直观:采集器
优采云 发布时间: 2022-09-28 04:13直观:采集器
CategrafOn this page基本介绍
Categraf 是一款 all-in-one 的采集器,由 快猫团队 开源,代码托管在两个地方:
Categraf 不但可以采集 OS、MySQL、Redis、Oracle 等常见的监控对象,也准备提供日志采集能力和 trace 接收能力,这是夜莺主推的采集器,相关信息请查阅项目 README
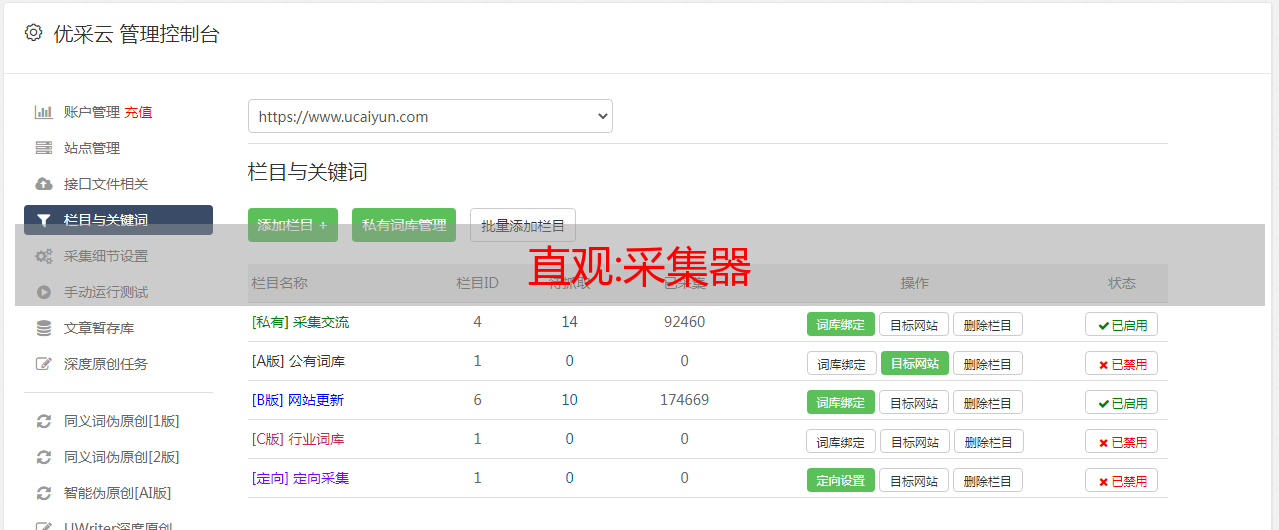
Categraf 采集到数据之后,通过 remote write 协议推给远端存储,Nightingale 恰恰提供了 remote write 协议的数据接收接口,所以二者可以整合在一起,重点是配置 Categraf 的 conf/config.toml 中的 writer 部分,其中 url 部分配置为 n9e-server 的 remote write 接口:
[writer_opt]# default: 2000batch = 2000# channel(as queue) sizechan_size = 10000[[writers]]url = "http://N9E-SERVER:19000/prometheus/v1/write"# Basic auth usernamebasic_auth_user = ""# Basic auth passwordbasic_auth_pass = ""# timeout settings, unit: mstimeout = 5000dial_timeout = 2500max_idle_conns_per_host = 100
采集插件
Categraf 每个采集器,都有一个配置目录,在 conf 下面,以 input. 打头,如果某个插件不想启用,就把插件配置目录改个名字,别让它是 input. 打头即可,比如 docker 不想采集,可以 mv input.docker bak.input.docker 就可以了。当然了,也并不是说只要有 input.xx 目录,就会采集对应的内容,比如 MySQL 监控插件,如果想采集其数据,至少要在 conf/input.mysql/mysql.toml 中配置要采集的数据库实例的连接地址。
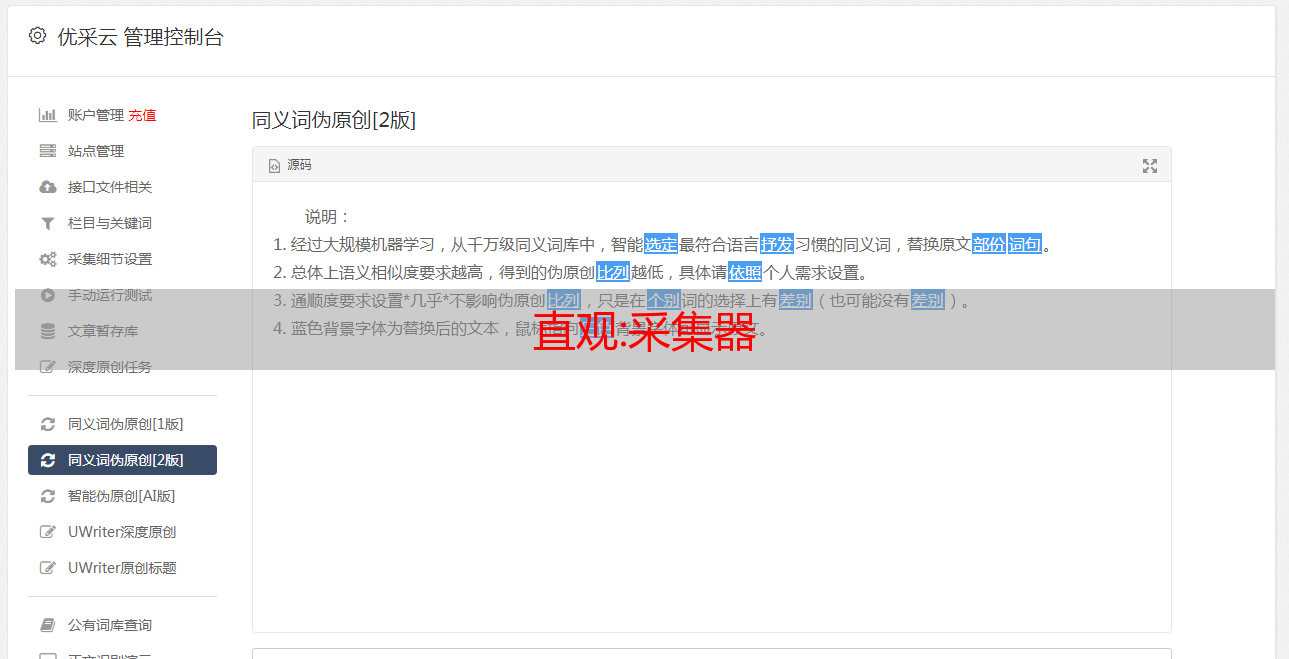
