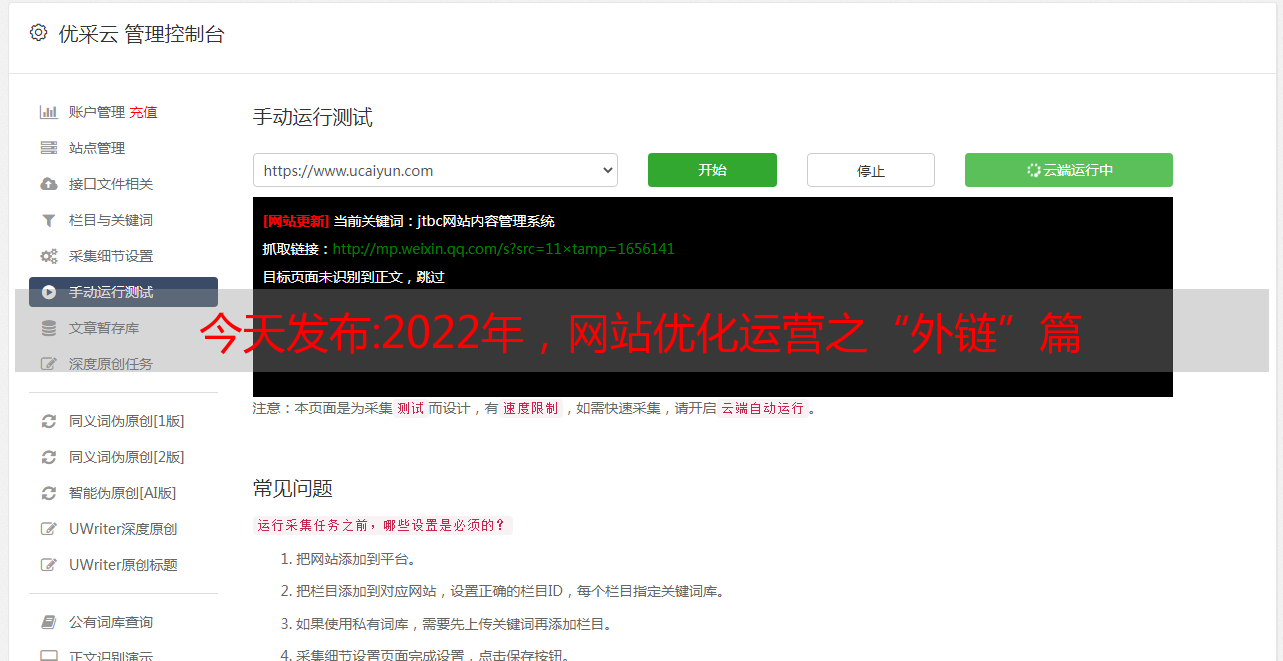
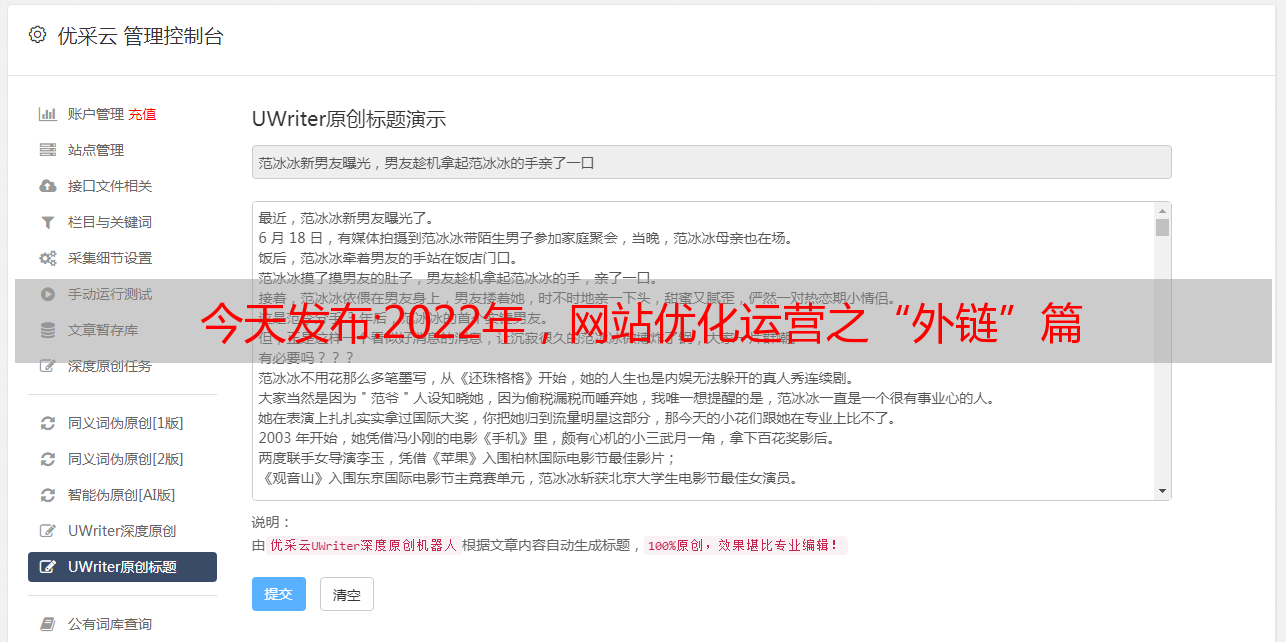
今天发布:2022年,网站优化运营之“外链”篇
优采云 发布时间: 2022-09-26 15:13今天发布:2022年,网站优化运营之“外链”篇
在网站优化的过程中,我们经常会谈到一个名词:外部链接,它在整个SEO优化中起着重要的作用,是SEO人员饭后热衷讨论的话题。
那么,什么是外链,如何正确理解外链?
根据以往外链优化的经验,蝙蝠侠IT将通过以下内容解读外链:
什么是外部链接
简单理解:外部链接主要是指互联网上的其他网站,以链接的形式,指向自己的网站行为,这通常和自荐都是原因,但也包括被动外部链接。连锁建设。
反向链接的重要性:
基于SEO,外部链接通常对网站优化有如下影响:
①提高百度爬虫的爬取频率,有利于页面收录。
②优质的外链有利于提升页面排名。
③大量权威外链指向提高搜索引擎的信任度。
④外部链接是网站相互链接,是建立关联的重要媒介。
反向链接有哪些类型?
一般来说,作为SEO人员,我们都希望获得一定数量的免费外链。毕竟,发送外部链接是有一定成本的。因此,有时,我们可以尝试通过以下渠道进行网站外链建设:
①外部新闻链接:外部新闻链接一般有两种主要类型,一种是知名媒体的新闻源外部链接,另一种是垃圾新闻外部链接站群。
②论坛外链:一般来说,论坛外链主要是指论坛帖子中的外链,也包括一些论坛签名的外链。
③博客外链:主要讨论博客内容页面中的外链,也可参考博客评论中的外链。
④视频外链:通常是早期SEO运营过程中可能会用到的一种策略,一般在视频标题和介绍中留下外链。
⑤图片外链:主要是指通过超链接的形式在内容页面中为图片添加外链。
⑥网盘外链:是我们早期在介绍网盘时留下的外链。有时,它也可以是标题的外部链接。
⑦软文外链:类似于新闻外链,但对内容做了一些润色,有利于内容的二次分发,提高外链的转发率。
⑧B2B外部链接:主要指B2B上发布的链接网站,一般包括B2B友情链接、B2B产品链接、B2B信息链接等。
关于反向链接的常见误解:
1、权威的外部链接很重要
作为SEO外链推广者,我们知道权威的外链很重要,但是有时候,来自权威网站的外链的形式很重要,比如:
①外部链接的位置,是否出现在核心推荐区。
②外部链接是否添加nofollow标签。
③外部链接的可访问性,例如:是否是无法点击的纯文本外部链接。
2、外链比内链更有效
外链之王是早期SEO优化的重要名词,但这并不意味着外链是唯一影响网站排名因素的因素,内链同样重要。
当你通过外链获取权重时,需要使用内链有效分配这些权重。
同时,内部链接具有提高网站页面相关性的作用,合理引导蜘蛛正确理解页面之间的相关性。
3、无关的外部链接没用
基于搜索算法的角度,相关性只是一个参考因素。更多判断外链是否有效,主要参考外链资源页的评分。比如排名高,影响力大。
因此,对于一些排名高、流量大、内容不是特别相关的外链,还是有一定效果的。
随着时间的推移,您的一些反向链接来自权威网站,例如未编入索引的页面,那么它实际上是无用的。
4、图片链接没用
是否对图片的外链有用,我们分为两部分,例如:
①使用ALT标签,堆叠关键词,形成外链,不建议这样做。
②常规图片外链还是有一定效果的,不要作弊。
网站外链推广有哪些方式和形式?
