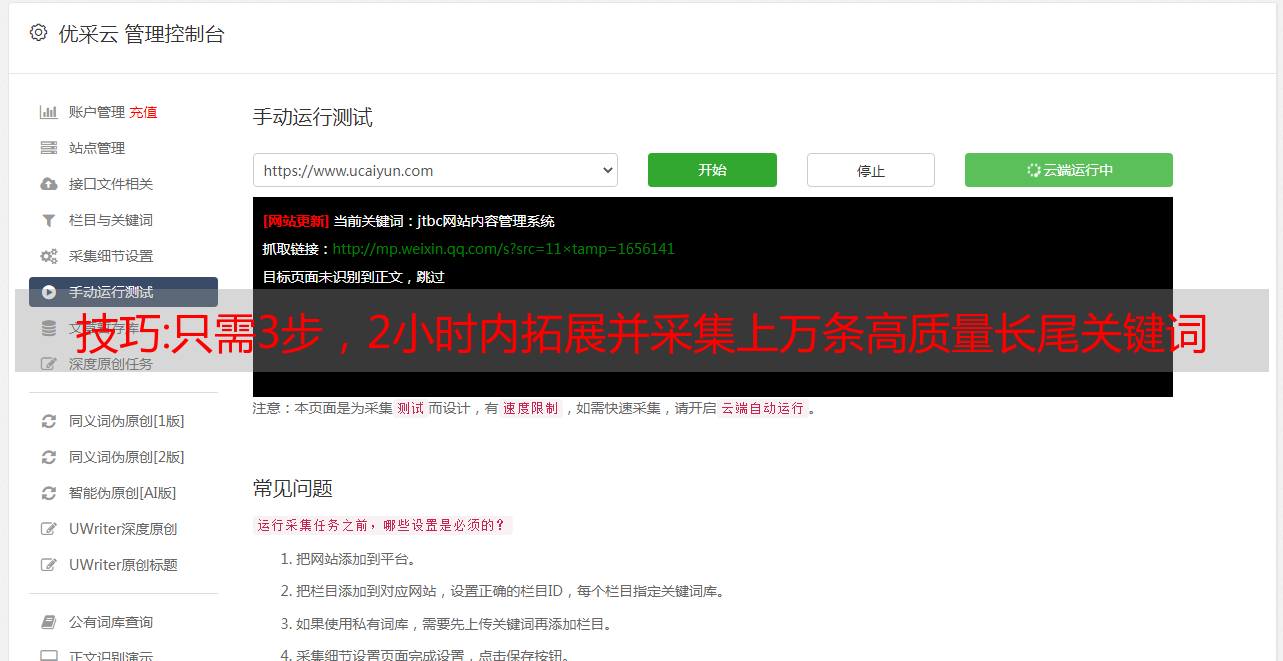
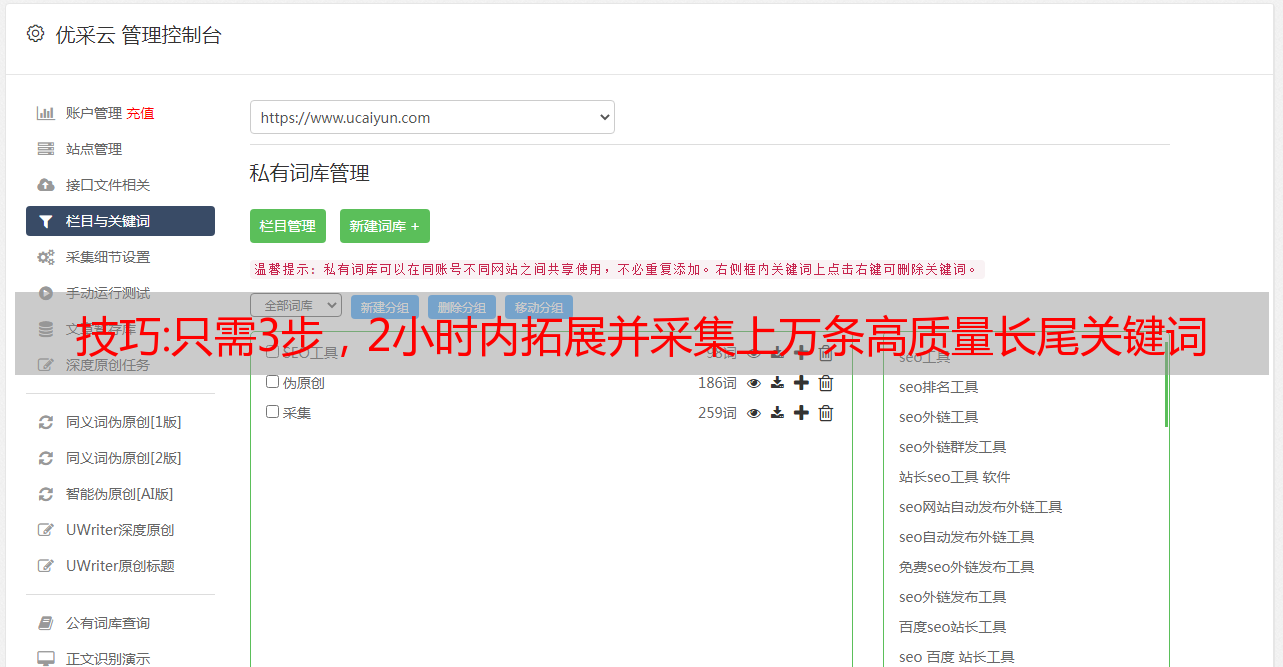
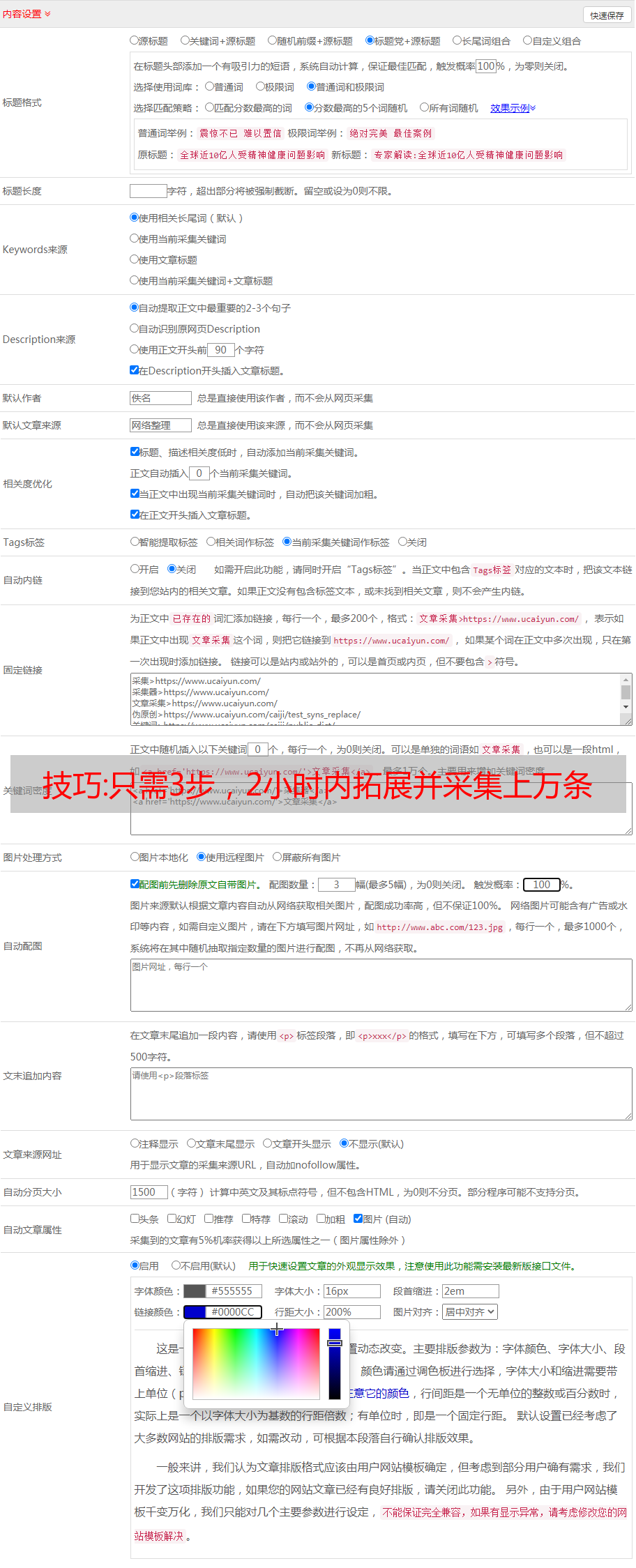
技巧:只需3步,2小时内拓展并采集上万条高质量长尾关键词
优采云 发布时间: 2022-09-28 10:27大家好,我是老金摸鱼的老金,一个不但会摸鱼还要强调摸鱼质量的打工人。
今天想和大家分享一下关于长尾词拓展和挖掘的术和器。
为啥说术和器呢,任何一个工作必然是有它自己的道道的,12345步骤列出来你照着执行,这叫术;但是像老金这么懒的人,给步骤了执行起来都嫌麻烦,怎么办?用工具呗,人和动物最大的区别嘛,知道用工具来提高效率。
本文共6670字,请耐心阅读,对于非小白读者可以直接跳过第一章进行阅读,如果感觉读不完就放到采集夹里吃灰吧。
1. 为啥要做长尾词挖掘
(本章主要针对小白,老江湖们可以跳过了)
为啥要做长尾词挖掘?
