内容分享:小程序云开发之--微信公众号文章采集篇
优采云 发布时间: 2022-09-26 12:08内容分享:小程序云开发之--微信公众号文章采集篇
小程序云开发--微信公众号文章采集文章
相信很多小伙伴都想过自己做一个小程序,但是苦于没有服务器、没有注册域名、网站ssl证书等。前面有很多微信小程序-end和后端,比如Spring Family Bucket等小程序可以接收到后端返回的值,需要在小程序中添加一个合法的域名(域名备案和https协议)。
这里直接讲授
公众号有专门的界面(还有专门的文档)那么采集小程序的文章怎么给我用呢?
第 1 步:获取 access_token
从文档中可以看出,获取这个access_token需要以下三个参数
grant_type的值为client_credential获取access_token
appid和secret可以在公众号中找到
完成以上配置后,就可以采集文章,
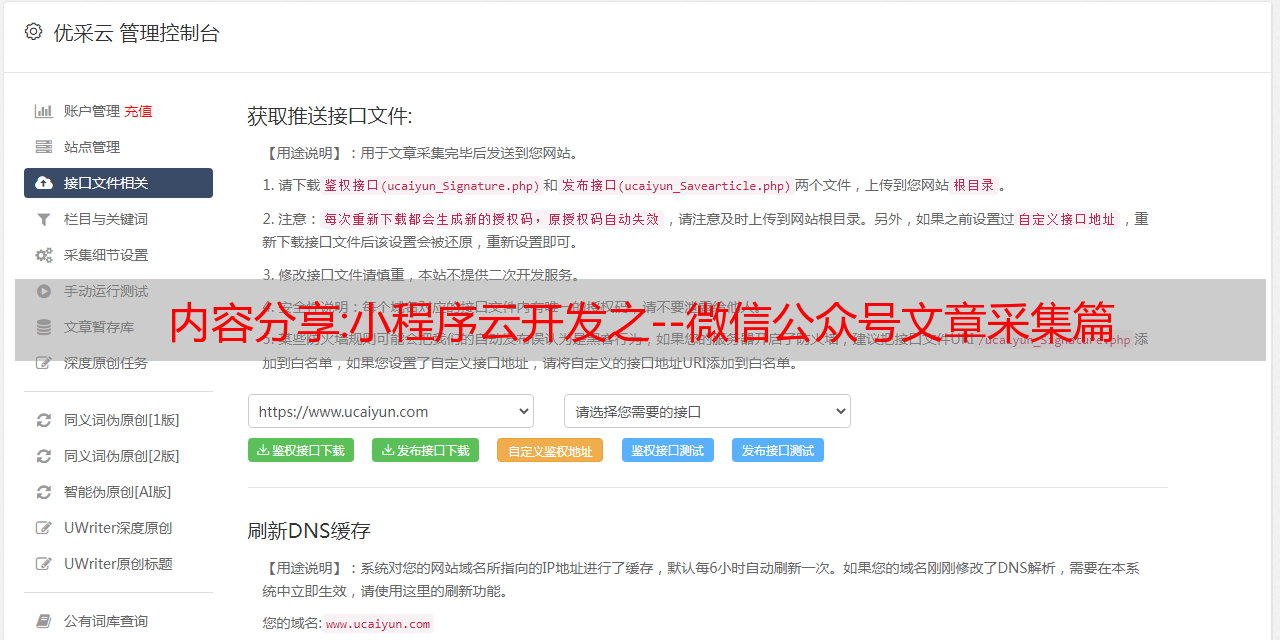
我们可以手动访问获取token或者postman等
拥有token后采集文章下面开始操作很方便
从官方文档可以看出,提供的接口还是蛮多的
让我们使用草稿箱作为演示。 采集图文视频等其他素材的方法同理
我们已经有了第一个token,下一个是offset和count,最后一个参数是可选的
获取文章数据
获取材料后,打印结果
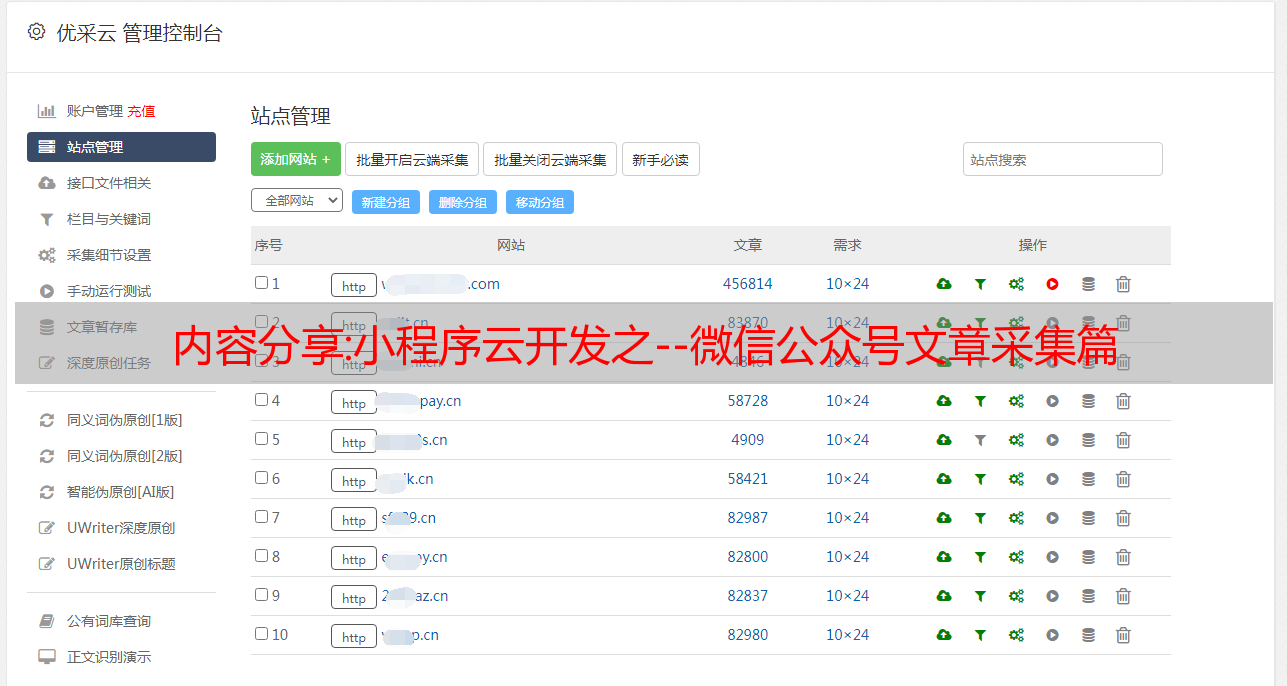
表示我的草稿箱里有3条数据,只有3条数据
文章数据处理
我们需要获取我们需要的参数并将它们添加到数据库中
注意⚠️这里有个问题,如果这个文章已经是采集那么我们就跳过它,如果所有数据都存在那么打印文章已经存在
最后就是把数据库中没有的数据放入数据库中
以下是测试结果
如果所有数据都存在
博客小程序:万神资源栈
网页文章text采集的方法,以微信文章采集为例,当我们想结合老头条上的老新闻和注释内容时搜狗微信文章留着怎么办?一张一张复制粘贴?选择一个通用的网络数据 采集器 会使任务变得更加复杂。优采云是一个通用的网络数据采集器,它可以采集在互联网上隐藏数据。用户可以设置从哪个网站爬取数据,爬取哪个数据,爬取什么范围的数据,何时爬取数据,如何存储爬取的数据等。