通常在发布外链的过程中,一般来说,对于网站外链的推广,会采用以下两种形式,比如:
①手动外链:顾名思义,手动外链主要是外链专家,自己发布,注册大量相关账号,发布内容,附上链接。
2 外链群发工具:外链群发工具往往会借助一些软件批量发布,以减少相关环节人员的工作量,但有一个小细节需要注意,那就是就是,尽量避免使用超级外链这样的工具,瞬间增加大量搜索结果的反向链接,对SEO来说意义不大。
总结:关于如何正确理解外链,我们还有很多细节要讨论。以上内容仅供参考!
蝙蝠侠IT转载需要授权!
最新版:百度移动搜索建站优化白皮书(全文)
1 前言
手机百度是6亿用户使用的手机搜索客户端,在获取中国用户信息方面发挥着不可替代的作用;移动搜索引擎每天分发数亿流量到优质安全网站,满足用户搜索需求;而对于广大站长来说,优质安全的网站有助于在搜索引擎中获得良好的排名和展示,从而吸引更多的用户,获得更多的流量。
移动搜索引擎优化是指从建站到吸引用户,贯穿所有流程,让百度搜索的重要合作伙伴——广大站长充分了解百度搜索引擎规则,构建合理的搜索引擎。并按规则安全构建网站,优化网站,更好的获取搜索流量;百度搜索资源平台历时3个月,走访了搜索内部的各个技术部门,剥离了百度搜索内部的技术原理,整理出了《百度移动搜索网站优化白皮书》,希望与各位站长一起为用户提供拥有健康、安全和高效的搜索环境。
2 网站构造
2.1 域选择
网站域名的选择,不仅可以让用户快速直观的了解网站的定位和域名设置,还会影响网站被搜索的抓取。因此,选择一个简单、易记、安全的域名是网站建设初期最重要的一步。
2.1.1 域名选择注意事项
网站建立之初,建议网站的域名独立好记;独立移动台的域名选择也遵循这个规则。
移动站的域名需要和PC站的域名分开。不建议移动站与PC站共享域名; Adaptive网站 可能不会考虑到这一点。
网站在域名选择上,主要有两个建议:
√ 建议使用比较常见的域名后缀,如.com\.cn\.net等;
√如果网站追求稀有域名后缀的个性化使用,为保证搜索效果,请到百度搜索资源平台(原百度站长平台)进行现场验证。
2.1.2 使用子域或目录
网站是需要建立子域名还是划分多级目录,可以根据网站自身定位和网站内容量级来确定。一般来说,对于综合类或者内容比较多的网站,可以根据不同的二级域明确划分内容;而如果网站的内容较少,不建议打开太多的网站子域。
比如对于博客风格的网站,有的网站给每个博客作者一个单独的三级域,但是如果作者发表频率较低,整个三级域就处于低更新状态频率,太低的发布频率对搜索引擎不友好。
2.2 内容发布系统
百度支持内容发布系统,无论是网站自建还是使用第三方建站系统;所有的发布系统,除了遵循组织有序、逻辑清晰的网站外,还应注意网站只有解决建设的安全问题,避免网站的隐患,网站的价值才能体现出来。 @网站 得到更好的改进。
2.2.1自建内容发布系统
网站自建内容发布系统,注意事项包括:
√ 主要内容清晰,可以很好的识别和区分;
√ 不要在后台自行设置发布时间,按照发布时间和显示时间进行;
√ 内容发布系统中各个表单的设置合理。比如标签的设置不宜过多,不宜列出关键词;
√ 分类明确,分类主题的文章应在相应分类下公布;
√标题匹配,不卖狗肉,欺骗搜索引擎流量,损害用户体验;
√ 段落清晰合理,字体大小适中,字体颜色不宜使用与背景色相近的颜色;
√ 内容目录划分清晰。详见2.3章节中网站的结构设置。
2.2.2 第三方发布系统
使用第三方发布系统搭建网站,站长需要注意以下几点:
√ 不建议频繁更换模板主题;
√ 与wordpress等系统类似,不建议使用过多的插件,会影响网页的打开速度;
√ URL 伪静态处理,命名约定,层次清晰;
√ 开源建站系统存在诸多安全隐患,使用过程中一定要做好一些安全设置和优化。
2.2.3 页面生成规范
无论网站自建发布系统还是网站使用第三方建站系统,网站页面生成时应注意以下几点:
√ 网页结构清晰,各分类名称设置醒目;
√ 导航和面包屑导航设置合理,机器可读,位置显着,用户在网站中可以轻松知道所访问页面的位置;
√ 没有遮挡主要内容的广告元素;
√没有三俗的图文元素;
关注网站构建系统安全问题,消除网站安全隐患。
访问请求中的content-type需要根据对应的类型正确设置,如下图:
另外,页面规范标准,建议参考搜索学院发布的《百度搜索移动友好(Mobile Friendly)标准V1.0》
2.3 网站结构
网站结构的合理设置是网站被快速抢占并获得搜索流量的基础;由于网站结构设置不合理,无法快速识别网站爬取案例在百度日常反馈中经常看到,更改网站的域名也会造成一定的损失网站,所以希望各位站长从建站之初就注意网站的结构设置。 ,避免不必要的损失。
2.3.1 网址结构设置
对URL构建是否有严格要求,请看以下几点:
√ 在构建网站的结构和制作网址时,尽量避免非主流设计,追求简洁美观。 ”,这会导致搜索引擎识别错误;
√ URL长度要求去掉协议头http(s)://后的URL长度不能超过256字节;
√ 慎用#参数,有效参数不能放在#后面;它们可能会被截断并导致异常的网络爬取。
2.3.2 目录结构设置
网站目录结构是否合理会影响搜索引擎对网站的抓取。这里需要提到的是网站目录结构是扁平的或者树状的。 ,一般搜索引擎都能找到,但有几点需要注意:
√ 建议将不同的内容放在不同的目录或子域中,域名划分详见2.1.2网站域名划分章节;
√ 不要使用孤岛链接,很难被搜索引擎快速发现;如果网站孤岛链接较多,建议使用搜索资源平台的链接提交工具向百度提交数据;
√ 重要内容不建议放在deep目录下。如果内容没有大量的内部链接,搜索引擎很难判断页面的重要性。
这是一个示例图像:
2.4个服务商/自建服务器
选择服务商或自建服务器是网站建设中非常重要和基础的一环;服务器的安全性和稳定性将直接影响百度搜索引擎对网站的整体判断。
2.4.1个域名服务
2.4.1.1 域名服务&域名部署
关于域名服务和域名部署,以*敏*感*词*意事项:
√站长要注意域名部署的方方面面,不要出现域名部署错误;
√ 不建议网站进行一般分析。如果网站爆发*敏*感*词*泛分析,影响不好,会被搜索策略压制;
√ 尽量选择优质的域名服务商。
2.4.2台服务器
做网站还有一个很重要的部分,就是服务器的选择。在服务器的选择上,无论是虚拟主机、云主机还是独立服务器,都需要注意以下四点:
√中文网站不建议选择国外服务器;
√ 服务器的稳定性很重要。需要保持访问顺畅,服务器是否稳定。可以使用百度搜索资源平台(原百度站长平台)爬取异常,爬取诊断工具进行检测和维护。 (服务器经常无法访问或崩溃,这对爬虫来说是致命的);
√ 服务器选择除了自身的稳定性外,还要考虑网站的业务量,比如带宽、内存、CPU能否承受流量,在情况下能否正常访问突然大流量;
√ 服务器主机设置,需要注意是否有禁止爬虫爬取的设置,或者404错误信息设置。这些情况都会造成不必要的搜索引擎爬取异常判断,从而给网站带来不必要的爬取损失。
2.4.2.1 个虚拟主机
一般来说,建议在购买虚拟主机时要特别注意:
√主机公司是否限制搜索引擎的访问;
√ 主办公司资质是否符合要求;
√主机公司技术沉淀是否充足,建议选择品牌较大的主机公司;
√ 主机公司托管的机房物理条件和网络条件是否足够好;
√ 托管公司的技术和客服支持是否足够好;
√ 东道公司是否会出现产能过剩;
√ 宿主公司是否非法访问高风险站点或同一IP下是否存在高风险站点;
√ 国内网站建议购买国内云主机建站。
2.4.2.2 台专用主机