在回答这个问题之前,咱们得先知道什么是长尾词,引用某度百科的解释如下:
“长尾关键词”(Long Tail Keyword)是指网站上的非目标关键词但与目标关键词相关的也可以带来搜索流量的组合型关键词。往往是2-3个词组成,甚至是短语,存在于内容页的标题,还存在于内容当中。长尾词的搜索量非常少,并且不稳定,但是长尾词带来的客户,转化为网站产品客户的概率比目标关键词高很多。
在上面的例子当中,提到了互联网营销当中两个肥肠重要的概念,关键词和长尾词。现在咱们用几个例子来翻译一下这个这条百度百科:比如我是一个篮球少年,想买鞋,那“篮球鞋”在搜索的这个语境下就属于关键词,它是一个单词;但是通常情况下,如果我在某宝上用篮球鞋来进行搜索的话,可能比较难搜到我心仪的鞋子,那我可能就会搜“篮球鞋外观骚气穿上女生就想嫁”,而这个“篮球鞋外观骚气穿上女生就想嫁”就是在搜索这个语境下的长尾词;再举一个例子,“钢化膜”是一个关键词,但是“钢化膜发消息老婆看不见”就是一个长尾词。
弄清楚啥是长尾词之后,咱们再来回答那个问题,为啥要做长尾词挖掘?
从上面的几个例子里面不难看出,长尾词非常核心的一个特点就是:
它代表的需求更明确!
它代表的需求更明确!
它代表的需求更明确!
任何以销售转化为最终目标的经营活动,必然都是紧密围绕用户需求展开的。你是种草带货的家电类博主,你知道某款电饭煲的目标用户是想煮饭快还是电饭煲长得很卡哇伊吗?你是做知识付费的,主要教韩语,你知道想学韩语的人他们需求是啥吗?他们有的可能是想去韩国看欧巴,有些可能是冬奥会看完了想跑到ins上去骂人:
长尾词展示需求
既然长尾词具备这样的特性,那咱们为啥要做长尾词挖掘拓展这个问题的答案其实就已经肥肠明朗了各位,主要来说就两点:
1.1 更容易地把自己的内容往前顶
在进入这部分正题之前,咱们先来看几组数据:
某度搜索指数
在这张图片当中显示的是“少儿英语”以及“少儿英语教材”两个词的百度搜索指数,为了照顾小白读者朋友这里稍微翻译一下,所谓搜索指数用大白话说就是百度用自己的数据捣鼓出来的对某个搜索词条的搜索频次的加权,可以直接反映互联网上的网民对某个搜索词条的普遍关注程度,也就是说搜的人越多,搜的次数越多,这个词儿的搜索指数就越高。上面用到的词是“少儿英语”和“少儿英语教材”,时间跨度是一个月。
从上面的数据里面,其实可以看到,像“少儿英语”这种大词儿的搜索量确实是要比“少儿编程教材”这种长尾词要高差不多十多倍,所以假设咱们现在是一个少儿英语培训机构想在知乎上面发广告,这广告是软是硬咱们先不谈,咱们应该把“少儿英语”作为主要词汇布局在广告的标题以及内容里面吗?看下面这两张图:
“少儿英语”在我乎文章搜索结果
“少儿英语教材”在我乎文章搜索结果
咱们控制变量,假如你用“少儿英语”做标题的来写一个广告文,你必须得把一个获赞542的老前辈搞下去你才能排在搜索结果的第一位,但是如果你用“少儿英语教材”做标题,搞不好你请几个亲戚朋友帮忙点个赞就抢到第一名的位置了。*敏*感*词*的这篇文章里面就不细说了,有一个专门干这事儿的学科叫SEO,中文名叫搜索引擎优化,干的就是把自己的内容或者网页往搜索结果的第一名去顶的事儿,水太深,几篇文章把握不住,有机会以后详聊):
搜索排名与点击率分布
1.2 更准确地发现用户想要啥
用户想要啥,用互联网黑话来说就是所谓的用户需求,用户痛点、痒点还有爽点。
在说到这一点的时候,咱们必须得明确的一件事情就是,用户的需求是用户想的,不是你想的。很多朋友,小到个人大到企业,无论是带货种草、线下开餐饮店、还是说“你有一个改变世界的idea”,都特别容易陷入一种自嗨的情绪里面,咱们来看一下下面这这些句式各位朋友熟不熟悉:
“现在中国短视频平台出海那么迅猛,我在这上面教中文,肯定赚!”
“某某CBD附近全是小资白领,在附近开一家高档一点的红酒雪茄吧给他们谈生意装X,生意肯定好!”
“我有一个idea,我们现在手上有很多大型国企资源,咱们就借鉴当年扎克伯格的经验,搞这种大型国企相亲平台但是面向大众开放,国企里面的都是铁饭碗,相亲市场上都是优质资源,肯定用户量暴增!”
上面的这种类似的句子不知道大家熟不熟悉,可能你自己有过类似的想法,也可能是听到你周围某位工作职责主要是画饼的吹水型PPT选手说过类似的话。当这种想法在人脑子里面冒出来的时候,可能突然觉得,自己就是那个天选之人,成为商业巨子不是梦。但是,说实话,这些所谓的idea大概率都是自嗨。太阳底下没有新鲜事,你能想到的事情别人都能想得到。
一个靠谱的用户需求,绝对不是靠想出来的,即便最初你脑子里面有个猜想,但这个猜想也是需要通过调查去验证的,通过这种调查验证,至少能提高这个用户需求是一个靠谱的需求的概率。
既然是调研,那总得有材料,有数据作为支撑对吧,那这些材料,这些数据从哪里来呢?
长尾词就是一种需求调研的好材料。
老金在这儿用自己举一个例子,顺便来看一组数据说明通过长尾词挖掘来验证需求的道道。
老金在这篇文章里面想干的事儿是向大家介绍一套方法论以及工具,可以自动地挖掘拓展大量的相关长尾词,这玩意儿客观地来说还是一个比较小众的事情,但是这个需求成立吗?再说直接一点,有人愿意为这玩意儿付费吗?咱们来看下面一组数据:
“长尾词挖掘”长尾词竞价数据
这组数据当中,最左边一栏是与“长尾词挖掘”这个长尾词相关的其他一些长尾词。而右边则是其他的一些数据。通过各个流量指数其实可以看到,这些长尾词首先是有人在搜的;通过竞价公司数量、竞价激烈程度以及竞价点击价格来看,有公司愿意为这个长尾词付费,从而曝光自己,说白了就是有公司在投相关的广告。这就说明老金这篇文章背后的需求是成立的,因为有人在搜而且有公司愿意投广告,如果“长尾词挖掘”这事儿不赚钱的话各家公司也不傻,为啥要在这上面投广告呢?
反之,咱们来看一下“国企相亲”这个词儿的相关数据:
“国企相亲”竞价数据
从各个流量指数的情况来看,这个长尾词几乎是没多少人搜的,更别提有没有公司在上面投广告了。那在这个时候,关于这个需求,咱们心里面是不是就要打个问号了?如果这个需求真的成立,为啥没人在网上搜索相关的问题?是没人对找国企里有编制的另一半感兴趣?还是说即使感兴趣,但是对于和大型国企里面的人相亲这件事,大家更倾向于走线下渠道而不是线上渠道?无论是后者还是前者,做一个大型国企相亲的平台应用这事儿到底还靠不靠谱?
为了让这个例子更有说服力,咱们控制变量,转变一下群体,把“国企相亲”换成“富二代相亲”来看一下另外一组数据:
“富二代相亲”竞价数据
从上面可以看出,虽然“富二代相亲”这个长尾词的流量指数也比较差,但是是有公司在这个长尾词上面投广告的,如果这个需求不成立,不能在这个上面赚钱,别的公司花钱投广告干嘛?至少从这组数据上看下来,从以营利为最终目标的角度出发,“富二代相亲”这个需求应该就比“国企相亲”这个需求要靠谱一些。(这个是真实数据,并不是想影射啥)
这里之所以用“国企相亲”来举例子,是因为这事儿老金算是亲历过的,当时产品经理把这个概念提出来的时候觉得这个idea简直不得了,甚至还想封锁消息,禁止和某爱网合作防止别人窃取创意和资源。在这里老金也只能祝这位产品经理背靠的是一个很牛X的团队,有足够的人力、财力以及各方面资源来打开这片蓝海市场了。
BB了这么多,是为了方便小白读者有一个背景上的基本了解,下面就进入正文了,也就是怎么进行长尾词挖掘与拓展。
2. 长尾词挖掘拓展的传统方法
说到长尾词挖掘拓展的传统方法,就不得不说到5118、艾奇关键词这一批SEO工具了,尤其是5118。
像5118网站这一类的SEO工具,只要你给一个关键词之后,就可以很方便地拓展出几万甚至几十万相关的长尾词出来,而且还有各个长尾词对应的流量指数以及竞价等数据。上面的几张竞价数据的截图,就是通过5118得来的数据。关于5118这个网站的具体使用方法,由于篇幅限制,这里就不细说了,懂的都懂,不懂的基本上进入网站之后跟着使用指南走就可以大致知道这个网站是怎么用的。
这里之所以要介绍传统方法,并不是因为传统方法不好用甚至不能用。相反,这些工具都是相当之靠谱的工具,毕竟经历了那么长时间的用户考验了,有些时候老方法就是好方法。但是,对于这类传统的长尾词挖掘方法,终究有其自己的短板或者不足。老金在这篇文章中介绍的方法和工具也并不能取代这些传统工具,但是可以对其中的不足进行一定地补充。下面就来介绍一下传统的长尾词挖掘方法当中美中不足的地方。
2.1 要花钱
这个很好理解,好货通常都不便宜,人家是做生意的又不是做慈善的。
5118各类会员报价
上面这张图是5118的会员收费标准,从280元/年到3699元/年不等,想用这些功能,是要充会员费的。但是说实话,对于非SEO的从业人员,可能你并不需要每次能下载几十万的长尾词数据下来,可能几千个就够用了。有可能你花了280块钱买了一堆冗余不常用的功能。
2.2 不全面
老金在写文章的时候是很讨厌拽一堆专业名词的,心虚的人才喜欢拽一堆别人听不懂的词,说白了只是为了显得自己好像很专业一样,其实是在增加了沟通成本。但是在讲这个部分的时候,老金不得不先科普一个概念,叫做“信息茧房”。
所谓的“信息茧房”,说白了就是一个人只能用自己熟悉的词汇去描述自己脑中的概念,这样就会带来两个结果,一是你熟悉的词汇别人根本不知道是什么意思,当你在用这些词汇去做描述的时候别人也压根儿没办法理解;第二种结果就是你熟悉的描述方式别人不一定能想到。
这话可能看起来有点绕,咱们还是用例子来进行说明。
老金的主业是算法工程师,由于有一定的计算机背景知识,如果我把周围几公里内的租房的相关数据搞到手,从而判断自己应该租哪个房子比较合适的时候,老金可能会在某度上面搜索“Fiddler链家手机抓包”;对于完全没有任何计算机背景知识的人,他们可能会搜索的是“批量查询房屋租赁信息”。上面两个长尾词在文字上完全没有什么相似的地方,但是它们都指向了同一个意图,而这就是很典型的信息茧房。对于老金来说,这个世界上有无数的没有计算机背景的人,它们对于“批量查询房屋租赁信息”这个意图会有成千上万种描述方式,这个靠个人的想象力是很难去想全的;而对于没有计算机知识背景的朋友来说,他们应该连Fiddler是啥,抓包又是啥这些概念都不清楚,所以也不能理解这个长尾词的意思。所谓信息茧房,说白了就是我们脑子里的概念在某种程度上是被我们所熟知的词汇束缚着的。
那在做长尾词拓展挖掘的时候,打破这种信息茧房就非常重要了,因为这意味着你可以挖掘到更多相关的长尾词。对于需求挖掘来说,你有了更多的数据,做分析的时候就会得到更全面的支撑;而对于SEO来说,你有了更多的词汇可以布局到你的网站或者文章里面,这样就可以吃到更多的长尾流量。
但是,通过传统的长尾词拓展方法,其实是没有办法打破这种信息茧房的。这里面的原因是在于,当你用这些传统工具做长尾词拓展的时候,它们其实是基于你用词的相似程度而不是语义的相似程度去做判断的。比如,当我们用“销售转化”作为核心词汇在5118上面做拓展的时候,拓展出来的结果是下面这样的:
“销售转化”竞价数据
看见没,拓展出来的长尾词,必然是收录“销售”以及“转化”这两个词的;也就是说,用这种方法,无法拓展出像“一个新手如何推销产品”或者“让顾客心动的话术”这类似的长尾词,虽然他们背后的意图都是一样的。
那咋弄才能在拓展长尾词的过程当中打破这个“信息茧房”呢?这就要进入到这篇文章的重头戏了,也就是下面最后一个章节。
3. 通过搜索引擎的相关搜索拓展挖掘长尾词
无论是谷歌还是某度,这些主流搜索引擎下面都会有一个东西叫相关搜索。在做长尾词拓展的时候,这个相关搜索真的是个好东西。因为相关搜索其实是搜索引擎所提供的,认为能解决你问题的别人的搜索词条,这里有两点非常重要(敲黑板,划重点):
这些词条是别人搜过的,不是谁胡诌出来的,那这个长尾词本身和它背后的需求就是真实存在的相关搜索在语义上趋近,但是用词上会有非常大的区别
这不就是我们想要的嘛!
还是用上一个章节当中“销售转化”这个词来举例子,当我们用这个词在百度里面搜的时候,咱们来看一下第一层相关搜索会弹出哪些内容:
“销售转化”第一层相关搜索
感觉还行,也几乎收录了“销售”和“转化”两个词,但是当我们点击上图中“销售技巧和话术”这个长尾词之后,所弹出的第二层相关搜索呢:
“销售转化”第二层相关搜索
可以看到,这和第一层相关搜索的用词就有非常大的区别了,但是这些长尾词的意图和“销售转化”这个词的意图是基本上一样的!就这么一个简单的动作,你就拓展了10个长尾词!假如说你内容是一个做销售培训这一块的知识付费的玩家,不管你是在短视频平台上面推广也好,还是在像我乎这样的文字内容平台上推广也好,这些长尾词你只要稍微改改就可以拿着去给文章或者视频取名字了!接下来你可以大力出奇迹,把拓展出来的长尾词全部拿出来,在不同的平台上面发不同的文章或者视频,就基于这些长尾词去给文章或者视频取名字,总有人会这样去搜到你的的!这就叫吃长尾流量!
那么,接下来,咱们就以这个做销售转化的知识付费作为例子,来好好唠唠这个标准流程,怎么通过搜索引擎的相关搜索来挖掘拓展相关的长尾词。
3.1 确定核心词列表
核心词列表其实就是*敏*感*词*,你通过核心词汇在搜索引擎里面搜索,就可以裂变出一堆相关的长尾词。
这里咱们既然是想做销售这一块儿的知识付费,那咱们拓展出来的核心词汇列表大致可以像这样:
[“销售转化”,“销售逼单”,“成交话术”,“线下获客”,“客户关系维护”,... ...]