言归正传,本文将以搜狗微信的文章注解采集为例,讲解优采云采集网页文章注解的使用方法. < @文章Notes采集,主要有两种情况:一、采集文章notes中的文字,不包括图片;二、采集文章评论中的文本和图像 URL。比如网站:HYPERLINK"://weixin.sogou/"://weixin.sogou/ 使用函数点:XpathHYPERLINK"://bazhuayu/search?query=XPath"://bazhuayu/search? query= XPath判别条件HYPERLINK"://bazhuayu/tutorialdetail-1/judge.html"://bazhuayu/tutorialdetail-1/judge.html分页列表同志近三年实战表现材料材料投标技术评分表图表与交易pdf眼图打印pdf用图表说话pdf信息采集HYPERLINK": 笔记中的文字,不包括图片;二、采集文章评论中的文本和图像 URL。比如网站:HYPERLINK"://weixin.sogou/"://weixin.sogou/ 使用函数点:XpathHYPERLINK"://bazhuayu/search?query=XPath"://bazhuayu/search? query= XPath判别条件HYPERLINK"://bazhuayu/tutorialdetail-1/judge.html"://bazhuayu/tutorialdetail-1/judge.html分页列表同志近三年实战表现材料材料投标技术评分表图表与交易pdf眼图打印pdf用图表说话pdf信息采集HYPERLINK": 笔记中的文字,不包括图片;二、采集文章评论中的文本和图像 URL。比如网站:HYPERLINK"://weixin.sogou/"://weixin.sogou/ 使用函数点:XpathHYPERLINK"://bazhuayu/search?query=XPath"://bazhuayu/search? query= XPath判别条件HYPERLINK"://bazhuayu/tutorialdetail-1/judge.html"://bazhuayu/tutorialdetail-1/judge.html分页列表同志近三年实战表现材料材料投标技术评分表图表与交易pdf眼图打印pdf用图表说话pdf信息采集HYPERLINK":
网页打开后,默认显示为“Sought-after”文章。下拉页面,找到并点击“加载更多内容”按钮,在操作提示框中选择“更多动作”页面文章注意采集第三步选择“循环点击单个元素”创建一个翻页循环页面文章评论采集第四步由于这个页面涉及到Ajax技术,我们需要设置一些基本的选项。选择“点击元素”步骤,打开“主要选项”,勾选“Ajax加载数据”,设置时间为“2秒”网页文章注意采集第五步注意:AJAX表示延迟loading ,一种异步更新的脚本技术,通过在后台与服务器通信大量数据,它可以更新网页的一部分,而无需重新加载整个网页。详细请看AJAX点击翻页教程:://bazhuayu/tutorialdetail-1/ajaxdjfy_7.html观察网页,我们
发现点击“加载更多内容”5次后,页面加载到底部,一共显示了100篇文章文章。因此,我们将整个“循环页面”步骤设置为执行 5 次。选择“循环翻页”步骤,打开“主要选项”,打开“满足以下条件时参与循环”,设置循环次数等于“5次”,点击“确定”页面文章评论采集Step 6 Step 3:创建列表循环并提取数据 HYPERLINK"://jingyan.baidu/article/javascript:;"移动鼠标选择第一个文章@ > 页面中的链接。系统会自动识别相似链接。在操作提示框中,选择“全选”网页文章注意< @采集Step 7 选择“Cycle Click Each Link”网页文章注意采集Step 8 系统会自动进入文章概览页面。点击需求字段采集【这里先点击文章的标题】,在操作提示框中选择“采集该元素的文本”。文章发布时间,文章来源字段采集方法同网页文章评论采集第9步继续结束采集@ >文章 注释。首先点击第一段文章评论,系统会自动识别页面中的相似元素,选择“全选”页面文章评论采集步骤105],可以看到即所有评论的段落都被选中并变为绿色。
<p>一般来说,我们希望 采集 的评论合并到同一个单元格中。点击“自定义数据字段”按钮,选择“自定义数据合并方式”,勾选“同一字段提取并重复合并成一行,即追加到同一字段,如评论分页合并”,然后点击“OK”页面文章 @>Annotation采集Step 13 “Custom Data Fields”按钮网页文章Annotation采集Step 14 选择“Custom Data Merge Method”网页