每个采集插件的配置文件,都给了很详尽的注释,阅读这些注释,基本就了解如何去配置各个插件了。另外,有些采集插件还会同步提供夜莺监控大盘JSON和告警规则JSON,大家可以直接导入使用,在代码的 inputs 目录,机器的监控大盘比较特殊,放到了 system 目录,没有分散在 cpu、mem、disk 等目录。
很多采集插件的配置文件中,都有 [[instances]] 配置段,这个 [[]] 在 toml 配置中表示数组,即 instances 配置段可以配置多份,比如 oracle 的配置文件:
# collect interval, unit: secondinterval = 15[[instances]]address = "10.1.2.3:1521/orcl"username = "monitor"password = "123456"is_sys_dba = falseis_sys_oper = falsedisable_connection_pool = falsemax_open_connections = 5# interval = global.interval * interval_timesinterval_times = 1labels = { region="cloud" }[[instances]]address = "192.168.10.10:1521/orcl"username = "monitor"password = "123456"is_sys_dba = falseis_sys_oper = falsedisable_connection_pool = falsemax_open_connections = 5labels = { region="local" }
address 可以指定连接地址,如果想监控多个 oracle 实例,一个 address 显然不行了,就要把 instances 部分拷贝多份,即可做到监控多个 oracle 实例的效果。
当然,更多信息请查阅Categraf README,README 中有 FAQ 和 QuickStart 的链接,可以帮助大家快速入门。
直观:舆情监控实验室系统参数.doc
性能指标
性能描述
主要功能
互联网舆情监控产品应收录四个功能子系统:舆情数据采集子系统、舆情数据处理子系统、舆情分析子系统、舆情门户应用子系统。
舆情数据采集子系统
舆情数据采集子系统的数据采集对象主要是互联网网站和网页,数据源主要有两种,一是通过指定范围的网站对其进行抓取采集,另一种是通过baidu、google等进行全网的数据采集监控。在数据采集过程中,收录了对于正文内容的自动识别、文章去重与相似度分析、自动生成摘要和关键词等多项中文语言处理技术。