独立托管给网站带来更宽松的使用环境和个性化的软件安装,所以独立托管需要站长具备一定的技术实力才能保证网站的正常运行和安全。
我们对网站管理员购买和托管专用主机的建议是:
√ 关注虚拟主机是否将爬虫IP拉入黑名单。百度UA可以参考3.1.2.1百度蜘蛛章节;
√ 建议使用具有专用IP地址的主机;
√ 建议使用较大机构的主机,在安全配置和稳定性方面相对较好;
√IDC服务商的建设标准需要一定的考虑,比如防火、防盗、是否有UPS保障、室内温控、防火等;
√IDC服务商的服务质量和技术是否达标,是否24小时值班,是否能协助排除部分故障,免费重启重装系统等;
√IDC机房资质是否齐全,存储站点是否有高风险站点或服务器。
2.4.3 安全服务
2.4.3.1 HTTPS
目前,百度已经实施了全站HTTPS安全加密服务。百度HTTPS安全加密已覆盖主流浏览器,旨在为用户打造更私密的互联网空间,加速国内互联网HTTPS化。同时也希望有更多的网站加入HTTPS团队,为网络安全贡献力量。
HTTPS安全原理分析
HTTPS主要由两部分组成:HTTP+SSL/TLS,即在HTTP中增加了一个处理加密信息的模块。服务端和客户端之间的信息传输是经过TLS加密的,所以传输的数据是加密数据。
HTTS复杂的加密机制有效的增加了网站的安全性。加密机制和认证机制可以降低网站被劫持和伪造的风险。建议站长做HTTPS改造,加强网站安全性。
为了更好的抓取和识别HTTPS网站,百度搜索资源平台也在2017年推出了HTTPS认证工具。已经完成HTTPS改造的网站可以在搜索资源平台上找到—— 网站支持-网站在HTTPS认证工具中提交的HTTPS数据,让百度更好的抓取和识别网站。关于HTTPS认证工具的详细说明,请参考5.3.2HTTPS认证工具章节。
2.4.3.2 网站防止被黑
网站被黑,通常表现为在网站中出现大量非本网站发布的类似*敏*感*词*内容,或者网站页面直接跳转到*敏*感*词*页;以下是网站hack后发布的内容:
内容不是网站发布的,内容收录大量*敏*感*词*网站指向:
网站页面直接跳转到投注网站
网站 被黑意味着网站 存在严重的安全问题或漏洞。如何防止网站被黑,请参考以下内容:
首先,检查你是否被黑了
√被黑网站数据中有一个特点,就是索引量和搜索引擎带来的流量在短时间内出现异常。因此,站长可以使用百度搜索资源平台(原百度站长平台)的索引工具,观察网站的索引是否有异常; @关键词是否与网站、*敏*感*词*和*敏*感*词*有关;
√ 通过Site语法查询本站,结合一些常见的*敏*感*词*和*敏*感*词*类关键词可以获得更好的结果,并且有可能找到不属于本站的非法页面;
√ 由于百度流量巨大,部分被黑行为仅重定向到百度带来的流量,站长很难发现。因此,在检查您的网站是否被黑客入侵时,您必须从百度搜索结果中点击该网站页面。 , 看看有没有跳转到其他网站;
√ 网站内容被建议在百度搜索结果中存在风险;
√ 以后可以请网站技术人员通过后台数据和程序进一步确认网站是否被黑。
其次,被黑后怎么办
√ 确认网站被黑后,SEO人员除了推动技术人员快速改正外,还需要做一些善后和预防工作;
√网站如果页面有变化,建议使用链接提交工具向百度提交数据;
√ 立即停止网站服务,防止用户受到影响,其他网站受到影响;
√如果同一托管服务商在同一时期有多个网站被黑,您可以联系托管服务商并敦促对方回应;
√ 清理发现的被黑内容,将被黑页面设置为404死链接,通过百度搜索资源平台(原百度站长平台)的死链接提交工具提交。 (我们发现有些网站使用了将被黑页面重定向到首页的做法,这是非常不可取的。);
√ 查看可能被黑客入侵的时间,与服务器上的文件修改时间进行对比,对黑客上传修改的文件进行处理;检查服务器中的用户管理设置,确认是否有异常变化;更改服务器用户访问密码。注意:可能的黑客攻击时间可以从访问日志中确定。但是,黑客也可能会修改服务器的访问日志;
√ 做好安全工作,检查网站的漏洞,防止再次被黑。
网站自我保护注意事项:
√多种安全防护同时进行:适用于中小信息网站;
● 网站程序经常打补丁:现在很多信息系统网站使用内容管理系统(cms),作为一个新闻发布系统,功能还不错,但是,作为比较常见的内容管理系统(cms),还有一个问题,就是漏洞比较流行,因为源代码是公开的,所以很容易被研究漏洞,就是需要及时更新网站程序的Bug修复。
√ 定期对服务器进行安全保护;
● 下班后,在服务器上设置网站权限,禁止文件修改,后台文件隐藏或迁移到根目录外。
●参考部分网站的安全设置,不合格的IP无法写入数据库。
√不要使用开源程序默认的robots文件;
● 下图是某地级市信息站的robots文件。从robots文件中可以看出,网站使用了织梦后台,因此黑客可以利用各种织梦针对攻击的软件进行操作,织梦的常见漏洞@织梦网站 可以被扫描和定位。
2.4.4 网络服务
2.4.4.1 CDN
从搜索和爬取机制来看:百度蜘蛛爬取网站的方式与普通用户相同。只要普通用户可以访问内容,百度蜘蛛就可以抓取。不管用什么技术,只要用户能顺利访问网站,对搜索引擎没有影响。但也有部分站长反映使用CDN后出现网站爬取异常甚至流量异常等问题,主要有两个原因:
首先,有的CDN服务商没有足够的硬件投入,往往会造成不稳定,导致大量蜘蛛无法爬取,影响网站爬取效果,有的甚至影响索引数据;所以选择一个强大的CDN服务商很重要;
其次,缓存机制对网站死链接、打不开、被黑等起到推波助澜的作用,短时间内出现了一些不利的快照,影响了排名。不要担心这种情况。及时清除源文件和CDN缓存,在百度搜索资源平台(原百度站长平台)提交相关死链接数据即可恢复。
3 网站优化
3.1 抓取友好度
关于爬取的优先级,这里强调一下:
√网站更新频率:频繁更新高价值网站,优先抓取;
√ 人气:用户体验好的网站会被优先抓取;
√ 优质入口:优质站内链接,优先抓取;
√历史的爬取效果越好,越优先被爬取;
√ 稳定服务器,先爬取;
√ 优质安全记录网站,优先抢夺;
平滑稳定的爬取是网站获取搜索用户和搜索流量的重要前提,影响爬取的关键因素,站长可以借鉴本章。
3.1.1 网址规范
网站的URL如何设置,请参考2.3.1
中的URL设置规范
3.1.1.1个参数
URL中的参数放置必须遵循两点:
√ 参数不要太复杂;
√ 不要使用无效参数。参数无效会导致页面识别问题,页面内容不会在搜索中显示。
此外,很多站长使用参数(参数对搜索引擎和页面内容无效)来统计网站访问行为。这里要强调的是,这种形式的资源尽量不要出现,比如:
或者:
;NTESnmtpSI=-8010#/app/others/details?editId=&articleId=578543&articleType=0&from=sight
3.1.2 链接发现
3.1.2.1百度蜘蛛
很多站长会问怎么判断百度手机蜘蛛。下面是一个只需两步就能正确识别百度蜘蛛的方法:
查看用户获取
如果UA错了,可以直接判断不是百度搜索的蜘蛛。已向公众公布的 UA 是:
移动用户端 1:
Mozilla/5.0 (Linux;u;Android 4.2.2;zh-cn;) AppleWebKit/534.46 (KHTML,likeGecko) 版本/ 5.1 Mobile Safari/10600.6.3(兼容;Baiduspider/2.0;+ search/spider.html)
移动 UA 2:
Mozilla/5.0(iPhone;CPU iPhone OS 9_1,如 Mac OS X)AppleWebKit/601.1.46(KHTML,如 Gecko)版本/9. 0 Mobile/13B143Safari/601.1(兼容;Baiduspider-render/2.0;+)
PC UA 1:
Mozilla/5.0(兼容;Baiduspider/2.0;+)
PC UA 2:
Mozilla/5.0(compatible;Baiduspider-render/2.0;+ spider.html)
反向IP检查
站长可以通过DNS反查IP判断蜘蛛是否来自百度搜索引擎。不同平台的验证方式不同。例如Linux/Windows/OS三种平台下的验证方式如下:
Linux平台下,可以使用hostip命令反向IP判断是否是从百度蜘蛛爬取的。百度蜘蛛的主机名以 *.格式,如果不是 *.是冒名顶替。
这里还需要提出一点。建议使用DNS改为8.8.8.8,然后进行反向nslookup解析。否则很可能不会出现退货或退货错误。
在Windows平台下,可以使用nslookup ip命令反向IP判断是否是从百度蜘蛛爬取的。打开命令处理器,输入nslookup xxx.xxx.xxx.xxx(IP地址)解析IP,判断是否是从百度蜘蛛爬取的。百度蜘蛛的主机名以*.的格式命名,如果不是*.是冒名顶替。
Mac OS平台下,网站可以使用dig命令破译IP,判断是否是从百度蜘蛛爬取的。打开命令处理器,输入dig xxx.xxx.xxx.xxx(IP地址)解析IP,判断是否是从百度蜘蛛爬取的。百度蜘蛛的主机名以*.的格式命名,如果不是*.是冒名顶替。
3.1.2.2链接提交
链接提交工具是网站主动向百度搜索推送数据的工具。 网站使用链接提交可以缩短爬虫发现网站链接的时间。目前,链接提交工具支持四种提交方式:
√ 主动推送:最快的提交方式。建议通过此方式立即将站点新的输出链接推送至百度,确保新链接能被百度及时抓取;
√ Sitemap:网站您可以定期将网站链接放到Sitemap中,然后将Sitemap提交给百度。百度会定期对提交的Sitemap进行爬取检查,并对其中的链接进行处理,但爬取速度比主动推送慢;
√手动提交:如果不想通过程序提交,可以通过这种方式手动提交链接到百度;
√ 自动推送:轻量级的链接提交组件。自动推送的 JS 代码放置在网站各个页面的源码中。当页面被访问时,页面链接会自动推送到百度,有利于新页面的更新。很快就会被百度发现。
简单来说:建议有新闻属性的网站使用主动推送进行数据提交;新的验证平台站点,或者对内容没有时效要求的站点,可以使用Sitemap提交网站所有使用Sitemap的内容;技术能力较弱,或者网站网站内容较少,可以使用手动提交提交数据;最后,您还可以使用插件自动将数据推送到百度。
3.1.3 网页抓取
3.1.3.1 访问速度
关于手机页面的访问速度,百度搜索资源平台(原百度站长平台)于2017年10月推出闪电算法,为首页打开速度提供战略支持。闪电算法中指出,移动搜索页面首屏的加载时间会影响搜索排名。如果手机网页首屏加载时间在2秒以内,将优先考虑提升手机搜索下的页面评价,造成流量倾斜。压制。
以下是加快页面访问速度的一些建议:
资源加载:
√ 在服务器端压缩合并同类型资源,减少网络请求次数和资源量;
√ 引用常用资源,充分利用浏览器缓存;
√ 使用 CDN 加速将用户请求引导到最合适的缓存服务器;
√ 首屏图像类加载,为首屏请求留出网络带宽。
页面渲染:
√ 在头部样式表中写入 CSS 样式,减少网络请求 CSS 文件造成的渲染阻塞;
√ 将Java放在文档末尾,或者使用异步加载避免JS执行阻塞渲染;
√ 为非文本元素(如图片、视频)指定宽高,避免浏览器重排和重绘;
希望广大站长继续关注页面加载速度体验,根据网站自身情况,参考建议优化页面,或者使用通用加速方案(如MIP)不断优化页面首屏的加载时间。
要了解MIP-Mobile Web Accelerator,请参考:
3.1.3.2返回码
HTTP 状态代码是一个 3 位代码,用于指示 Web 服务器的 HTTP 响应的状态。在日常维护网站时,站长可能会在站长工具后台抓取异常或服务器日志中看到各种响应状态码,其中一些甚至可能影响网站的SEO效果,比如强调在网页404设置上,百度搜索资源平台(原百度站长平台)中的一些工具,比如死链接提交,需要网站提交死链接后的内容,这里的设置必须是404。
以下是一些常见的 HTTP 状态代码:
301:(永久移动)请求的页面已永久移动到新位置。当服务器返回此响应(作为对 GET 或 HEAD 请求的响应)时,它会自动将请求者重定向到新位置。
302:(临时移动)服务器当前正在响应来自不同位置的网页的请求,但请求者应继续使用原创位置进行未来的请求。此代码类似于响应 GET 和 HEAD 请求的 301 代码,并自动将请求者发送到不同的位置。
这里强调301和302的区别:
301/302的关键区别是:这个资源是否存在/有效;
301表示资源还在,但是位置改变了,返回新位置的内容;
302表示资源暂时失效,返回一个临时替换页面(如镜像资源、首页、404页面)。请注意,在永久失败的情况下应使用 404。
有时站长认为百度对302不友好,这可能是对302处理仍然有效的资源的滥用;
400:(Bad Request)服务器不理解请求的语法;
403:(禁止)服务器理解请求,但拒绝执行;
404:(未找到)服务器找不到请求的页面;
One point I have to mention here, many webmasters want to customize 404 pages, they need to ensure that the returned status code is 404 when the spider accesses, if the 200 status code is returned due to improper settings when the 404 page jumps It is considered by search engines that a large number of duplicate pages appear on 网站, thus affecting the evaluation of 网站;
500: (Server Internal Error) The server encountered an error and could not complete the request;
502: (Bad Gateway) The server, acting as a gateway or proxy, received an invalid response from an upstream server;
503: (Service Unavailable) The server is currently unavailable (due to overloading or downtime for maintenance). Usually, this is only a temporary state;
504: (Gateway Timeout) The server, acting as a gateway or proxy, did not receive a request from the upstream server in a timely manner.
