分享文章:微信公众号文章采集,公众号文章批量采集
优采云 发布时间: 2022-09-29 05:13分享文章:微信公众号文章采集,公众号文章批量采集
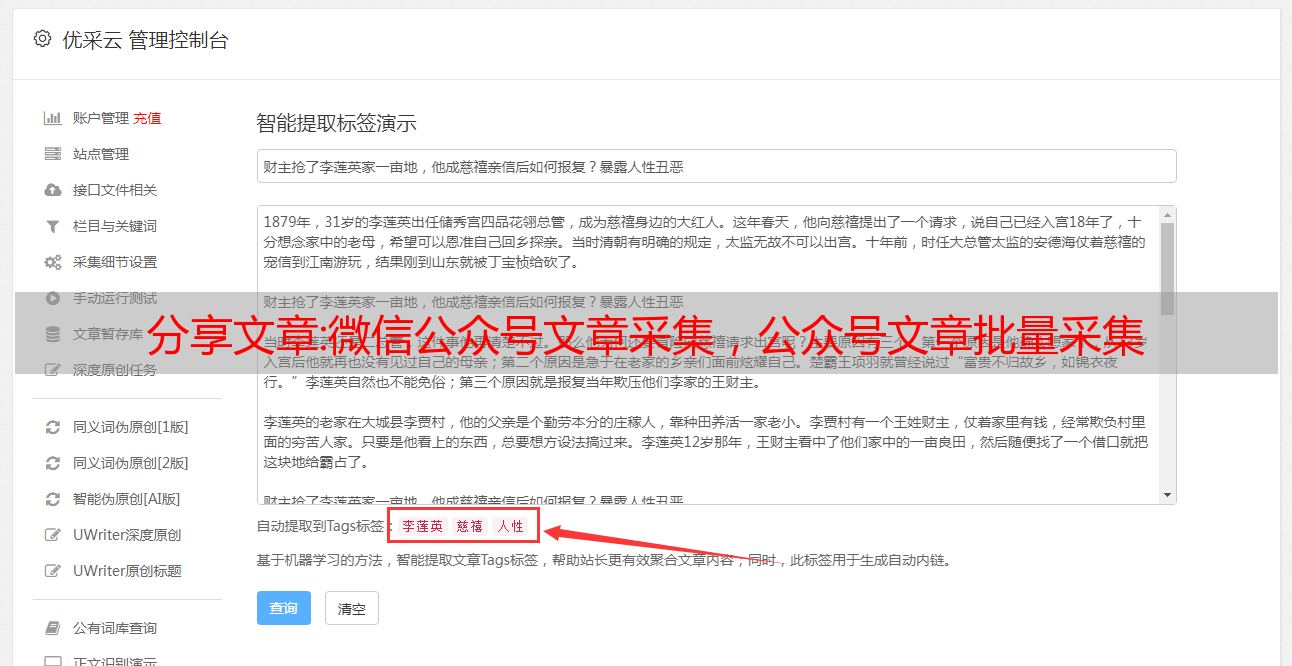
微信公众号文章采集工具可以让我们获取海量的优质素材,微信公众号每天都会产生大量的文章、图片内容等素材,通过数据采集与处理工具,我们可以对我们需要采集的公众号文章数据进行批量采集。本地保存,进行数据分析或进行二次创作等操作。
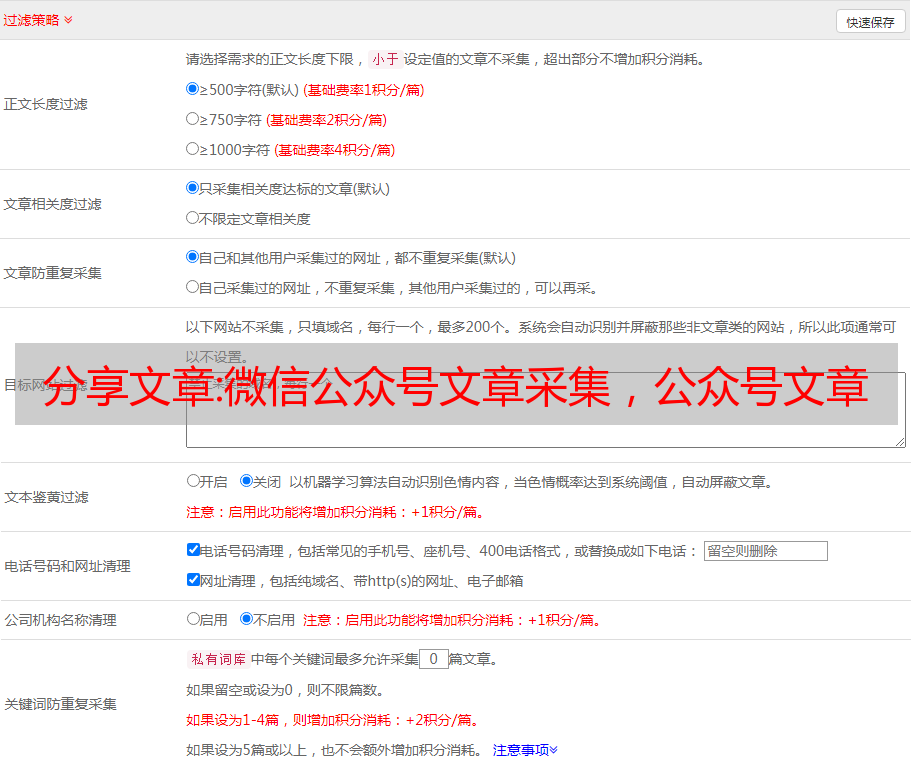
微信公众号文章采集工具操作简单,页面简洁方便,只需要我们鼠标进行点选就可以完成采集配置,即可开始目标网址采集。支持采集资源标签保留(更好的保存格式)、原文敏感词过滤(电话号码地址等去除)、原文图片水印祛除等。
有时网页抓取是不够的;通常需要更深入地挖掘和分析数据来解开数据背后的真正含义并发现有价值的见解。数据和内容的分析利用可以说与我们的工作生活息息相关。
以网站SEO为例,通过数据分析,我们可以统计出网站每天的流量变化以及页面的跳出率,得出我们网站某些环节的不足。也可以通过数据采集分析我们竞争对手的关键词排名与我们的差距,让我们能及时调整做出更好的优化应对。
当然,如果不喜欢用工具,我们也可以通过自行敲代码完成这部分工作:
第一步是通过创建蜘蛛从目标抓取内容:
为了保存数据,以脸书为例,我们将定义一个收录三个字段的项目:“title”、“content”和“stars”:
importscrapy
classFacebookSentimentItem(scrapy.Item):
title=scrapy.Field()
content=scrapy.Field()
stars=scrapy.Field()
我们还创建了一个蜘蛛来填充这些项目。我们给页面的起始URL。
importscrapy
fromFacebook_sentiment.itemsimportFacebookSentimentItem
class目标Spider(scrapy.Spider):
name="目标"
start_urls=[域名]
然后,我们定义一个函数来解析单个内容并保存其数据:
defparse_review(self,response):
item=FacebookSentimentItem()
item['title']=response.xpath('//div[@class="quote"]/text()').extract()[0][1:-1]#stripthequotes(firstandlastchar)
item['content']=response.xpath('//div[@class="entry"]/p/text()').extract()[0]
item['stars']=response.xpath('//span[@class="ratesprite-rating_srating_s"]/img/@alt').extract()[0]
returnitem
之后,我们定义一个函数来解析内容页面,然后传递页面。我们会注意到,在内容页面上,我们看不到整个内容,只是开始。我们将通过点击完整内容的链接并使用parse_review从该页面抓取数据来解决此问题:
defparse_Facebook(self,response):
forhrefinresponse.xpath('//div[@class="quote"]/a/@href'):
url=response.urljoin(href.extract())
yieldscrapy.Request(url,callback=self.parse_review)
next_page=response.xpath('//div[@class="unifiedpagination"]/child::*[2][self::a]/@href')
ifnext_page:
url=response.urljoin(next_page[0].extract())
yieldscrapy.Request(url,self.parse_Facebook)
最后,我们定义了主要的解析函数,它将从主页开始,并且将解析其所有内容:
defparse(self,response):
forhrefinresponse.xpath('//div[@class="listing_title"]/a/@href'):
url=response.urljoin(href.extract())
yieldscrapy.Request(url,callback=self.parse_Facebook)
next_page=response.xpath('//div[@class="unifiedpaginationstandard_pagination"]/child::*[2][self::a]/@href')
ifnext_page:
url=response.urljoin(next_page[0].extract())
yieldscrapy.Request(url,self.parse)
所以,要内容:我们告诉蜘蛛从主页开始,点击每条内容的链接,然后抓取数据。完成每一页后,它将获得下一个页面,因此它将能够抓取我们需要的尽可能多的内容。
可以看出,通过代码进行我们的微信公众号文章采集,不仅复杂,而且需要比较专业的知识。在网站优化方面我们还是应该秉承最优解,对于微信公众号文章采集与处理的分享就到这里结束了,如果有不同意见,不妨留言讨论。