此外,数据采集子系统还能够针对网页中的图片、文档资源文件进行采集下载,具有生成网页图片和快照、实现网站自动登录、利用***下载、JS自动识别判断、分布式采集等多项功能。
2) 舆情数据处理子系统
舆情数据处理子系统主要是针对采集子系统采集的数据进行整理、处理。主要功能包括:
舆情数据管理:包括对于数据的整理、编辑、删除、新增等维护工作。
门户信息配置:系统可以自动生成前端门户平台的信息,管理员也可以通过后台配置将需要重点呈现的信息置于门户中去,同时,管理员也可以对门户的一些频道、热词、专题进行管理和设置。
简报管理模块:通过设置舆情简报模版,可以按天、按月、自动生成舆情简报,也可以手动选择信息生成简报,同时对于已生成的简报提供可视化的编辑界面。
3) 舆情分析子系统
舆情分析子系统功能分为统计和分析两部分。
统计主要是对于舆情内容的统计,信息站点分布统计、时间统计、具有折线图、柱状图、饼图多种表现方式。
舆情分析功能包括,自动聚类、热词发现;正负面信息研判;事件发展趋势分析;热点人名、地名分析;
4) 舆情门户应用子系统
舆情门户应用子系统是根据客户的行业特点与行业需求,定制的一个舆情展示、呈现平台,通过该平台可以将舆情系统中采集到的信息、分析结果、生成的简报、以图文方式进行展现,提供给用户和各级领导浏览、下载。
功能及特点:
(1)核心技术
A信息雷达
B网页块分析正文抽取
C自动分类,聚类
D支持多种检索语法
E信息指纹去重
F多语言,编码格式自动识别
G分布式系统、支持亿级数据检索
H智能摘要、关键字提取技术
(2)功能列表
A信息雷达
通过网络雷达系统,可以自己定义需要关注和监控的网站、栏目、或某段IP地址,作为采集源,并可以按照行业或分类进行管理。
在菜单中也可以配置监控网站的优先级,刷新速率,监控深度等设置。
在进入监控状态时,系统会自动执行雷达指令,对需要监控的网站或网址进行扫描,对于未更新的页面会自动跳过。
B自动聚类、分类
自动聚类、分类功能,可以将雷达采集的信息进行二次处理,帮助用户对数据进行整理,系统支持人工分类,也支持基于统计模型的自动分类。
C监控管理
用户可以自行设置监控的词语或语句,并可根据词语分类,例如:国际、军事、政治等。并可以设置发现敏感词汇的处理方式,以email或短信方式实时提醒。保留原创网页快照以备追踪
热点信息、热门话题自动发现。
文本关联分析,根据文本相似度计算,找到相似的文本和内容,根据发布的时间和IP,可以追踪到内容的传播过程和途径。
D统计分析
分布统计:通过图表展示监控词汇和时间的分布关系以及趋势分析

