最新版:微信公众号文章下载器,用于下载微信公众号的所有文章
优采云 发布时间: 2022-09-29 00:29最新版:微信公众号文章下载器,用于下载微信公众号的所有文章
————————————————————————————————————————————————————— ——
我以前用论坛里一个大佬的软件(WeChatDownload)下载文章。后来微信版本更新了,需要用老版本的微信才能用,就搞定了。设计比较简单,就是按部就班,没有使用多线程之类的,功能也没有之前的boss那么多。
软件环境:VS2015+C#+.NET4.0+Fiddler+SQLITE
SQLITE用于存储文章列表信息:标题、链接、状态、文章类型等信息
本软件提供源代码,有基本注释,需要的可以下载修改。
附加说明:
1、文章下载后放在软件根目录,公众号命名的文件夹
2、显示ok 2022/6/20 16:37:57的消息表示文章列表获取成功,文章列表存储在SQLITE数据库中,即: Database.db 该文件可以使用 SQLite Expert Personal 软件打开,该软件有免费版本。当公众号有很多文章时,需要一定的时间才能完成下载。
3、出现:成功:文章Title(),得到文章成功。2022/6/20 16:38:41 表示开始下载文章,出现这个时,只有公众号命名的文件夹,文章的发布时间和文章@的标题> 将在根目录下命名为 html 文件。
补充2:
Q:下载过程中,中途停止(意外/主动)怎么办?
答:中途停车有两种情况
一是停止文章 列表的下载。下次重新获取后,需要从头重新获取文章列表,但是重复的文章不会保存,只会保存最后一次。未保存 文章。
(想了想,不知道暂停是一天,一个月,还是一年,所以没有设计保存上次得到的offset,自己做的话可以加个将offset保存到数据表中,下次从这个offset开始。不过有一种情况需要考虑,就是挂了很久,挂的时候更新了很多文章 )
一种是下载文章时停止,这个没有效果。下次重启后,会从下一个未保存的文章开始保存(数据库记录了哪一个被下载了)。
文章列表获取原理:当一个文章列表获取完成后,最后一次完整获取的时间会记录在数据表中。下次获取同一个公众号时,将从最新的获取。,然后一直到最后一次完整提取时间的前 3 天。例如,最后一次完整的收购是在 2022 年 6 月 3 日。这一次,将从最晚开始,一直持续到2022-6-1。多余的日子是为了防止丢失文章。
所以如果 文章 的列表一次没有被完全抓取,那么每次都会从头到尾抓取。
文章存储形式
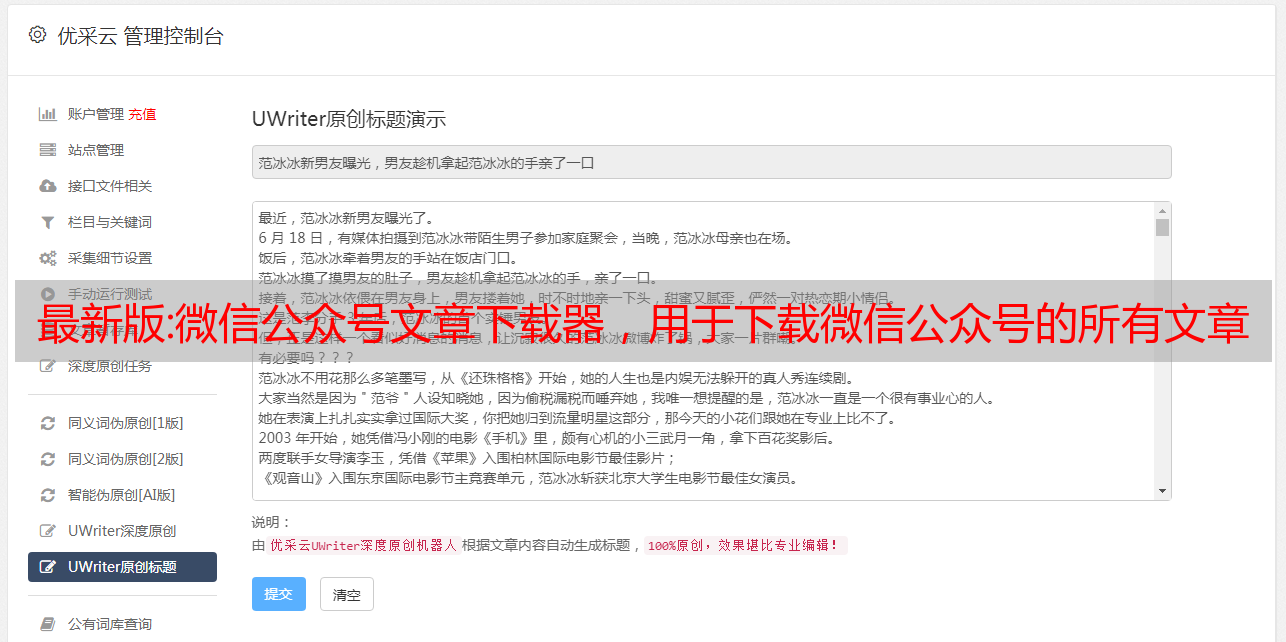
软件功能:获取公众号中的所有文章,然后保存为HTML文件。一个 文章一个 HTML 文档。
未实现的功能:付费文章隐藏的不能下载,视频不能下载,音频不能下载。图片没下载,直接用图片链接地址。
下载时间:假设1000篇文章文章,如果没有错误等,下载完成所需时间:1000/10*20+1000*20=6.2小时。
