总结归纳:SEO关键词产出之词频分析(关键词工具篇)
优采云 发布时间: 2022-09-28 08:15总结归纳:SEO关键词产出之词频分析(关键词工具篇)
采自:埃克森数字营销 SEO关键词产出之词频分析(关键词工具篇)
今天有个朋友咨询我了一个问题。
他讲:你的文章我都看了,关于关键词我有疑问,我想做一个新产品,但不知道关键词应该用哪些。这该怎么处理?
今天我将带大家从几个工具开始,教大家如何在不了解产品的情况下,对新产品产出关键词。
一共三个工具,让大家十分钟内学会对新产品产出关键词。
话不多说上工具。
1. Instant Data Scraper
Instant-Data-Scraper是一款谷歌浏览器插件。
在谷歌中搜索instant data scraper, 第一个结果就是。
打开第一个搜索结果。并点击“添加至Chome”, 并在跳出的提示框中选择:添加扩展程序。
这时你的谷歌浏览器中就安装完成了我们的第一个工具。如下图所示。一个类似游泳圈的红白相间的小圆圈的标志就是。
Instant-Data-Scraper实际上是一款网页内容抓取工具。
有了他我们就可以把我们想要得到的关键词数据抓取出来。
下面我们需要思考一下,我们去哪里抓取数据呢?
其实有一个很好的平台,我们很多同行都在那里展示产品,基本做外贸的也都知道,对,就是阿里巴巴国际站。
我们就以今年比较火的一款产品来举例讲解吧。
-无纺布
即使我们不了解无纺布,百度翻译一下起码也能搞出一个关键词:nonwoven fabric.
将这个词放入阿里巴巴搜索。你会得到一个庞大的列表,我这里显示有100页。那把这100页中的词抓取出来,就可以得到我们想要的关键词。
接下来,我们点击刚才安装的instant-data-scraper扩展程序图标。
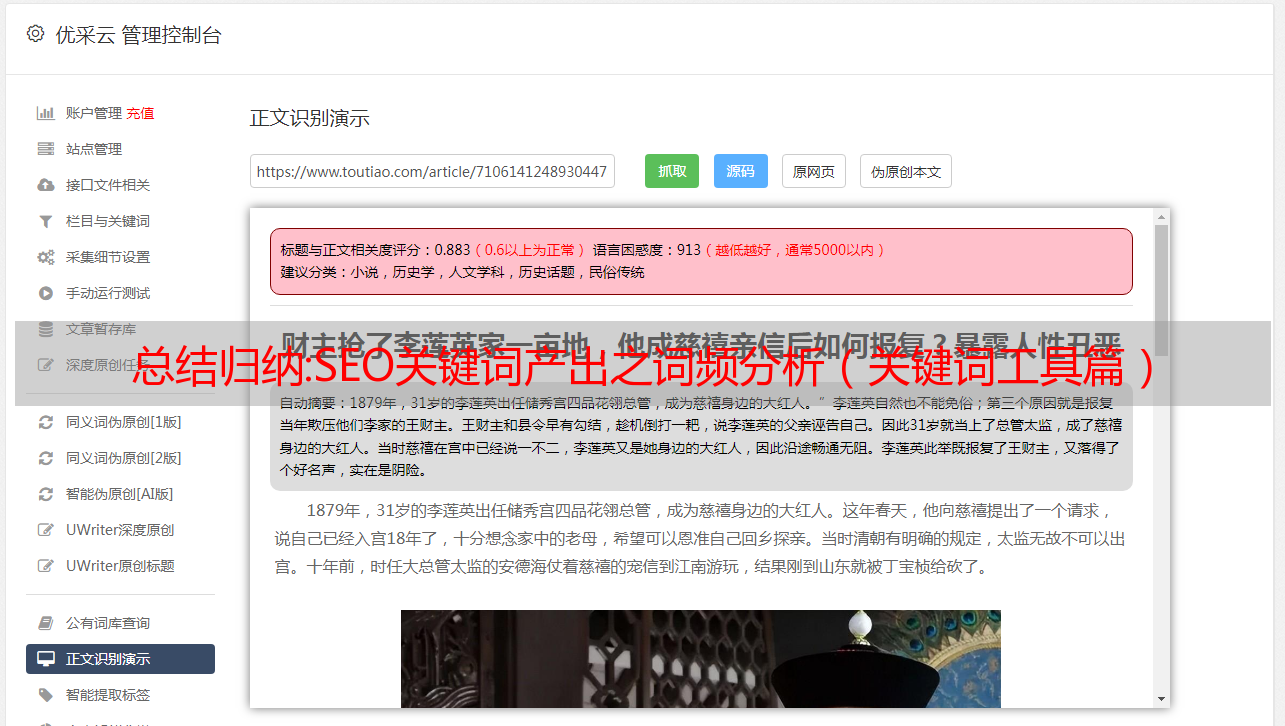
