、URL、节目、发布时间等。
6、每日蜘蛛、收录、网站权重可以通过软件直接查看!
Pbootcms采集插件虽然操作简单,但功能强大,功能全面。可以实现各种复杂的采集需求。*敏*感*词*采集软件,可应用于各种场合。复杂采集 需求的首选。