获取文章列表的参数每30分钟过期一次,1000篇文章中间需要再次获取参数。
如果觉得时间太长,可以自行修改采集时间间隔。不建议太快。太频繁可能会触发微信的反采集机制,限制某个公众号的访问。
因为采集太快了,公众号的访问受限一段时间,一般第二天就会恢复。(我测试了采集几个公众号,间隔20秒,总数有几千个文章没有限制访问)
注:虽然采集已测试多个公众号,但由于微信文章形式多样,可能存在采集错误或采集后的内容与原文。
测试平台(VB虚拟机):WIN7_X86+.NET4.0,WIN7_X64+.NET4.0,WIN10_X86,WIN10_X64,微信版:3.7.0
*敏*感*词*演示:
界面
会话参数的有效时间为 30 分钟。如果超过30分钟就会超时,需要重新获取。
重新获取会话参数
指示:
1、先关闭所有开放的公众号文章。
2、点击【①获取参数】,然后打开公众号下载文章,在公众号中选择打开任意一个文章。
3、文章加载完成后,获取的参数会显示在【运行日志】中。参数获取完成后,会自动开始获取文章。
4、请不要打开多个软件。
公众号获取文章的流程:
先获取必要的参数->获取公众号的所有文章并合并到SQLITE数据库中->然后从数据库中取出文章,下载并一一标记。
获取内容:
直接保存文章的内容,不做任何处理。图片使用网络地址,没有留言保存,可以自行修改添加。
问题及解决方案:
1、在获取参数时,浏览器可能会出现:【未连接:存在潜在的安全问题】,无法浏览网页。
解决方法:原因可能是Fiddler的证书问题。您只需等待参数采集完成或手动停止参数采集即可恢复。
2、现有公众号文章未关闭时,点击【获取参数】即可获取当前浏览文章的参数。当你想获取另一个公众号的数据时,可能会出现参数错误。
解决方法:先关闭所有正在浏览的公众号文章,然后点击【①获取参数】,再打开需要下载的公众号文章中的任意一个。
3、有信息问题提示错误类。
解决方法:一般可以根据方法重试一次/多次。如果没有,您可以关闭该软件并重新打开它。
4、获取参数后,软件意外关闭或自动关闭,再次访问网页时提示:【代理服务器拒绝连接】。
解决方法:这是因为在获取参数时,软件会修改系统的分代{pass}{filtering}管理。如果不停止,这种世代相传的{passing}{filtering}管理将永远存在。重启软件,点击【①获取参数】,然后点击【①停止获取】。
5、获取文章时,软件意外或主动关闭后,重新打开后,会重复获取或下载之前的文章。
A:不会重复。获取到 文章 的列表时将关闭。下次重新打开后,依然会开始获取第一篇文章,发现重复自动跳过。
下载文章时关闭,下次重新打开时,会从下一个未下载的文章开始下载。
6、由于Fiddler证书安装问题,可能会出现其他未知错误。请使用搜索引擎查找相关解决方案,或提供可重现的解决方案进行回复。
7、有时候,打开文章后,参数并没有完全获取到,采集也没有执行。
解决方法:关闭文章再打开一篇文章文章,尽量不要使用刷新,有些参数只有第一次才有。
8、软件被WIN10的安全中心删除了怎么办?