点击try another table。
将红色选择框,定位在阿里巴巴的产品搜索结果区域,如下图。
然后点击:locate “next” button按钮。
然后,在阿里搜索结果页中右键单击:翻页按钮即可。
通过这两部,一是确定抓取区域,二是确定翻页位置。
接下来instant-data-scraper,就可以工作了。
点击,操作界面中的:start scrawling
这时工具就开始抓取数据了。
注意:
至于抓取多少数据,如果你有耐心可以将这100页阿里巴巴搜索结果全部抓取完毕,也可以抓取几十页,也差不多了。时间原因我只抓取了其中的30页。
抓取完毕后,点击操作界面的:CSV或XLSX下载你想要格式的抓取结果。(我选的CSV)
将文件下载并保存至相应的磁盘位置。
接下来,请出第二个工具。
2.online word counter
Online word counter是一款单个单词词频分析工具。
打开网页。
再打开通过第一个工具下载的表单文件。
并在文件中找出产品标题的那一列。
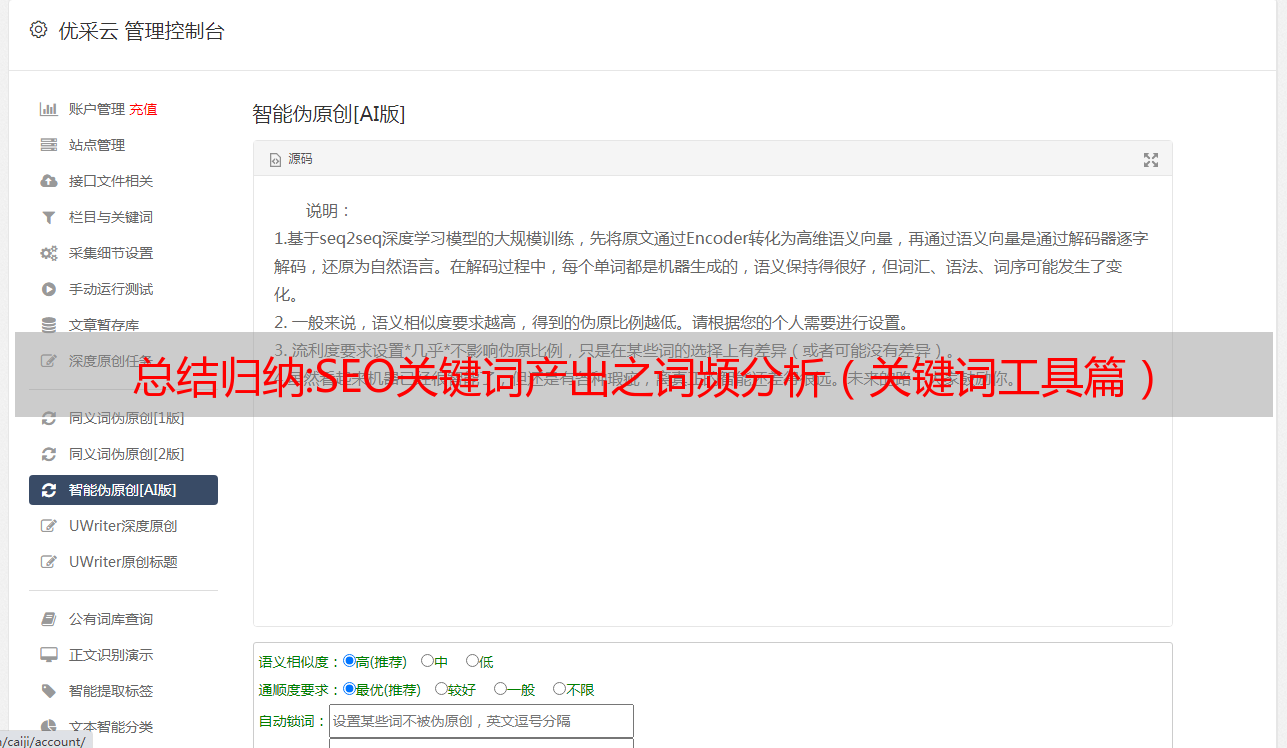
复制整列,然后粘贴到工具online word counter中。并点击“Count words”按钮。
你就会得到单个单词的频率列表。
如上图所示,数字越大代表出现的频率越高,通俗讲就是阿里巴巴中的无纺布供应商经常用的那些关键词。
这个工具有个特点,就是只分析单个词的词频数据。
这时,有人肯定会问,那我们要想分析两个词,三个词,四个词的关键词频率呢?
别慌,我们还有第三个工具。
3. Dcode-Phrase Counter
Dcode-phrase couter可以对多个词的词频进行分析。来获得例如两个单词、三个单词、甚至四个单词的关键词频率。
操作很简单,跟第二个工具类似。首先打开工具网页。
再次复制表格中的标题列,然后粘贴到工具中。