3.2 第一层裂变
当我们列出了核心词汇列表之后,我们用第一个词在搜索引擎上进行搜索;这个时候,咱们就能得到10个当前核心词汇的相关搜索,就像这个章节的前两张图一样,此时我们需要将这10个相关搜索长尾词当中你觉得确实相关的长尾词复制下来,并且粘贴到一个excel表格里面。
3.3 第N层裂变
在拿到这10个相关搜索长尾词之后,咱们再分别把这10个长尾词输入到搜索栏中进行搜索,这样每一个通过第一层裂变得到的长尾词又能得到10个新的长尾词,也就是说,在第二层列表结束时,理论上最多你能得到10 x 10也就是100个长尾词。
这个过程周而复始,一直到当前核心词汇你已经不想再拓展了,好,咱们用核心词汇列表里面的下一个核心词汇继续做这个操作,一直循环到核心词汇列表用完为止。
3.4 我想偷个懒
上面的这些操作,看起来好像很简单,但是如果你真的这样去做了,相信你会提着你40米的大刀顺着网线来找老金的,这么干真的太累了,你鼠标擦出火星子估计也拓展不出几个长尾词。
老金的slogan既然是要摸鱼摸好鱼,怎么可能会干这种蠢事,工具早就做好了。
如果用老金的自动化工具来做长尾词拓展的话,它的效果就像下面这个视频当中播放的一样,你在旁边嗑着瓜子刷着剧盯着任务执行就可以了:
长尾词拓展自动化工具
在自动化工具执行任务的过程当中,老金绝对没有进行任何的人工干预,就是在电脑旁边着,而所拓展出来的长尾词就大概长成下面这个excel表格的样子:
“销售转化”相关搜索拓展
就像老金之前说的一样,这个方法的核心目的是打破“信息茧房”,并不是取代传统的长尾词拓展方法;事实上,通过这个自动化工具拓展了一批相关搜索之后,你可以把这些相关搜索再拿到5118这样的传统工具当中进行二次拓展,这样你就可以得到海量的相关领域长尾词。
4. 最后总结一下
以上就是这篇文章的全部内容了,如果这篇文章的内容您觉得对自己有帮助的话,劳驾点个赞支持老金一下,毕竟码字不易。
估计读到这里的读者,大部分最感兴趣的是这个自动化工具没错儿吧?毕竟谁不想嗑着瓜子就把一天的工资给挣了呢,这个也没问题,老金的这个工具是免费的,如果你需要的话可以在评论区里面留言,或者直接私信,老金也是个爽快人儿,这点儿福利还是要有的。后期如果想要这个工具的朋友太多,我就直接把工具打包之后挂出来给大伙儿用。
我是老金,祝各位摸鱼快乐,虎年暴富!
经验:Kubernetes 集群中日志采集的几种玩法
简介
对于企业应用系统来说,日志的状态非常重要,尤其是在Kubernetes环境中,日志采集比较复杂,所以DataKit对日志采集提供了非常强大的支持,支持多种环境,多个技术栈。接下来,我们将详细讲解如何使用DataKit log采集。
前提条件
登录观察云,【集成】->【Datakit】->【Kubernetes】,请按照提示在Kubernetes集群中安装DataKit。用于部署的datakit.yaml文件将在接下来的操作中使用。
DataKit 高级配置
1 设置日志级别
DataKit 的默认日志级别是 Info。如果需要将日志级别调整为Debug,请在datakit.yaml中添加环境变量。 - 名称:ENV_LOG_LEVEL
value: debug
2 设置日志输出方式 DataKit默认将日志输出到/var/log/datakit/gin.log和/var/log/datakit/log。如果不想在容器中生成日志文件,请在 datakit.yaml 中写入增加环境变量。 - 名称:ENV_LOG
value: stdout
- name: ENV_GIN_LOG
value: stdout
DataKit 生成的日志可以通过在 kubectl 命令中添加 POD 名称来查看。 kubectl 记录 datakit-2fnrz -n datakit #
『注意』:设置ENV_LOG_LEVEL为debug后,会产生大量日志。此时不建议将 ENV_LOG 设置为 stdout。 Logs 采集1 stdout 采集1.1 stdout日志都是采集DataKit可以采集输出到stdout容器日志,使用datakit.yaml部署DataKit后,默认已启用容器 采集器。 - 名称:ENV_DEFAULT_ENABLED_INPUTS
value: cpu,disk,diskio,mem,swap,system,hostobject,net,host_processes,container
此时会在DataKit容器中生成/usr/local/datakit/conf.d/container/container.conf配置文件。默认配置是 采集除以 /datakit/logfwd 日志开头的图像之外的所有标准输出。 container_include_log = [] # 等价于 image:*
container_exclude_log = ["image:/datakit/logfwd*"]
1.2 自定义标准输出日志采集为了更好的区分日志源,添加标签,指定日志切割管道文件,需要自定义方法。也就是在部署的yaml文件中添加注解。 apiVersion:apps/v1
种类:部署
元数据:
名称:日志演示服务
标签:
app: log-demo-service
规格:
副本:1
选择器:
matchLabels:
app: log-demo-service
模板:
metadata:
labels:
app: log-demo-service
annotations:
# 增加如下部分
datakit/logs: |
[
{
"source": "pod-logging-testing-demo",
"service": "pod-logging-testing-demo",
"pipeline": "pod-logging-demo.p",
"multiline_match": "^\d{4}-\d{2}-\d{2}"
}
]
Annotations 参数说明 source:数据源 service:tag tag pipeline:管道脚本名称 ignore_status:multiline_match:正则表达式匹配一行日志,比如以日期开头的例子(比如2021-11-26)是一行日志,如果下一行不是以这个日期开头,则认为这行日志是上一个日志的一部分 remove_ansi_escape_codes:是否删除ANSI转义码,比如标准输出的文本颜色, 1.3 不是采集stdout 日志打开容器采集器,容器会自动采集将日志输出到stdout。对于不想要的日志采集,有以下几种方式。1.3.@ >1 关闭POD的stdout log采集在部署应用的yaml文件中添加注解,设置disable为true .apiVersion:apps/v1
种类:部署
元数据:
...
规格:
...
模板:
metadata:
annotations:
## 增加下面内容
datakit/logs: |
[
{
"disable": true
}
]
1.3.@>2 标准输出重定向如果开启stdout日志采集,容器日志也会输出到stdout。输出重定向。 java ${JAVA_OPTS} -jar ${jar} ${PARAMS} 2>&1 > /dev/null
1.3.@>3 容器采集器过滤功能如果想更方便的控制stdout日志采集,建议重写container.conf文件,即也就是,使用ConfigMap定义container.conf,修改container_include_log和container_exclude_log的值,然后mount到datakit。修改datakit.yaml如下:---
api版本:v1
种类:ConfigMap
元数据:
名称:datakit-conf
命名空间:数据包
数据:
#### container
container.conf: |-
[inputs.container]
docker_endpoint = "unix:///var/run/docker.sock"
containerd_address = "/var/run/containerd/containerd.sock"
enable_container_metric = true
enable_k8s_metric = true
enable_pod_metric = true
## Containers logs to include and exclude, default collect all containers. Globs accepted.
container_include_log = []
container_exclude_log = ["image:pubrepo.jiagouyun.com/datakit/logfwd*", "image:pubrepo.jiagouyun.com/datakit/datakit*"]
exclude_pause_container = true
## Removes ANSI escape codes from text strings
logging_remove_ansi_escape_codes = false
kubernetes_url = "https://kubernetes.default:443"
<p>
## Authorization level:
## bearer_token -> bearer_token_string -> TLS
## Use bearer token for authorization. ('bearer_token' takes priority)
## linux at: /run/secrets/kubernetes.io/serviceaccount/token
## windows at: C:\var\run\secrets\kubernetes.io\serviceaccount\token
bearer_token = "/run/secrets/kubernetes.io/serviceaccount/token"
# bearer_token_string = ""
[inputs.container.tags]
# some_tag = "some_value"
# more_tag = "some_other_value"
volumeMounts:
- mountPath: /usr/local/datakit/conf.d/container/container.conf
name: datakit-conf
subPath: container.conf</p>
container_include 和container_exclude 必须以image 开头,格式为“image:”,表示glob 规则对容器image 有效。 glob 规则是一个轻量级的正则表达式,它支持 ?和其他基本匹配单元。比如你只想采集图片名收录log-order,图片名不收录log-pay。可以进行以下配置。 container_include_log = ["image:log-order*"]
container_exclude_log = ["image:*log-pay*"]
“注意”:如果某个POD打开了采集stdout日志,请不要使用logfwd或socket log采集,否则会重复采集日志。 2 logfwd 采集这是一个使用sidecar模式的log采集方法,即使用同一个POD中的容器共享存储,让logfwd在sidecar模式下读取业务容器的日志文件,然后发送到 DataKit。具体用法请参考Pod Log采集Best Practice Option 2。 3 socket 采集DataKit打开一个socket端口如9542,日志会推送到这个端口。 Java 的 log4j 和 logback 支持日志推送。下面以SpringBoot集成Logback为例,实现socket log采集。 3.@>1 添加Appender 在logback-spring.xml 文件中添加socket Appender。
logback
${log.pattern}
...
${dkSocketHost}:${dkSocketPort}
UTC+8
{
"severity": "%level",
"appName": "${logName:-}",
"trace": "%X{dd.trace_id:-}",
"span": "%X{dd.span_id:-}",
"pid": "${PID:-}",
"thread": "%thread",
"class": "%logger{40}",
"msg": "%message\n%exception"
}
3.@>2 添加配置 在SpringBoot项目的application.yml文件中添加配置。数据包:
套接字:
host: 120.26.218.200 #
port: 9542
3.@>3 添加依赖 在SpringBoot项目的pom.xml中添加依赖。
net.logstash.logback
logstash-logback-encoder
4.9
3.@>4 DataKit在DataKit的datakit.yaml文件volumeMounts中添加logging-socket.conf文件:#在这个位置添加以下三行
- mountPath: /usr/local/datakit/conf.d/log/logging-socket.conf
name: datakit-conf
subPath: logging-socket.conf
api版本:v1
种类:ConfigMap
元数据:
名称:datakit-conf
命名空间:数据包
数据:
logging-socket.conf: |-
[[inputs.logging]]
<p>
# only two protocols are supported:TCP and UDP
sockets = [
"tcp://0.0.0.0:9542",
#"udp://0.0.0.0:9531",
]
ignore = [""]
source = "demo-socket-service"
service = ""
pipeline = ""
ignore_status = []
character_encoding = ""
# multiline_match = '''^\S'''
remove_ansi_escape_codes = false
[inputs.logging.tags]
# some_tag = "some_value"
# more_tag = "some_other_value"</p>
有关套接字日志记录采集的更多信息,请参阅 logback 套接字日志记录采集最佳实践。 4 日志文件采集Linux主机上安装的DataKit采集在这台主机上登录的方法是复制logging.conf文件,然后将logging.conf文件中logfiles的值修改为日志的绝对路径。 cd /usr/local/datakit/conf.d/log
cp logging.conf.sample logging.conf
在Kubernetes环境下,需要将Pod生成的日志目录/data/app/logs/demo-system挂载到宿主机的/var/log/k8s/demo-system,然后使用Daemonset进行部署数据套件。挂载 /var/log/k8s/demo-system 目录,以便 datakit 可以 采集 到主机上的 /rootfs/var/log/k8s/demo-system/info.log 日志文件。卷装:
- name: app-log
mountPath: /data/app/logs/demo-system
...
volumes:
- name: app-log
hostPath:
path: /var/log/k8s/demo-system
volumeMounts: # 此位置增加下面三行
- mountPath: /usr/local/datakit/conf.d/log/logging.conf
name: datakit-conf
subPath: logging.conf
api版本:v1
种类:ConfigMap
元数据:
名称:datakit-conf
命名空间:数据包
数据:
#### logging
logging.conf: |-
[[inputs.logging]]
## required
logfiles = [
"/rootfs/var/log/k8s/demo-system/info.log",
]
## glob filteer
ignore = [""]
## your logging source, if it's empty, use 'default'
source = "k8s-demo-system-log"
## add service tag, if it's empty, use $source.
#service = "k8s-demo-system-log"
## grok pipeline script path
pipeline = ""
## optional status:
## "emerg","alert","critical","error","warning","info","debug","OK"
ignore_status = []
## optional encodings:
## "utf-8", "utf-16le", "utf-16le", "gbk", "gb18030" or ""
character_encoding = ""
## The pattern should be a regexp. Note the use of '''this regexp'''
## regexp link: https://golang.org/pkg/regexp/syntax/#hdr-Syntax
multiline_match = '''^\d{4}-\d{2}-\d{2}'''
[inputs.logging.tags]
# some_tag = "some_value"
# more_tag = "some_other_value"
“注意”:由于日志是使用观察云采集的,所以日志已经持久化了,不需要保存到主机。因此,在 Kubernetes 环境 采集 中不推荐使用此方法。 PipelinePipeline 主要用于切割非结构化文本数据,或者从结构化文本(如 JSON)中提取部分信息。对于日志,主要是提取日志生成时间、日志级别等信息。这里需要特别注意的是,Socket采集接收到的日志是JSON格式的,需要进行剪切才能在搜索框中通过关键字进行搜索。有关管道使用的详细信息,请参阅下面的 文章。 Pod日志采集最佳实践logback socket日志采集Kubernetes应用最佳实践RUM-APM-LOG联动分析异常检测日志异常检测功能,并配置告警,可以及时通知观察对象异常,观察云报警支持邮件、钉钉、短信、企业微信、飞书等多种通知方式。下面以邮箱为例介绍告警。 1 创建通知对象并登录观察云,【管理】->【通知对象管理】->【新建通知对象】,选择邮箱组,输入名称和邮箱。
2 新建*敏*感*词*点击【监控】->【新建*敏*感*词*】-> 【日志监测】。
输入规则名称,检测指标 log_fwd_demo 是采集日志时候配置的 source,后面的 error 是日志包含的内容,host_ip 是日志的标签,在事件内容可以使用 {{host_ip}} 把具体标签的值输出。触发条件填 1,标题和内容会以邮件的方式发送。填完后点击【保存】。
3 配置告警在【*敏*感*词*】界面,点击刚才创建的*敏*感*词*,点击【告警配置】。
告警通知对象选择第一步中创建的邮件组,选择告警沉默时间,点击【确定】。
4 触发告警应用触发 error 日志,这时会收到通知邮件。