解决方法:通过安全中心添加到排除列表。
最新信息:python自动获取微信公众号最新文章的实现代码
目录
微信公众号获取思路
获取微信公众号文章常用的方法有搜狐、微信公众号首页和api接口。
听说最近搜狐不太好用,而且之前使用的API接口也经常维护,所以使用微信公众平台进行数据爬取。
首先,登录你的微信公众平台。如果您没有帐户,您可以注册一个。进来后找“图文资料”,就是写公众号的地方
点击后会出现写公众号的界面文章。在界面中,您会找到“超链接”字段,您可以在其中搜索其他公众号。
以“python”为例,输入要检索的公众号名称,从显示的公众号中选择公众号为采集
点击浏览器查看,在网络中找到链接,下图中的链接,右边的Request URL是存储公众号数据的真实链接。表示这是一个 json 网页。
采集实例
以公众号“python”的链接为例,分析URL。
https://mp.weixin.qq.com/cgi-bin/appmsg:微信公众平台的链接
"token": "163455614", #需要定期修改的token
"lang": "zh_CN", #语言
"f": "json",
"ajax": "1", #显示几天的文章
"action": "list_ex"
"begin": "0", #起始页面
"count": "1", #计数
"query": "",
"fakeid": "MzIwNDA1OTM4NQ==", #公众号唯一编码
"type": "9",
由于我发现fakeid是唯一代表公众号的代码,那么我只需要找到所需公众号的fakeid即可。我随机找了三个公众号进行测试。
fakeid=[ "MzIwNDA1OTM4NQ==","MzkxNzAwMDkwNQ==","MjM5NzI0NTY3Mg=="]
<p>
#若增加公众号需要增加fakeid</p>
然后下一步就是请求URL
首先导入需要的库
import time
import requests
from lxml import etree
import pandas as pd
import json
import numpy as np
import datetime
import urllib3
from urllib3.exceptions import InsecureRequestWarning
urllib3.disable_warnings(InsecureRequestWarning)
由于不想重复登录公众号平台,可以使用cookies来避免登录。在请求文章之前,需要先找到网页的cookie和User-Agent。由于微信公众号是定期刷新的,所以这个cookie和上面的token都要定期刷新。代替。
为了避免反扒,最好找个代理ip
headers = {
"Cookie": "appmsglist_action_3567997841=card;wxuin=49763073568536;pgv_pvid=6311844914;ua_id=x6Ri8bc9LeaWnjNNAAAAADI-VXURALRxlSurJyxNNvg=;mm_lang=zh_CN;pac_uid=0_3cf43daf28071;eas_sid=11Q6v5b0x484W9i7W0Z7l7m3I8;rewardsn=;wxtokenkey=777;wwapp.vid=;wwapp.cst=;wwapp.deviceid=;uuid=fd43d0b369e634ab667a99eade075932;rand_info=CAESIHgWwDfp3W4M9F3/TGnzHp4kKkrkMiCEvN/tSNhHtNBm;slave_bizuin=3567997841;data_bizuin=3567997841;bizuin=3567997841;data_ticket=IfMEEajZ8UvywUZ1NiIv9eKZkq0cgeS0oP6tTzEwNSjwK6q+u5vLw0XYeFvLL/JA;slave_sid=aVBzSlpYOGt4eTdmbzFRWDc1OUhzR1A1UkwzdUdBaklDaGh2dWY2MUZKTEw1Um1aalZRUXg5aVBMeEJVNklCcGlVN0s5Z3VEMmRtVENHS1ZxNTBDOWRCR0p2V2FyY2daU0hxT09Remd5YmlhRWExZkMwblpweVc3SndUbnJIQk55MGhUeExJa1NJcWZ0QmJS;slave_user=gh_e0f449d4f2b6;xid=7d5dc56bb7bb526c70cfef3f6bdfa18a",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.75 Safari/537.36",
}
proxies = {"http": "112.80.248.73"}
接下来可以爬取页面,获取页面中的文章标题和文章链接,以及文章的时间,分析网页的信息,发现所有的信息网页保存在“app_msg_list”字段中,因此提取该字段中的数据。
代码显示如下:
得到的数据包存放在df中。这里的数据不是微信公众号最新的文章数据,而是微信公众号最近一天发送的文章数据。因此,还需要过滤发布时间。注意这里的时间格式是时间戳,所以需要转换时间数据
转换代码如下:
def time_s(df):
def transfer_time(s): #时间处理
aa = time.ctime(s)
<p>
bb = aa.split(" ")
cc = (bb[-1]+"-"+bb[1]+"-"+bb[-3]).replace("Jan","1").replace("Feb","2").replace("Mar","3").
replace("Apr","4").replace("May","5").replace("Jun","6").replace("Jul","7").replace("Aug","8")
.replace("Sep","9").replace("Oct","10").replace("Nov","11").replace("Dec","12")
dd = datetime.datetime.strptime(cc,"%Y-%m-%d").date()
return dd
ti=[]
hd=[]
for i in range(0,len(df["time"])):
timestap= transfer_time(df["time"][i])
ti.append(timestap)
#print(ti)
d= ti[i] + datetime.timedelta(weeks=0, days=0, hours=0, minutes=0, seconds=0, milliseconds=0, microseconds=0, )
#dc = d.strftime("%Y-%m-%d")
hd.append(d)
df["time"]=hd</p>
这样就可以将微信公众号的时间戳数据转换为时间数据,然后根据当天的日期提取数据集中的内容并存储。
dat=df[df["time"] == datetime.date.today() + datetime.timedelta(days= -1)] #自动获取昨天日期,将-1改为-2,则为前天的日期,以此类推
##改自动化
path = "C:/Users/gpower/Desktop/work/行业信息/" #根据自己电脑位置更改
import re
filename=path+"微信公众号采集" + re.sub(r"[^0-9]","",datetime.datetime.now().strftime("%Y-%m-%d")) + ".csv"
# 对文件进行命名,以“微信公众号采集+当前日期”命名
dat.to_csv(filename,encoding="utf_8_sig")
print("保存成功")
这样就可以下载最新的微信公众号文章采集。如果需要多个微信公众号,可以在fakeid中添加公众号的识别码。
这是文章关于python自动获取微信公众号最新文章的介绍。更多关于python自动获取微信公众号文章的信息,请在文章前搜索云海天教程或继续浏览下方相关文章,希望大家以后多多支持云海天教程!

