完美:自动采集器怎么用("二次编辑器)
优采云 发布时间: 2022-09-29 10:48完美:自动采集器怎么用("二次编辑器)
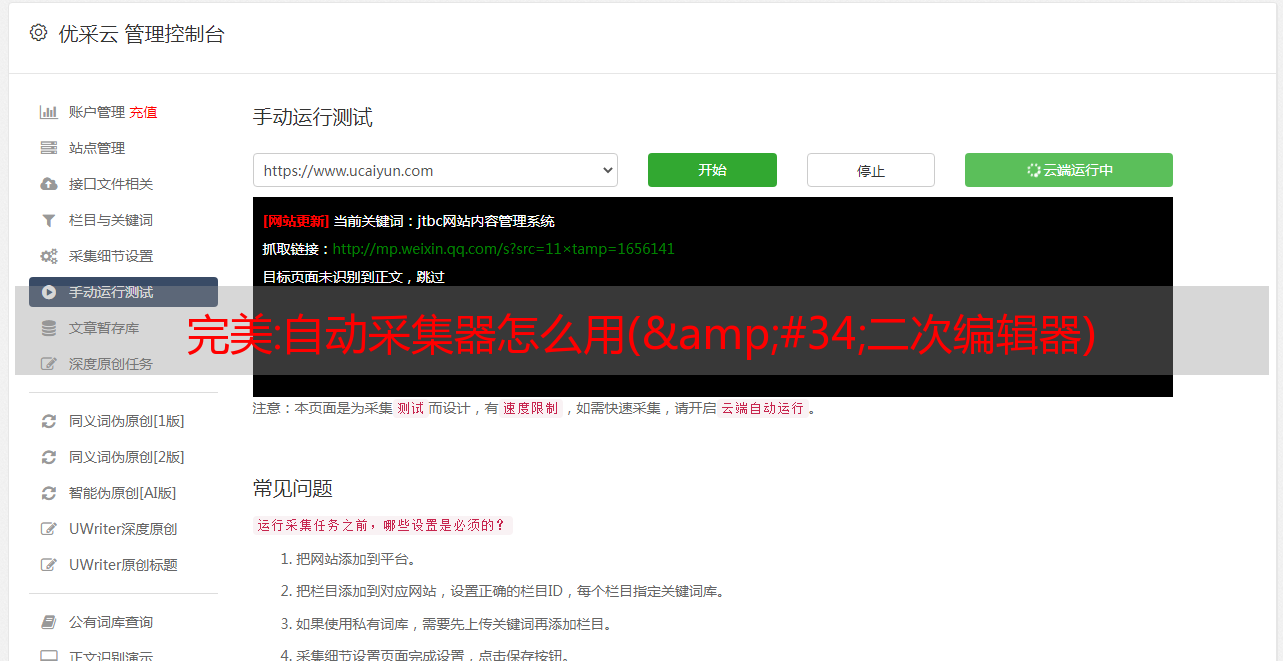
自动采集器怎么用?我平时经常会遇到需要采集一些网站的页面内容或者是需要采集一些教程。首先做的是把需要采集的网站爬虫抓取下来,然后再把抓取下来的网站地址在浏览器上进行搜索,进行页面的内容抓取,这样就会把抓取下来的网站地址自动转化为标题或者是代码的形式。然后把采集来的内容在自动采集器中进行修改,也可以按照自己想要的格式修改。
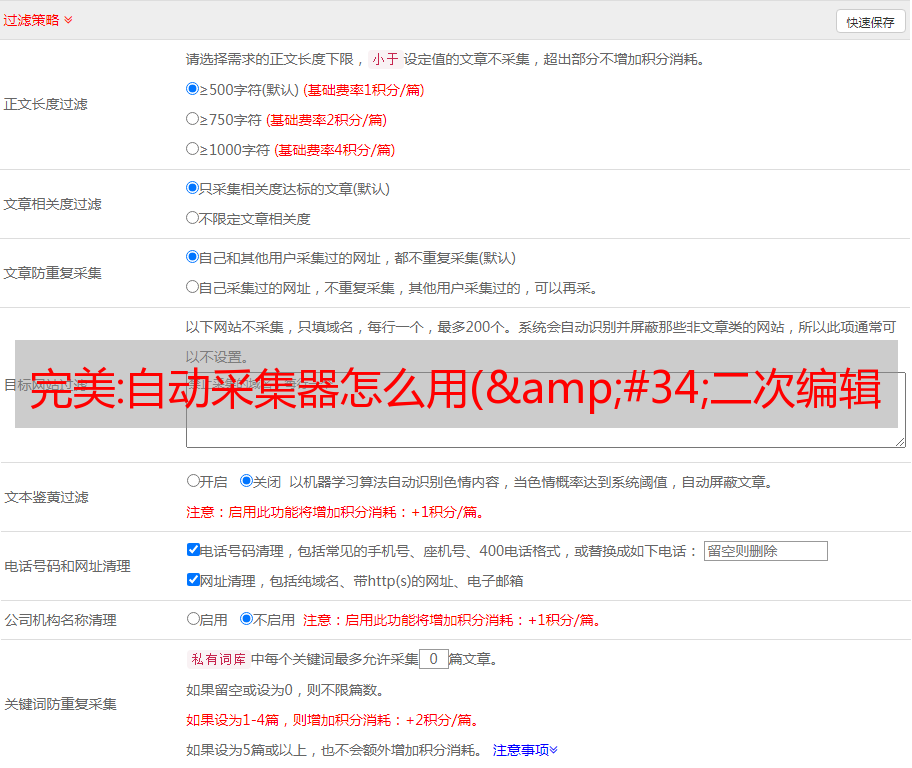
这样就完成了一个自动采集器的使用。有些个人站长可能会不喜欢用自动采集器,可能采集网站会显得比较麻烦,那么可以使用原始的html文件采集器进行采集,这样就不需要对html文件进行修改,节省了我们对html文件进行修改的时间。具体实现方法是:打开一个文本编辑器,在其中输入你要采集的网址,然后将网址中的,空格替换成你要采集的内容。
例如“rss”代码,搜索引擎就会自动抓取并转化为txt形式。这样我们就用一个格式固定的html文件来采集网站。接下来我们来写一个自动采集器的采集文件代码,你可以将下面的代码进行二次编辑,成为自己需要的样子。#!