输入要分析的关键词词频的单词数量(两个词的关键词,还是三个词的关键词,可以依次分别进行分析)。
然后点击“Count”按钮。
工具将帮你产生,三个单词的关键词词频分析列表。
点击下载按键,即可将分析结果下载下来。
注意:多个单词的词频分析不建议选择太长。2-4个单词为宜。
这样通过上面这三款工具协调作战,我们就得到了一个新产品的所有关键词频率分析列表。
4.其他网站的词频分析。
我们今天主要是以阿里巴巴中搜索nonwoven fabric为例来进行词频分析。
其实我们有了这三款工具后并不只是局限于阿里巴巴网站。我们还可以在谷歌中进行同样的操作。
谷歌输入关键词,然后抓取数据,然后在放入第二和第三个词频分析工具,你就可以得到谷歌中你的同行的词频分析结果。(因为操作雷同,这里就不具体展开讲了)
有了这些词频分析,你就知道那些关键词是高频率词,高频率往往也意味着高热度。你完全可以将采集来的高频词用于你的内容营销。
归纳总结:SEO如何处理采集内容
额外的:
这么久才开通留言功能,好丢人,这篇是本渣渣图新鲜试试留言功能用的,没有干货
采集内容对 SEO 有效吗?
有人说采集的内容对搜索引擎不太友好,也不容易获得排名。这是确定的和不可避免的。
对于大多数网站来说,采集 的内容一定不如 UGC,精心编辑的内容。但是,搜索引擎能够获取到的原创内容的数量已经没有以前那么多了。毕竟内容制作平台已经转移,早就不再专注于网站了。其他几个搜索引擎也互相捕捉,更不用说小型网站了。
所以 采集 的内容仍然有效,但是对 采集 的内容进行后处理的成本越来越高。
采集内容后处理
担心采集内容效果不好,或者容易被K,主要看如何对内容进行后期处理。例如:
比如你从沃尔玛拿一篮猕猴桃原封不动的放在家乐福,最多就是原价,因为猕猴桃还是猕猴桃,货还是一样的。但是把猕猴桃挤成汁(改变形状),装瓶加点水(改变颗粒大小),在711卖(换平台),价格可以翻倍(增值)
为什么?