推荐文章:自媒体文章图片批量采集编辑发布
如何将自媒体文章批量同步到全网CMS,通过147SEO工具,我可以将每天在今日头条、公众号和小红书上的精选文章发布到我们WordPress、织梦、帝国等各类CMS上,通过可视化操作批量管理我们的文章和图片。
了解我们的受众在寻找什么对于吸引大量读者至关重要。通过我们的精选文章素材进行二次创作以专门满足用户的需求,从而增加我们的流量转换。同步之后怎么批量格式化和优化让我们的网站SEO更出色是我们下一步需要考虑的。
一、同步的自媒体文章是有价值的
有价值的文章体现在受用户和搜索引擎喜欢这两个方面。过于老旧的自媒体文章即使经典,但可能随着时间迁移,已经不再受到用户喜欢。一旦观众进入并被我们的精彩标题所吸引,就该开始通过故事或鼓舞人心的内容来强化我们的信息,与他们交谈并解决他们的问题。
原创性的文章是受搜索引擎欢迎的。我们原创有趣的内容对吸引读者继续阅读是至关重要的,如果不这样做可能会让我们的访问者进入网站的下一个操作就是退出页面,跳出率太高是我们不愿意看到的。怎么通过自媒体文章二次创作批量同步到我们网站,并留住用户呢?
二、同步后的页面提高用户体验
太过紧凑的网站页面不利于用户体验。在我们的文章之间留出空白会让读者按照自己的节奏阅读信息。让读者有呼吸的空间,同时让我们的网站更美观。我们不能输!
使用较小的段落来分解我们的内容不仅可以使其看起来更吸引人,还可以让读者更有效地使用信息。它们更容易阅读,因此,我们的读者在得出结论时会记住更多我们说的话。
尝试将副标题分段到我们的内容中。就内容的外观和感觉而言,没有其他东西会产生更大的影响。副标题有助于组织访问者正在查看的内容,并允许他们在单独的信息片段之间移动,而无需逐段重读。在副标题中收录好处和问题有助于提高内容的感知价值,因此请记住这一点。
三、同步后的文章图片和可读性
自媒体文章素材如何打造,不能仅仅是简单的伪原创,图片对于我们网站SEO也是不可缺少的,很多搬运工就经常出现连图一起搬运的情况,这个情况就跟抄作业把名字都一起抄了一样滑稽。同步工具具有批量图片水印去除和自有图片替换原文图片,这样就解决了图片水印和原创度的问题。
虽然简短的内容可能对读者有所帮助,但我们不必使每个段落都尽可能短。有些内容需要更多的单词才能一口气表达出来,所以也不要回避更长的段落。但是,如果我们是我们所在行业的权威,或者如果我们想被视为权威,那么长篇内容将有助于传递这种印象一本好书,一本坏书。
自媒体文章批量编辑管理并同步到全网CMS该怎么是现实的分享就到这里,通过简单的操作,运用工具,我们可以方便的完成机械重复的工作,对我们的自媒体文章精修发布。并推送给我们的搜索引擎平台,加速蜘蛛抓取的速度。如果觉得不错,大家记得采集点赞哦。