3.1.3.3 robots
For detailed tool usage instructions of robots, please refer to the 4.3.4robots tool chapter for details. Regarding the use of robots, only the following two points are emphasized:
√ Baidu Spider currently does not support Chinese in robots, so 网站robots file writing is not recommended to use Chinese characters;
√ robots file supports UrlEncode encoding, such as: %E7%89%B9%E6%AE%8A:%E6%B5%8F%E8%A7%88/%E7%94%9F%E6% AD%BB%E7%8B%99%E5%87%BB:%E7%99%BD%E9%93%B6%E5%8A%A0%E7%89%B9%E6%9E%97
3.1.3.4 dead link
When the 网站 dead link data accumulates too much and is displayed on the search result page, it has a negative impact on the 网站 own visit experience and user conversion. On the other hand, Baidu's process of checking dead links will also bring additional burdens to 网站, affecting the crawling and indexing of other normal pages of 网站.
Baidu search resource platform (former Baidu webmaster platform) has launched a dead link submission tool to help 网站 submit dead link data, the use of dead link submission tools refers to 4.3.2 dead links submission tool.
What is dead link and the standard of dead link
A page that is no longer valid and cannot provide any valuable information to users is a dead link. There are three common forms of dead links. Protocol dead links and content dead links are two more common forms. In addition, there are Jump dead link.
√ Protocol dead link: The dead link clearly indicated by the TCP protocol status/HTTP protocol status of the page, such as 404、403、503 status, etc.;
√ Content dead link: The server returns a normal status, but the content has been changed to an information page unrelated to the original content, such as non-existent, deleted, or permission required;
√ Dead link jump: Refers to the behavior of the page content has been invalid, jumping to the error page, home page, etc.
3.1.4 Access Stability
The main points of attention for access stability are as follows:
DNS resolution
DNS is a domain name resolution server. Regarding DNS, it is recommended that Chinese 网站 use the DNS service provided by large domestic service providers as much as possible to ensure the stable resolution of the site.
Share an example of DNS stability:
The search resource platform (the former webmaster platform) has received feedback from multiple webmasters, saying that 网站 disappeared from Baidu web search, and the site found that the data of 网站 was 0.
After investigation, it was found that these 网站 all use the DNS server *.DOMAINCONTROL.COM of a foreign brand. This series of DNS servers has stability problems. Baidu spiders often cannot resolve IP. In Baidu spiders' view,
@网站 is a dead site. There have been many cases of small DNS service providers blocking Baidu spider resolution requests or unstable foreign DNS servers. Therefore, it is recommended to 网站 here, choose DNS service carefully.
Spider Ban
A ban on crawlers will cause crawlers to think that 网站 is not accessible normally, and take corresponding measures. There are actually two types of reptile bans, one is the traditional robots ban, and the other is the IP ban and UA ban that require the cooperation of technical personnel; and in most cases, the ban is caused by improper operation. The response on the search engine is that the crawler cannot access it normally. Therefore, the operation of the crawler ban must be cautious. Even if it is temporarily banned due to access pressure, it must be restored as soon as possible.
Server Load
Aside from server hardware problems (unavoidable), most of the situations that cause excessive server load are caused by software programs. For example, programs have memory leaks, programs have cores, and services are unreasonably mixed (one of the services consumes server resources.) If the load is too large, the server load will increase, which will affect the server's response to the crawler's access request.) For the machine that provides the service, you must pay attention to the server's load, and leave enough buffers to ensure that the server has a certain ability to withstand pressure.
Other human factors
It is common to see abnormal access caused by improper human operation. Strict institutional constraints are required for this situation, and the situation of different sites is different. It is necessary to ensure that every upgrade or operation is accurate.
3.1.5 Total Links Accessible
3.1.5.1 resources can be exhausted
Generally speaking, the content pages of 网站 can be exhausted, at the level of 10,000, 1,000,000 or even 100 million, but they must be exhaustible. In reality, there are indeed some 网站, and the crawler will fall into a "link black hole" when grabbing and pulling the chain for these 网站; ;Typical is some search result pages of 网站. Different queries have different a tag links under different anchors, which leads to the generation of "link black holes", so it is strictly forbidden to generate URLs with user access behavior or search Binding factors such as words.
3.2 Page Analysis
Page parsing, mainly refers to the 网站 page being crawled by spiders, which will analyze and identify the page, which is called page parsing. Page parsing is very important to 网站. The crawling of 网站 content is the first step for 网站 to be discovered, while page parsing is the identification of 网站 content. An important part, the effect of page analysis directly affects the evaluation of 网站 by search engines.
3.2.1 page element
3.2.1.1 page title
Regarding webpage titles, Baidu search launched the Qingfeng algorithm in September 2017, focusing on combating 网站 title cheating, guiding users to click, and damaging the user experience; the title cheating that the Qingfeng algorithm focuses on cracking down are the following two :
√ The text is incorrect, 网站The title is obviously inconsistent with the text, misleading search users to click, and causing harm to search users;
√ A lot of stacking, 网站A lot of stacking关键词 in the title is also very discouraged,
For a detailed interpretation of 网站 title cheating, refer to the official document "Baidu Search Content Quality White Paper - Detailed Explanation of Web Title Cheating" released by the Search Academy.
About 网站TDK, the following situations need to be paid attention to: ("T" represents the title element in the header, "D" represents the deion element in the header, and "K" represents the element in the header The keywords element, which simply refers to the title, description and abstract of 网站);
√ Baidu has not promised to display the title and abstract strictly according to the content of title and deion, especially the abstract. According to the 关键词 retrieved by the user, it will automatically match and display the appropriate abstract content, so that the user can understand the main content of the webpage.影响用户的行为决策;
√ 站长会发现同一条链接的摘要在不同关键词下是变化的,可能不会完全符合站长预期,尤其是站长在检索框进行site语法操作时,可能会感觉摘要都比较差。但请不要担心,毕竟绝大多数普通网民不会这样操作。在此情况下出现不符合预期的摘要并不代表站点被惩罚;
√ 还有一种情况,是网页中的HTML代码有误,导致百度无法解析出摘要,所以有时大家会看到某些结果的摘要是乱码(当然这种情况很少见),所以也请站长注意代码规范。
3.2.1.2 主体内容
主体内容注意两个点,一个主体内容过长(通常网页源码长度不能超过128k),文章过长可能会引起抓取截断;另外一个是注意内容不能空短,空短内容也会被判断为无价值内容。
以下分析两个示例:
关于主体内容过长的示例分析:
某网站主体内容都是JS生成,针对用户访问,没有做优化;但是网站特针对爬虫抓取做了优化,直接将图片进行编码推送给百度,然而优化后发现内容没有被百度展示出来;
页面质量很好,还特意针对爬虫做了优化,为什么内容反而无法出现在百度搜索中;
分析主要有以下原因:
√ 网站针对爬虫爬取做的优化,是直接将图片编码后放到HTML中,导致页面长度过长,网站页面长度达164k;
√ 站点优化后将主体内容放于最后,图片却放于前面;
√ 爬虫抓取内容后,页面内容过长被截断,已抓取部分无法识别到主体内容,最终导致页面被认定为空短而不建索引。
这样的情况给到以下建议:
√ 如站点针对爬虫爬取做优化,建议网站源码长度在128k之内,不要过长;
√ 针对爬虫爬取做优化,请将主体内容放于前方,避免抓取截断造成的内容抓取不全。
关于内容空短的示例分析:
某网站反馈网站内容未被建索引,分析发现,网站抓取没有问题,但被抓取到的页面,都提示需要输入验证码才能查看全部页面,这类页面被判断为空短页面,这类页面在抓取后,会被判定为垃圾内容。
而且当蜘蛛对一个网站抓取后发现大面积都是低值的空短页面时,爬虫会认为这个站点的整体价值比较低,那么在后面的抓取流量分布上会降低,导致针对该站点的页面更新会比较慢,进而抓取甚至建索引库也会比较慢。
为什么会出现网站内容空短这种情况,其中一个原因是网站内容未全部搭建完成,未对外开放,但已被蜘蛛爬取发现。针对这种情况,建议网站在邀请测试阶段使用robots封禁。
另外还会有些网站,设置用户查看权限,如需用户登陆才能查看全部内容,这样的行为对搜索引擎也极不友好,蜘蛛无法模拟用户登陆,仅能抓取网站已展示页面,可能会导致抓取页面为空短的现象。
这里再次强调,不要让爬虫给站点画上不优质的标签,对网站将产生很不好的影响。另外,移动端的H5页面,很多都是采用JS方式加载,其实是更容易产生空短,请各位站长注意。
3.2.1.3 网页发布时间
关于网页发布时间,有以下几点建议:
√ 网页内容尽可能加上产出时间,严格说是内容发布时间;且时间尽量全,时间格式为年-月-日 时:分:秒;
例:2017-08-12 10:23:06
√ 网页上切忌乱加时间,这样容易造成页面时间提取问题,或搜索引擎判断提取时间不可信,从而降低对网页的展现。
3.2.1.4 canonical标签
canonical标签的目的
在PC互联网时代,canonical标签的作用主要是用来解决由于网址形式不同内容相同而造成的内容重复问题。而在移动时代,canonical标签被百度搜索赋予了更多的意义,在原来的作用基础上,又起到了相同内容的移动页和PC页之间的关联作用;让移动资源更容易继承PC资源的各种特征,从而快速生效移动网页数据。
canonical标签如何设置
在HTML代码的head里添加rel="canonical",不能添加多个,否则搜索引擎会认为是无效的canonical标签。另外需要注意href里的地址不能是死链,错误页或者被robots封禁的页面。
具体示例如下:
3.2.2 落地页体验
为提升移动搜索整体用户体验,提升搜索满意度,百度搜索在2017年推出《百度移动搜索落地页体验白皮书——广告篇2.0》(以下简称广告白皮书)。广告白皮书对网站移动落地页页面广告内容、广告位置、大小等做了明确要求,从而充分保证搜索用户的浏览体验。
白皮书详情,请参考搜索学院官方文档《百度移动搜索落地页体验白皮书——广告篇2.0》
3.3 页面价值
3.3.1 内容价值
原创文章,要求是独立完成的创作,且没有歪曲、篡改他人创作或者抄袭、剽窃他人创作而产生的作品,对于改编、注释、整理他人已有创作而产生的作品要求有充分的点评、补充等增益信息。
建议原创文章在标题下方明确注明“来源:xxxx(本站站点名)”或“本站原创”之类字样,转载文章明确注明“来源:xxxx(转载来源站点名)”之类字样,不建议使用“admin”、“webmaster”、“佚名”等模糊的说法。
3.3.2 外链建设
通常认为,外链是本站点对第三方站点页面的链接指向,是本站点对第三方站点页面内容的一种认可和推荐。
站点进行外链建设时,建议是有真实推荐意图,并且指向那些熟悉的、被认可的、内容相关的外部页面;不建议推荐与本站点页面内容无关的外链内容。也不建议乱推荐外链、交换外链互联、指向作弊站的行为(这些很可能被超链策略反向识别成垃圾作弊站点进行打压)。
最后,站长要及时发现和处理站点被黑的页面。页面被黑掉后,一般会被人为放入大量无关的,甚至作弊的外链在该页面上,其目的是要瓜分站点自身权重,并以此来提高外链目标站点影响力。建议站长发现后,及时向搜索资源平台(原站长平台)提交死链进行删除和屏蔽,不及时处理一定程度上会影响站点本身的权重。最好从技术上优化,提高站点安全壁垒,防范于未然。
3.3.3 内链建设
内链,描述了站点的结构,一般起到页面内容组织和站内引导的作用;内链的重要意思是通过链接指向,告诉搜索引擎哪个页面最为重要。
内链组织的时候,建议结构清晰,不要过于冗杂,另外内链组织的版式建议保持一致,这样对搜索引擎超链分析比较友好。
与外链类似,建议站长善于使用nofollow标签,既对搜索引擎友好,又可避免因垃圾link影响到站点本身的权重。
3.3.4 anchor
anchor描述:尽可能使用典型的,有真实意义的anchor。 anchor描述要与超链接的页面内容大致相符,避免高频无意义anchor的使用,另外同一个URL的anchor描述种类不宜过多,anchor分布越稀疏会影响搜索排名。
4 百度专属SEO工具
4.1 百度搜索资源平台(原百度站长平台)介绍
百度搜索资源平台(原百度站长平台)是全球最大的面向中文互联网管理者、移动开发者、创业者的搜索流量管理的官方平台。提供有助于搜索引擎数据查询及优化的工具、SEO建议、多端适配服务的能力等。
百度搜索资源平台域名地址:
4.2 查询工具
4.2.1 索引量工具
网站的索引量指该网站在百度搜索上,可以被用户搜索到的链接总量。百度蜘蛛通过抓取发现网站内容,进行页面解析,对有价值内容建立索引库,最终使搜索用户可以搜索到网站内容。
网站被百度蜘蛛抓取后,经过一系列计算才得以建入索引库,有了和搜索用户见面的机会。所以,索引量一直是站长们关注的焦点,但关于索引量工具有一些误读,这里给到正确解答:
√ 索引量不等于网站流量:索引库分多个层级,进入上层索引库才有更多与搜索用户见面的机会;进入下层库机会渺茫。所以,索引量总体的增加减少并不能说明流量会有什么变化;
√ 索引量变化不直接影响流量变化:当流量发生巨大变化时,索引量数据可以作为排查原因的渠道之一,但不是唯一排查渠道,索引量变化并不直接影响流量变化;
√ 索引量浮动情况,索引量上下浮动10%(经验值),甚至更多,都可能属于正常。只要流量变化不大就不用紧张。
4.2.2 流量与关键词工具
流量与关键词工具提供站点的热门关键词在百度搜索结果中的展现及点击量数据,通过对关键词表现情况的监控,帮助网站更好进行优化,流量与关键词工具可全面帮助站长了解网站在百度搜索引擎中的表现,决定页面及网站的优化方向,为网站运营决策提供分析依据。
关于流量与关键词工具,还有一点需要强调,如果站长需要在反馈中心中提交关于网站流量异常的情况,请使用此工具的数据、及数据截图作为证据,便于工作人员分析网站问题。
4.2.3 抓取频次工具
什么是抓取频次
抓取频次是搜索引擎在单位时间内(天级)对网站服务器抓取的总次数,如果搜索引擎对站点的抓取频次过高,很有可能造成服务器不稳定,百度蜘蛛会根据网站内容更新频率和服务器压力等因素自动调整抓取频次。
什么情况下可以进行抓取频次上限调整:
首先,百度蜘蛛会根据网站服务器压力自动进行抓取频次调整;
其次,如果百度蜘蛛的抓取影响了网站稳定性,站长可以通过此工具调节百度蜘蛛每天抓取网站的频次上限。
强调1:调整抓取频次上限不等于调高抓取频次;
强调2:建议站长慎重调节抓取频次上限值,如果抓取频次过小则会影响百度蜘蛛对网站的及时抓取,从而影响索引。
4.2.4 抓取诊断工具
什么是抓取诊断
抓取诊断工具,可以让站长从百度蜘蛛的视角查看抓取内容,自助诊断百度蜘蛛看到的内容,和预期是否一致。每个站点每周可使用200次,抓取结果只展现百度蜘蛛可见的前200KB内容。
抓取诊断工具能做什么
目前抓取诊断工具有如下作用:
√ 诊断抓取内容是否符合预期,譬如很多商品详情页面,价格信息是通过Java输出的,对百度蜘蛛不友好,价格信息较难在搜索中应用。问题修正后,可用诊断工具再次抓取检验;
√ 诊断网页是否被加了黒链、隐藏文本。 网站如果被黑,可能被加上隐藏的链接,这些链可能只在百度抓取时才出现,需要用此抓取工具诊断。
4.2.5 抓取异常工具
什么是抓取异常
百度蜘蛛无法正常抓取,就是抓取异常。通常网站出现抓取异常,都是网站自身原因造成,需要网站根据工具提示,尽快自查网站问题并解决。
抓取异常对网站有哪些影响
对于大量内容无法正常抓取的网站,搜索引擎会认为网站存在用户体验上的缺陷,并降低对网站的评价,在抓取、索引、搜索评价上都会受到一定程度的负面影响,最终影响到网站从百度获取的流量。
抓取异常的原因有哪些
● 网站异常
√ DNS异常:当百度蜘蛛无法解析网站的IP时,会出现DNS异常。可能是网站IP地址错误,或者域名服务商把百度蜘蛛封禁。请使用whois或者host查询自己网站IP地址是否正确且可解析,如果不正确或无法解析,请与域名注册商联系,更新网站IP地址;
√ 连接超时:抓取请求连接超时,可能原因服务器过载,网络不稳定;
√ 抓取超时:抓取请求连接建立后,下载页面速度过慢,导致超时,可能原因服务器过载,带宽不足;
√ 连接错误:无法连接或者连接建立后对方服务器拒绝。
● 链接异常
√ 访问被拒绝:爬虫发起抓取,httpcode返回码是403;
√ 找不到页面:爬虫发起抓取,httpcode返回码是404;
√ 服务器错误:爬虫发起抓取,httpcode返回码是5XX;
√ 其他错误:爬虫发起抓取,httpcode返回码是4XX,不包括403和404。
4.3 提交工具
4.3.1 链接提交工具
目前一共有4种提交方式,分别是主动推送、Sitemap、手工提交和自动推送,这四种推送方式的区别,请看下图:
建议有新闻属性站点,使用主动推送进行数据提交;新验证平台站点,或内容无时效性要求站点,可以使用Sitemap将网站全部内容使用Sitemap提交;技术能力弱,或网站内容较少的站点,可使用手工提交方式进行数据提交;最后,还可以使用插件方式,自动推送方式给百度提交数据。
使用链接提交工具,还需要注意的是,部分网站会采用第三方插件推送数据,插件推送方式需要站长仔细检查推送逻辑,之前发生过站长使用第三方插件推送数据,而第三方插件采用域名+标题进行推送,这样导致推送给百度的URL中存在中文字符,带有中文字符的URL会301跳转到真实的URL上,出现此类情况,是无法享受快速抓取优待的。
链接提交工具可以快速帮助站点实现内容抓取,使用第三方插件可以快速帮助站长解决推送的问题,站长只需在选择插件时,仔细检查下插件数据逻辑,否则推送错误数据,网站数据无法享受快速抓取优待。
4.3.2 死链提交工具
为什么要使用死链工具
当网站死链数据累积过多时,并且被展示到搜索结果页中,对网站本身的访问体验和用户转化都起到了负面影响。另一方面,百度检查死链的流程也会为网站带来额外负担,影响网站其他正常页面的抓取和索引。
注意事项:
√ 请推送协议死链数据,死链工具仅支持协议死链数据;
√ 提交死链被删除后,网站可以删除已提交的死链文件,否则搜索仍会继续抓取死链文件,确认文件中内容。
什么是死链规则提交?
死链规则是链接前缀,且匹配前缀的链接全部是死链。
目前支持两种死链规则:
√ 目录规则:以“/”结尾的前缀;
√ CGI规则:以“?”结尾的前缀。
什么是死链文件提交?
√ 站长需要提交已被百度建索引的、且需要删除的链接,如链接在百度搜索不到,则可以不提交死链;
√ 需要删除的链接需要全部设置为404,如发现有链接非死链,会导致文件校验失败,从而无法删除死链;
√ 如死链文件抓取失败,可以通过抓取诊断工具判断死链文件是否可以正常抓取;
√ 站长提交死链后,请不要在robots中封禁百度蜘蛛,封禁百度蜘蛛会影响链接的正常删除;
√ 如果需要删除的链接已经被删除,请及时的删除掉死链文件;
√ 提交死链工具,最长需要2-3天生效死链。如站长发现链接未被删除,一周后可以重新提交。
规则提交:
√ 规则死链不支持通配符;
√ 规则死链必须是以?或者 /结尾的规则。
关于死链提交的常见问题
√ 网站死链数据,除了使用死链提交工具,还可以使用robots屏蔽百度抓取,百度将根据robots文件中的规则,不再抓取该内容,如果该内容线上已经展现,将会进行屏蔽;
√ 已经提交死链的文件,蜘蛛仍会继续抓取,检查文件中是否有更新的链接;如抓到更新的链接,将再次校验网站;如死链提交已生效,且此文件后续将不再更新,可以直接在工具中将文件删除;
√ 搜索资源平台中的链接分析工具,有死链分析功能,可以帮助网站发现站内死链。
4.3.3 移动适配工具
什么是移动适配,移动适配工具的作用
移动适配工具主要用于,如果网站同时拥有PC站和移动站,且二者能够在内容上对应,即主体内容完全相同,网站可以通过移动适配工具进行对应关系,便于百度来识别PC和移动站之间的关系。
站长通过移动适配工具提交pattern级别或者URL级别的PC页与手机页对应关系,若可以成功通过校验,将有助于百度移动搜索将移动用户直接送入对应的手机页结果。积极参与“移动适配”,将有助于的手机站在百度移动搜索获得更多流量,同时以更佳的浏览效果赢取用户口碑。
移动适配工具如何使用