如果将“采集 content”比作“kiwi fruit”,“采集 content”的后处理策略如下:
采集内容全流程
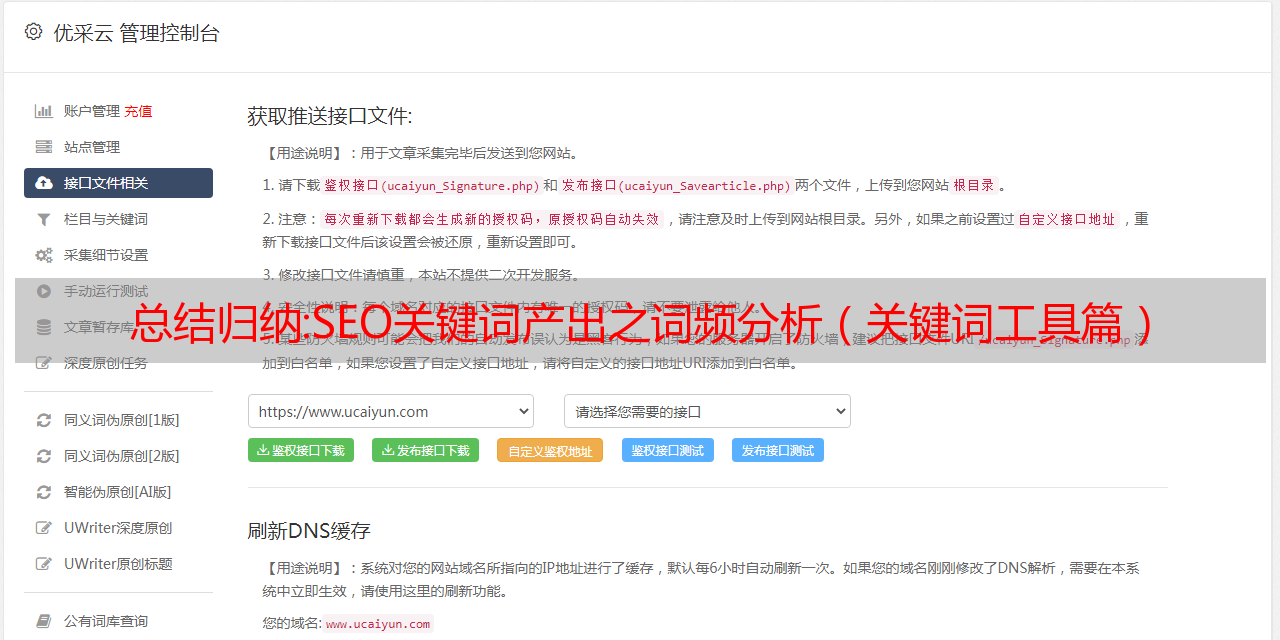
关于“采集内容处理”,从爬取到启动的整个过程,必须解决以下问题:
采集内容从何而来?
对于认真认真的人,更适合定位采集,购买专业资料。
针对采集,只捕获了网站的几个特定范围,与本站内容的漏洞高度相关。
对于那些不是认真的站的人来说,有更多的选择可供选择。你可以抓取所有触及边缘的内容,并且需要注意大音量,因此无需限制某些站点的抓取。有人叫它Pan采集
设置几个主题,直接抓取各大平台的搜索结果。大平台是什么意思?海量内容集中的地方:各种搜索引擎、各种门户、今日头条、微信微博、优酷土豆等。
采集如何抓取内容?方向 采集:
算了吧,像往常一样抓住它。
潘采集:
定向爬虫仅限于网页模板,在此基础上增加了几种内容分析算法,将内容提取出来,变成一个通用的爬虫。
很多浏览器插件,比如印象笔记,都有很多类似“只看文字”的功能。点击只显示当前浏览网页的文字信息。很多人将这样的算法移植到python、php、java等编程中。从语言上来说,只是搜索。
采集内容是如何处理的?
两个顺序过程:
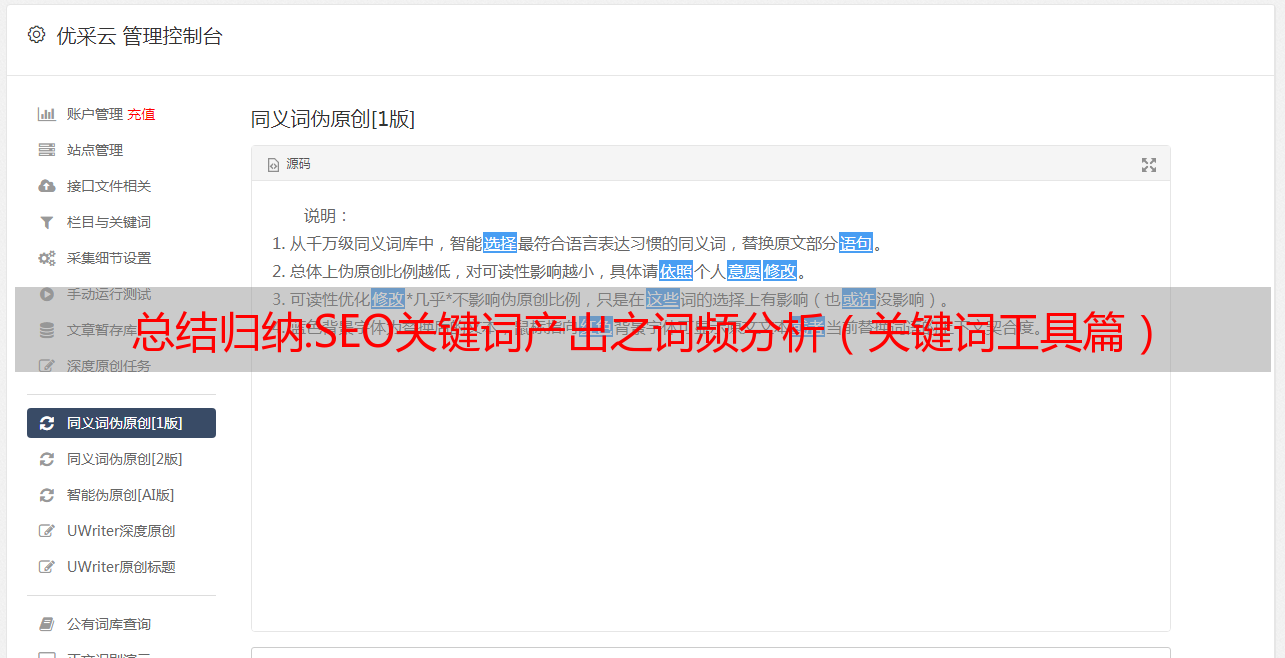
原创内容的处理
百度专利称,搜索引擎除了根据文本判断内容的相似度外,还会根据 HTML 的 DOM 节点的位置和顺序进行判断。如果两个网页的 HTML 结构相似,也可能被视为重复内容。
所以采集的内容不能直接上传,必须清理源码。每个人都有不同的方法,但通常会执行以下操作:
删除汉字<100个字符
text = re.sub("[\s+\.\!\/_,$%^*(+\"\']+|[+——!,::。?、~@#¥%……&*()“”《》]+".decode("utf8"), "".decode("utf8"),newcontent)
text2 = re.sub(']*?>','',text)
words_number = len(text2)
删除垃圾邮件
如“XXX网络编辑器:XXX”、邮箱地址等。.
组织处理的内容
其实只是形式上的改变。我之前写过一篇文章,介绍了几种“组织内容”的方法,见:

