干货:知乎引流技巧:如何批量采集没人回答的大流量问题?
优采云 发布时间: 2022-09-28 03:16干货:知乎引流技巧:如何批量采集没人回答的大流量问题?
你好啊,我是阿蓝
本来打算完善一下如何打造个人品牌的文章然后分享给大家的,结果发现写起来是一个不小的工程,还蛮难写的,所以临时换成分享一个知乎引流技巧
知乎这个平台大家应该不陌生吧,是国内最优质的问答平台,这一问一答之间,就是在解决问题
帮人解决问题就可以变现,所以知乎的价值我就不多说了
知乎最典型的流量入口就是问题,一个浏览量大,关注度高,但是没什么人回答的问题,我们叫它蓝海问题
这种问题你去回答非常精准的吸引大量目标用户,但是找这种问题不容易
看完今天阿蓝的文章,你就可以批量采集知乎蓝海大流量问题
准备工具
好了,齐活了
具体采集操作步骤
一,打开知乎,搜索你想要引流的话题
比如用知乎搜索吸尘器,如图所示,把这个网站地址复制下来
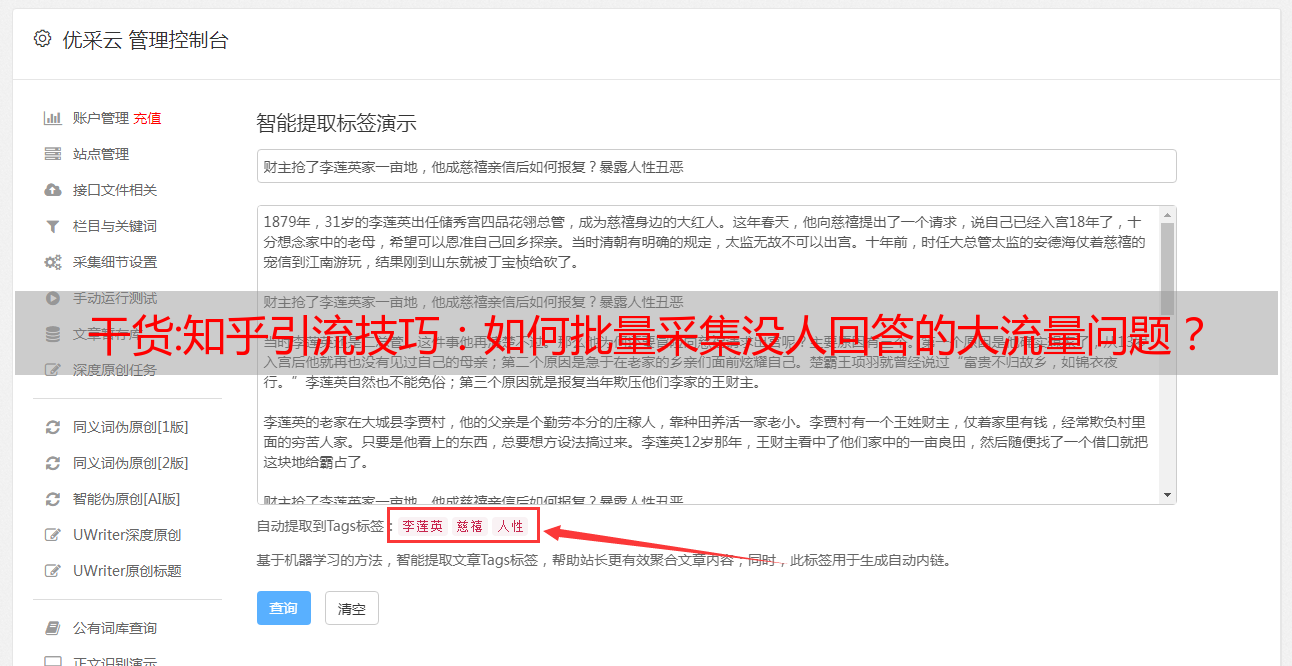
二,打开优采云采集器,复制网站地址到采集框里,点击智能采集
直接复制,然后点击,很简单
三,来到采集页面,任意点击一个问题
四,设置需要采集的数据
这些数据就是我们用来判断蓝海问题的依据
点击左下角的添加字段然后点击采集对象(浏览量+回答量)添加
然后点击保存
五,开始采集数据
点击开始采集,软件就会自动采集数据了
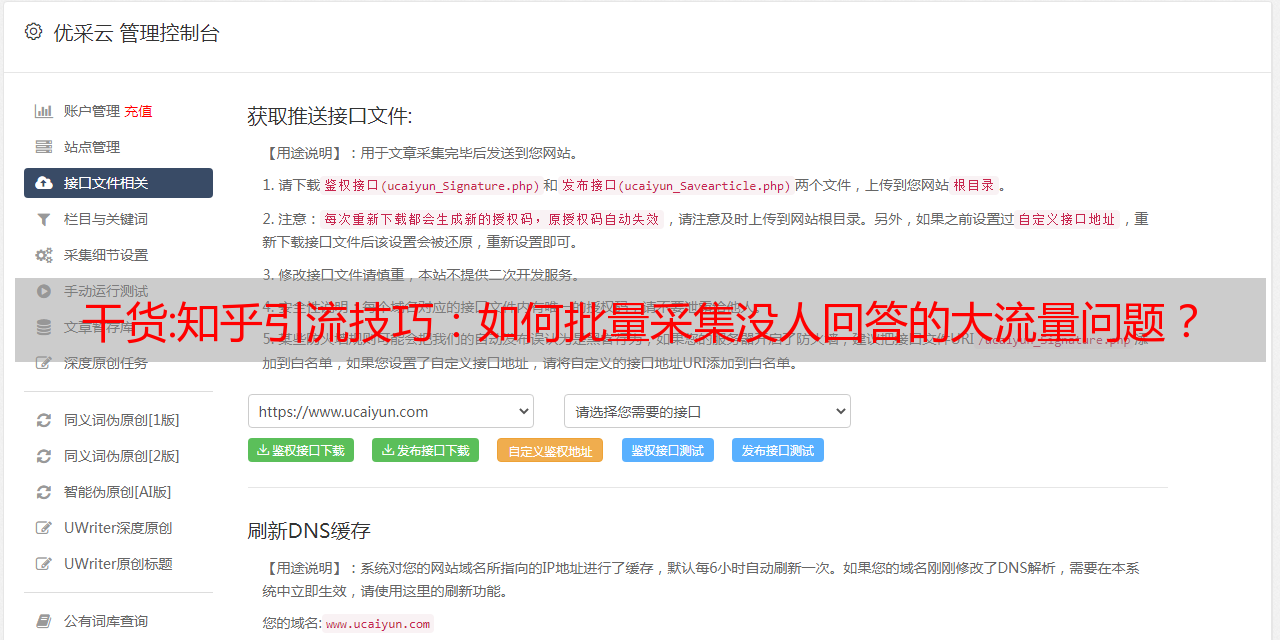
然后你会得到一份这样的表格,也就是采集的数据
六,处理数据,得到蓝海问题
打开表格,点击数据-删除重复项-选择列a-确定
接着新起一列,输入函数【=浏览量/回答数量】,按照降序排序
数字越大的,越值得回答,如图这就是一个筛选出来的蓝海问题
四万浏览量,只有11人回答,你去回答轻松就搞到流量
小结
这个方法就是简单的利用了采集工具,快速得到想要的结果
这个工具其实可以更简单,输入关键词,就吐出蓝海题,会编程的话很快就搞定了
所以阿蓝也在偷偷学编程,以后开发好用的工具给阿蓝的朋友们使用(累计打赏99,成为阿蓝好朋友)
好了,今天的分享就到这里了,希望大家也学会用工具省力~
我是阿蓝,在循环流量实验室为你分享,有价值的东西需要大家鼓励支持。
干货内容:权重站,流量站的内容从何而来?如何生成?
这两年,随着传统seo的没落,曾经在公司工作的seo达人也开始将目光投向了称重站和交通站的市场。为什么,流量权重快,卖的时候钱也快。当然,这个投资也是相当大的。首先要解决的是内容!
那么电站的内容从何而来?