/usr/bin/envpython#-*-coding:utf-8-*-importrequestsfrombs4importbeautifulsoupimportsyssys.setdefaultencoding('utf-8')#url=';_1=&_2=&_3=&_4=&_5=&_6=&_7=&_8=&_9=&_10=&_11=&_12=&_13=&_14=&_15=&_16=&_17=&_18=&_19=&_20=&_21=&_22=&_23=&_24=&_25=&_26=&_27=&_28=&_29=&_30=&_31=&_32=&_33=&_34=&_35=&_36=&_37=&_38=&_39=&_40=&_41=&_42=&_43=&_44=&_45=&_46=&_47=&_48=&_49=&_50=&_51=&_52=&_53=&_54=&_55=&_56=&_57=&_58=&_59=&_60=&_61=&_62=&_63=&_64=&_65=&_66=&_67=&_68=&_69=&_70=&_71=&_72=&_73=&_74=&_75=&_76=&_77=&_78=&_79=&_80=&_81=&_82=&_83=&_84=&_85=&_86=&_88=&_89=&_90=&_91=&_92=&_93=&_94=&_95=&_96=&_96=&_97=&_98=&_98=&_98=&_98=&_98=&_98=&_98=&_98=&_98=&_98=&_98=&_98=&_98=&_98=&_98=&_98=&_98=&_98=&_98=&_98=&_98=&_98=&_98=&_98=&_98=&_98=&_98=&_98=&_98=&_98=&_98=&_98=&_98=。