当网站同时拥有移动站点和PC站点、且移动页面和PC页面的主体内容完全相同,就可以在通过百度搜索资源平台(原百度站长平台)提交正确的适配关系,获取更多移动流量。
第一步:注册并登录百度搜索资源平台(原百度站长平台);
第二步:提交PC网站并验证站点与ID的归属关系,具体验证网站归属方法可见帮助文档;
第三步:站点验证后,进入“网站支持”――“数据引入”――“移动适配工具”,选择具体需要进行移动适配的PC站,然后“添加适配关系”;
第四步:根据自己提交的适配数据特点,选择适合网站的提交方式。目前移动适配工具支持规则适配提交URL适配提交,无论使用哪种方式都需要先指定PC与移动站点,此举可以令平台更加快速地检验提交的数据、给出反馈,顺利生效。同时在之后步骤中提交的适配数据中必须收录指定的站点,否则会导致校验失败;
1)规则适配:当PC地址和移动地址存在规则(pattern)的匹配关系时(如PC页面,移动页面/picture/12345.html),可以使用规则适配,添加PC和移动的正则表达式,正则的书写方式详见工具页面《正则格式说明》。强烈建议使用规则适配,一次提交成功生效后,对于新增同规则的URL可持续生效,不必再进行多次提交。同时该方式处理周期相对URL适配更短,且易于维护和问题排查,是百度推荐使用的提交方式。
2)URL适配:当规则适配不能满足适配关系的表达时,可以通过“URL对文件上传”功能,将主体内容相同的PC链接和移动链接提交给百度:文件格式为每行前后两个URL,分别是PC链接和移动链接,中间用空格分隔,一个文件最多可以提交5万对URL,可以提交多个文件。另外网站还可以选择“URL对批量提交”,在输入框中直接输入URL对,格式与文件相同,但此处一次性仅限提交2000对URL。
第五步:提交适配数据后,关注移动适配工具会提供状态说明,若未适配成功,可根据说明文字和示例进行相应的调整后更新提交适配数据。
4.3.4、robots
什么是robots文件
robots是站点与蜘蛛沟通的重要渠道,站点通过robots文件声明该网站中不想被搜索引擎抓取的部分或者指定搜索引擎只抓取特定的部分。
请注意,仅当网站收录不希望被搜索引擎抓取的内容时,才需要使用robots.txt文件。如果希望搜索引擎抓取网站上所有内容,请勿建立robots.txt文件。之前发现很多流量下降的网站示例,最后追查都是因为技术人员通过robots对搜索引擎加了封禁。
为了避免站长在设置robots文件时出现错误,百度搜索资源平台(原百度站长平台)特别推出了robots工具,帮助站长正确设置robots。
robots.txt文件的格式
robots文件往往放置于根目录下,收录一条或更多的记录,这些记录通过空行分开(以CR,CR/NL, or NL作为结束符),每一条记录的格式如下所示:
":"
在该文件中可以使用#进行注解,具体使用方法和UNIX中的惯例一样。该文件中的记录通常以一行或多行User-agent开始,后面加上若干Disallow和Allow行,详细情况如下:
User-agent:该项的值用于描述搜索引擎robot的名字。在"robots.txt"文件中,如果有多条User-agent记录说明有多个robot会受到"robots.txt"的限制,对该文件来说,至少要有一条User-agent记录。如果该项的值设为*,则对任何robot均有效,在"robots.txt"文件中,"User-agent:*"这样的记录只能有一条。如果在"robots.txt"文件中,加入"User-agent:SomeBot"和若干Disallow、Allow行,那么名为"SomeBot"只受到"User-agent:SomeBot"后面的 Disallow和Allow行的限制。
Disallow:该项的值用于描述不希望被访问的一组URL,这个值可以是一条完整的路径,也可以是路径的非空前缀,以Disallow项的值开头的URL不会被 robot访问。例如"Disallow:/help"禁止robot访问/help.html、/helpabc.html、/help/index.html,而"Disallow:/help/"则允许robot访问/help.html、/helpabc.html,不能访问/help/index.html。 "Disallow:"说明允许robot访问该网站的所有URL,在"/robots.txt"文件中,至少要有一条Disallow记录。如果"/robots.txt"不存在或者为空文件,则对于所有的搜索引擎robot,该网站都是开放的。
Allow:该项的值用于描述希望被访问的一组URL,与Disallow项相似,这个值可以是一条完整的路径,也可以是路径的前缀,以Allow项的值开头的URL 是允许robot访问的。例如"Allow:/hibaidu"允许robot访问/hibaidu.htm、/hibaiducom.html、/hibaidu/com.html。一个网站的所有URL默认是Allow的,所以Allow通常与Disallow搭配使用,实现允许访问一部分网页同时禁止访问其它所有URL的功能。
使用"*"and"$":百度蜘蛛支持使用通配符"*"和"$"来模糊匹配URL。
"*" 匹配0或多个任意字符。
"$" 匹配行结束符。
最后需要说明的是:百度会严格遵守robots的相关协议,请注意区分网站不想被抓取或抓取的目录的大小写,百度会对robots中所写的文件和网站不想被抓取和抓取的目录做精确匹配,否则robots协议无法生效。
4.4 搜索展现工具
站点logo百度搜索资源平台推出的免费类工具,可以给到网站品牌曝光、展示。站点logo是百度搜索根据网站评价、用户需求度、用户浏览轨迹等系统分析产出的效果,因此这个工具并不是所有站点都享有权限。
4.4.1 站点logo
站点申请百度搜索下的logo展示,可以通过搜索资源平台——站点属性——站点logo中进行提交,此工具为免费展示类工具。
下图为站点logo的截图示例:
4.5 维护类工具
4.5.1 网站改版工具
当一个站点的域名或者目录发生变化时,如果想让百度快速收录变化之后的新链接、用以替换之前的旧链接,需要使用百度搜索资源平台的网站改版工具来提交网站的改版关系,加速百度对已收录链接的新旧替换。 网站换域名对网站的影响,可以参考5.1章节网站换域名。
使用改版工具提交改版规则的前提:
√ 站点的URL发生了变化,不论是域名还是站点的目录,或者结果页URL发生变化,改版工具都提供支持,这里单独说一点,页面内容发生变化的不在改版工具处理的范围内;
√ 如果站点URL的路径和参数部分都没有变化,仅仅是域名改变的,只需要知道每个改版前域名和改版后域名的对应关系,不要有整理遗漏,目前平台不支持主域级别的改版规则提交,需要每个域名都单独提交生效;
√ 如果站点URL的路径和参数部分发生变化,但是路径和参数都是有规律可寻的,可以通过规则表达式来整理改版前和改版后的URL对应关系;
√ 如果站点的URL改变没有任何规律的情况,需要准确整理出改版前URL和改版后URL的对应关系。
站长要准确的找到对应关系,这与改版规则的生效息息相关。有了准确的对应关系后,就可以设置301跳转了。
4.5.2 闭站保护工具
由网站自身原因(改版、暂停服务等)、客观原因(服务器故障、政策影响等)造成的网站较长一段时间都无法正常访问,百度搜索引擎会认为该站属于关闭状态。站长可以通过闭站保护工具进行提交申请,申请通过后,百度搜索引擎会暂时保留索引、暂停抓取站点、暂停其在搜索结果中的展现。待网站恢复正常后,站长可通过闭站保护工具申请恢复,申请审核通过后,百度搜索引擎会恢复对站点的抓取和展现,站点的评价得分不会受到影响。
闭站保护工具的重要tip如下:
√ 申请闭站需要保证全站链接都是死链或直接关闭服务器,申请恢复是需要保证网站服务器已经启动并没有死链。为了尽快进行闭站保护/解除闭站保护,保障自身权益,请确保以上条件没问题之后再提交申请(校验很严格,抽样的内容基本需要是100%);
√ 闭站保护申请、死链提交等工具,提到的设置死链,都必须是协议死链,即返回码是404,否则会导致无法通过校验。
● 内容死链,比如单纯的在网页上写上404,或一张图片上画着404,是不行的。
● 判断自己网页返回码是否是404,浏览器里可以直接打开控制台,查看network的doc,刷新页面。
● 或者可以控制台使用命令:curl -i 网页地址 。
● 查返回的信息。
闭站保护只能保证网站的索引量,不能保证网站的排名。之前有站点反馈闭站保护不好用,因为闭站恢复后网站排名没有了,这里再次强调一下,使用闭站工具只能保留网站的索引量,但不保证网站的排名不变。
关于闭站保护常见的问题:
√ 闭站保护的通过时间是从提交申请到生效一天内;
√ 闭站保护申请恢复,是站点没有任何404页面等情况下,2天内恢复;
√ 闭站保护生效之后,首页不会屏蔽,如有网站首页屏蔽需求,可以在搜索资源平台反馈中心提交;
√ 闭站保护最长保护时间是180天,过了180天之后的自动放出,如站点有404页面
√ 仍会正常屏蔽处理;
√ 主站申请了闭站保护后,对应移动站也是需要申请闭站保护的;即使存在适配关系,也只能屏蔽在适配关系中的移动链接,其余不在适配关系中的链接,比如直接被抓取的链接,仍无法屏蔽。
4.5.3 HTTPS认证工具
使用HTTPS认证工具的收益:
网站通过HTTPS认证后,站点在百度搜索的所有快照都会变成HTTPS格式,蜘蛛也会优先抓取HTTPS的链接,让用户在搜索中获得更安全的链接。
网站使用HTTPS认证工具的注意事项:
√ 保证HTTPS站点正常访问,且页面内引入资源为HTTPS格式,包括引入的视频、图片、CSS、JS等元素;如果网站没有全站HTTPS,申请百度搜索资源平台(原站长平台)HTTPS认知是不会通过的,但是如果系统没有检测到这个情况而通过验证的话,会导致没改造的这部分页面产生死链,所以认证前一定要检测好;
√ 如果站点存在HTTP和HTTPS两种协议的页面,必须将HTTP的URL 301到HTTPS的URL上,仅有HTTPS站点的可以直接认证;
√ 必须保证HTTP站点与HTTPS的链接一一对应,没有HTTPS对应的HTTP链接可能会被判断成死链接。
关于