主要来源:自媒体、APP、竞争对手网站、其他相关资源网站
自媒体的大部分内容都是相对于百度被屏蔽爬取的,所以很多人在发布收录的采集自媒体的内容后都会得到不错的效果。但是有些自媒体采集成本比较高,或者大部分站长自己都无法采集。
APP采集,难度更大。这就需要专业的爬虫工程师对APP进行逆向获取相应的内容。
相对而言,敌手站点和资源站点比较好采集,采集也不算太难。但效率是个问题。
但在采集之前,有一个问题需要先搞清楚,那就是电站适合什么样的行业,适合什么样的内容?
相信做过一点研究的人发现,那些行业内容量大,关键词内容量大,而原创内容成本相对来说比较难或者内容获取比较简单。
几个栗子:成语、诗歌、天气、句子、散文、作文等。
这些行业都具有上述特点。
然后,在选择了合适的行业之后,就是挖词的问题了。这很简单。先不说,说说内容的构成吧。
权重站的内容是如何产生的?
主要有两种方法:
伪原创,我该如何伪原创?也就是使用市面上所谓的AI伪原创工具。 优采云 现在好像有对应的插件了。这个道理也很简单,我就不说了,自然明白。说的透彻,会得罪很多人。
聚合拼接,这也是一种很常见的方式。将与关键词 相关的几条内容聚合起来形成新的内容是一个很好的原创。当然,这里涉及到很多技术性的东西。看个人是否在意。例如,如何删除其中的垃圾邮件?我有一个 关键词,如何找到与之关联的 文章?如何保证文章的相关性?如何删除重复的 文章 等等。
当然,原创或伪原创内容还有其他的小技巧。只是这些方法仅限于特定领域,并不具有通用性,这里就不多说了。
今天在这里为您提供一个很好的资源,如果您想赚钱作为体重网站或流量网站。但是由于内容缺乏,或者内容被找到了,不知如何处理,为了保证内容的相关性,请继续阅读。
其实以上流量站类型的内容都可以在问答平台采集、360问答、百度知道、悟空问答等进行。
上个月众筹了360问答的采集脚本,也提供了对应的文章聚合发布脚本。基本上使用它的同学每天都能轻松采集百万级内容。但是有个问题是360问答的内容比较少,很多关键词都找不到对应的内容。可能是内容的版权问题或其他原因。
为了解决这个问题,今天给大家带来百度知道的采集脚本。百度知道的内容很多,但是由于百度的反爬机制,很多站长都不能轻易采集。于是我加入了爬虫老大,开发了百度知道的采集脚本。已经运行一个多月了,没有任何问题。
首先说一下脚本的作用:
自动调整线程数
自动判断关键词与标题的相关性,对相关性较差的内容不判断采集。我们都知道,并非每个搜索结果都是相关的。可能有很多与目标关键词无关的结果,脚本会自动过滤掉。
可以设置字数限制以过滤太短的答案。少于指定字数的答案将不被处理采集。
对于有固定词干的行业,可以只设置采集有词干的答案,不设置采集不带词干的答案,进一步增强内容的相关性。
采集结果直接存入MySQL数据库,方便后期聚合发布。提供对应的聚合发布脚本。
以上是脚本的功能,所以想要购买脚本的朋友,在做决定之前需要阅读以*敏*感*词*意事项:
脚本需要代理并且必须自费购买。目前仅支持猿人云的隧道代理。您可以每天、每周或每月购买代理,如果您提供接口,则可以使用它们。代理费大概是一个月523元。这个是对方的,与我无关。我也用他家的,主要是好用。
如果你的内容不被百度知道,那就没必要买了。
脚本是用python3.8 版本编写的。它需要安装python环境。如果你购买了这个,会有相应的教程。完全不用担心。
脚本提供一年更新服务。一年后,如果出现问题需要重新编写脚本,将收取额外费用。
目前测试,如果带宽好的话,每天至少采集30万条以上的内容,完全够用了。不同的行业不一样,有的行业一天可以采集近100万条内容。
关于费用的问题:
当前价格如下:
参加过我的VIP课程的同学,费用是800/人。
未参加的学生,1200/人。
同时购买360问答和百度知道,两个加起来1500/人
如果需要同学请联系我:

