技巧:百度相关搜索关键词采集方法
优采云 发布时间: 2022-09-25 18:07长尾优化关键词是SEO常用的方法。长尾关键词虽然搜索量小且不稳定,但量大且准确,可以带来更高的转化率。
以旅游业为例,它的长尾关键词可以做出区域+旅游景点、区域+旅游策略等。与流行的旅游和旅游策略关键词相比,这些长-term 尾关键词的竞争不是很高,所以网站布局长尾关键词的内容很容易获得流量,和很多行业相关的挖矿long tail关键词 对于如何布局内容非常有用。
可以借助百度下拉框、百度相关搜索、爱情战争、词库网络等工具进行长尾词挖掘。本文介绍如何使用优采云采集器采集优采云相关搜索关键词。
采集网址:
%E6%97%85%E6%B8%B8&tn=monline_4_dg&ie=utf-8
本文仅以采集旅游业关键词(100)为例。在实际操作过程中,可以根据需要将关键词进行百度相关搜索关键词改为采集。
使用功能点:
lText 循环
lXpath
xpath 1 简介
xpath 2 简介
相对 XPATH 教程 - 7.版本 0
第一步:创建百度相关的关键词采集任务
1)进入主界面,选择“自定义模式”,点击“立即使用”
2)复制并粘贴你要采集的网址到网站输入框,点击“保存网址”
第 2 步:创建文本循环输入
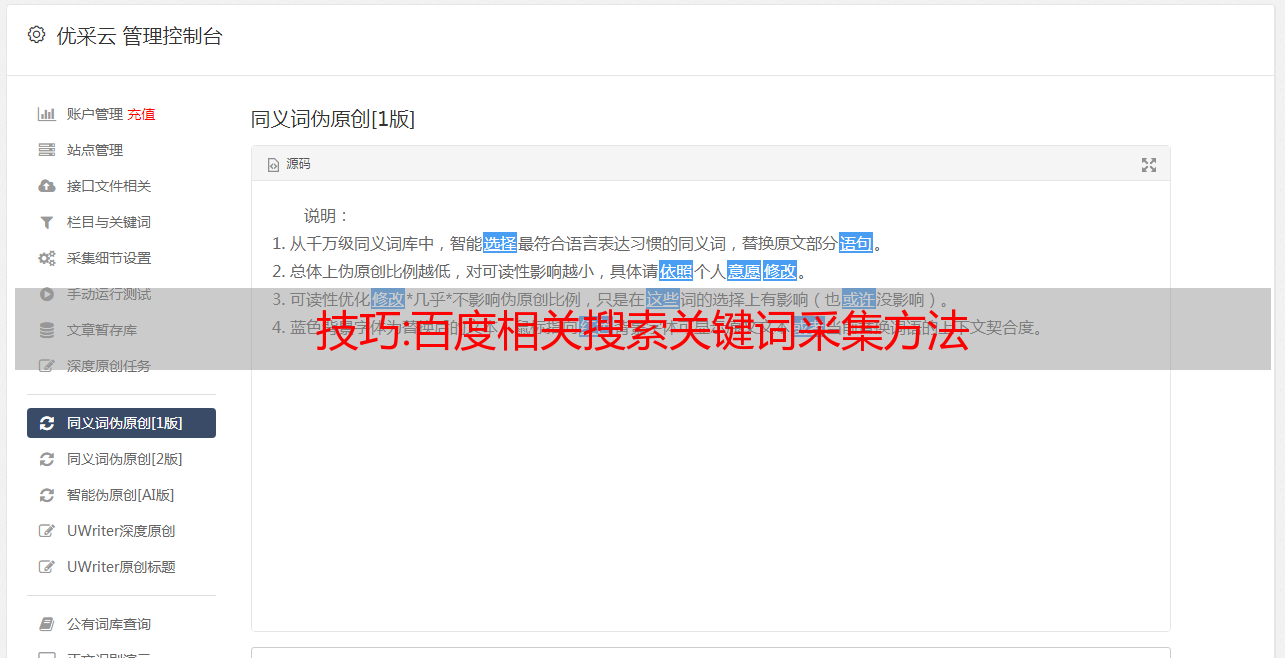
1)系统自动打开网页,进入百度搜索结果页面。由于我们要批量处理采集多个关键词相关的搜索词,我们需要创建一个文本循环输入函数。在首页点击百度搜索框,然后在“操作提示”中选择“输入文字”。
2)输入关键词为采集,然后点击确定按钮。
3)打开右上角的“流程”按钮,将左侧功能栏中的“循环”拖入“流程设计器”中。
4)在高级选项右侧,选择“循环”为“文本列表”,在“文本列表”中将关键词填入采集,点击“好的”。
点击“确定”进入高级选项
5)将“输入文本”拖到“循环”框中。
点击“输入文本”,在右侧“高级选项”中,勾选“使用当前循环中的文本填充输入框”,然后点击“确定”。
6)点击“百度”,在操作提示中选择“点击此按钮”。
7)因为点击“百度点击”按钮加载需要时间,所以我们需要设置一些高级选项。选择“点击元素”这一步,打开“高级选项”,勾选“Ajax加载数据”,时间设置为“3秒”
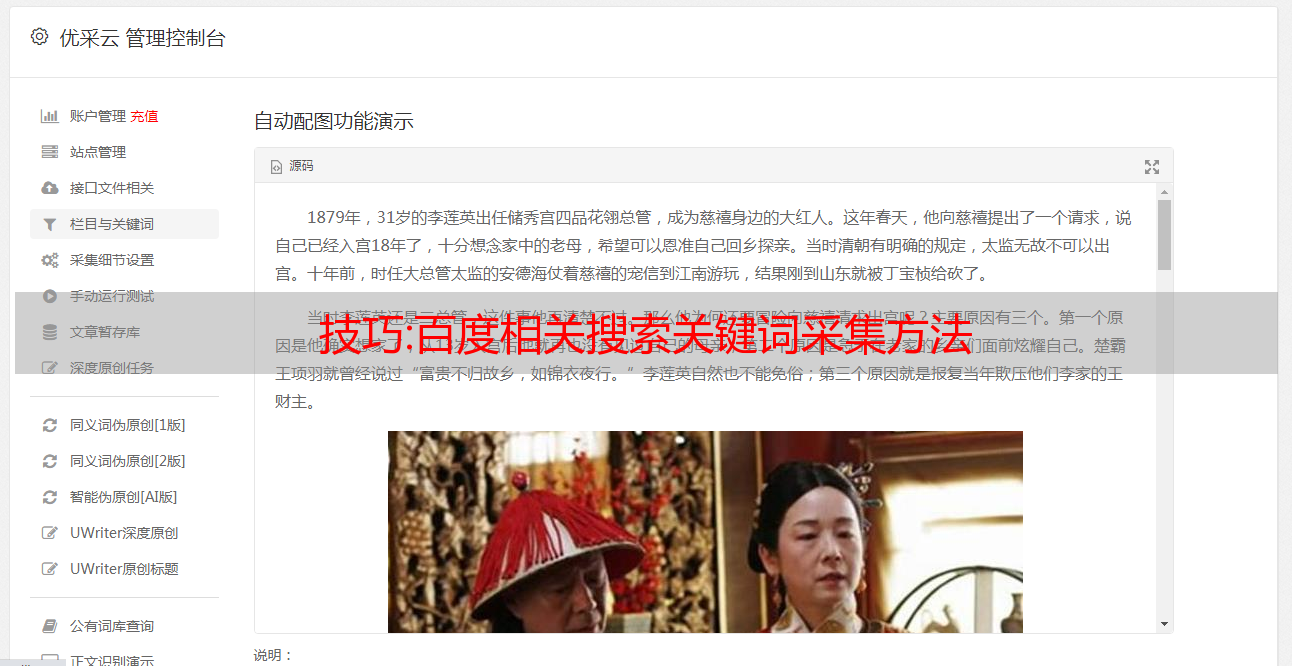
第三步:提取百度相关搜索关键词数据
1)移动鼠标,将页面滚动到相关搜索的位置,然后点击第一个链接,系统会自动识别页面上其他类似元素,可以看到页面只识别3个相关搜索关键词,所以后面需要修改Xpath来修复这个错误,这里我们在“Operation Prompt”中选择“Select All”。
2)选择“采集下面的链接文字”
3)修改“循环选项”的XPATH,在工艺设计中点击“循环”,打开高级选项,在“循环模式”中选择“未固定元素列表”,在“未固定元素列表”中填写XPATH:
//div[@id="rs"]/table//th.
4)修改字段名。
第 4 步:数据采集和导出
1)点击左上角“开始采集”,选择开始“本地采集”
注意:本地采集为采集占用当前计算机资源,如果有采集时间要求或当前计算机长时间不能执行采集 ,可以使用云采集功能,云采集联网采集,无需当前电脑支持,可关机,可设置多个云节点分发任务,10个节点相当于10台电脑分发任务帮你采集,速度降低到原来的十分之一;数据采集可以在云端存储三个月,随时可以导出。
2)采集 完成后会弹出提示,选择“导出数据”。选择“合适的导出方式”,导出采集百度相关搜索关键词的数据,这里我们选择excel作为导出格式
3)数据导出如下图
直观:基于大数据的单文档关键词自动提取系统
吴冠良等:基于大数据的单篇文档自动提取系统关键词71 基于大数据的单篇文档自动提取系统关键词吴冠良;魏晋河;电气工程学院, 长春 130000) 摘要:信息时代信息的快速增长给人们带来了方便和困难。为了快速处理海量信息,本项目设计了一个基于大数据的系统关键词自动提取系统。首先在Linux系统下搭建Hadoop平台,然后在该平台上设计了集分词系统、词频统计和权重计算技术于一体的关键词自动抽取系统。经过实验验证,系统提取的关键词召回率和查准率能够满足实际使用,并且系统的提取时间很短,是可行的。 关键词:Hadoop平台词频统计分词权重基于大数据的单文档关键词自动提取系统吴冠良;魏晋河;党文杰 (吉林大学仪器科学与电气工程学院, 长春 130000) 摘要:信息时代的飞速发展给人们带来了便利,也带来了困难。为了快速处理海量信息,设计了一种基于大数据的关键词自动提取系统。在Linux系统上搭建大数据Hadoop平台。该平台上的关键词自动提取系统设计集成了分词系统、词频统计和权重计算技术。经实验验证,系统提取的关键词满足查准率和查准率的要求,提取时间很短,是可行的。关键词:Hadoop平台词频计数分词权重 导师:王永志项目类型:大学生创新项目(2016B65665) 0 引言随着互联网的发展,各种信息以百万级的速度增长每天数量级。
在海量信息中,人们试图发现并找到他们关心的信息,困难也随之而来。因此,我们必须想出一种有效的方法来帮助我们高效、准确地识别和区分这些海量信息,找到我们真正需要的东西。这也是计算机自然语言处理技术领域面临的巨大挑战。而且,在文档自动聚类、文档检索、文档自动摘要等领域,需要高质量的关键词作为支撑整个系统的起点,所以自动文本提取关键词非常重要随着对自动提取技术研究的逐步深入,一方面全文索引的功能越来越难以满足用户的实际需求[1];另一方面,很多文档信息服务,如自动摘要、文档分类聚合类、文本分析、主题检索等,都对关键词的自动抽取结果有很强的依赖,而关键词可以在文档中表示文档的重要信息和核心内容,方便读者快速了解文档。抽象信息和特定文档的快速检索在新闻阅读、广告推荐、历史文化研究、文本处理、机器翻译、输入法词汇选择等一系列行业和研究中发挥着至关重要的作用。从根本上提高信息服务质量的唯一途径是更好地解决关键词抽取问题。目前自动抽取方法研究的主要趋势是基于语言学的关键词自动抽取和基于统计的自动抽取关键词。基于统计的关键词自动提取是利用统计方法计算单个单词在文档中出现的频率,从而获得关键词。
基于语言学的自动抽取关键词采用自然语言处理技术,如词法分析、句法分析、语义分析、文本分析等方法 [2] 。然而,词法分析需要解决未注册词和词汇维护的问题。句法分析和语义分析的准确率不高,影响单词识别。文本分析对格式有严格的要求,很难达到解决一般问题的目的。因此,依靠语言提取关键词的方法效果不是很好。统计方法的优点是统计发展得比较好。通过分析学术论文中的各种统计指标,可以很容易地得到各种统计指标[3]。根据这些统计指标,可以对吉林大学的仪器科学进行综合分析。电气工程学院论文集2017年上半年72名考生关键词。由于中文没有明显的词界等特点,很难自动提取中文关键词。如果不考虑中文分词过程,可以直接使用英文关键词自动提取方法。在国外对自动提取关键词的研究基础上,国内学者对自动提取关键词进行了深入的研究和开发,提出了许多具有代表性的算法和模型。杜云成等。 (2011)提出了一种基于词共现频率的关键词自动提取算法[4],根据词位置和文本长度改进TF/IDF算法,根据词共现频率计算词信息量,利用特征加权计算词的权重,选取权重较大的词作为关键词。谢晋(2011)提出了一种基于词跨度的中文关键词提取方法[5]。
孙兴东等。 (2014)提出了一种基于聚类的微博关键词获取方法[6]。在此基础上,本文设计了一个基于Hadoop的平台,并采用编程语言(Java Language),单文档关键词自动抽取系统,综合运用文档处理、分词、词频统计、权重计算等技术,提高信息服务质量。 1 大数据平台Hadoop 在大数据时代,所谓大数据,“大”,不仅仅是“很多”的数据!你不能用多少TB或PB的数据。对于大数据,可以用四个字来表达:大数量、品种, 实时性, 不确定性. 即数据量 数据量巨大, 数据种类繁多, 数据变化迅速, 数据真实性存疑. 根据以上特点, 这样的Hadoop诞生了一个平台,它具有以下特点:数据并快速处理大量数据。 ,从大量数据中分析。 Hadoop平台具有高可靠性、高扩展性、高容错性和高效率等诸多优点,并且开源免费,非常适合科学研究,因此本文选择Hadoop平台构建大数据存储系统。其中,HDFS主要用于存储海量数据。它将文件分成若干个大小相同的文件块,然后将这些文件块存储在不同的节点中。 Map/Reduce主要负责海量数据的计算。
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。 HDFS具有高容错性的特点,旨在部署在低成本硬件上;并且它提供了访问应用程序数据的高吞吐量,适用于那些拥有大量数据集的人。设置)应用程序。 HDFS 放宽了 POSIX 的要求,可以流式访问文件系统中的数据(流式访问)。 Hadoop因其在数据提取、转换和加载(ETL)方面的天然优势而被广泛应用于大数据处理应用中。 Hadoop的分布式架构,将大数据处理引擎放在尽可能靠近存储的地方,相对适合ETL等批量操作,因为此类操作的批量结果可以直接进入存储。 Hadoop 的 MapReduce 功能实现了打散单个任务并将碎片化的任务(Map)发送到多个节点,然后以单个数据集的形式加载(Reduce)到数据仓库中[7]。 2 关键词相关技术的自动提取关键词Extraction,也称为关键词Indexing[8],是一种识别有意义和有代表性的词的技术,是指提取出来的一些能涵盖原文主题或概括原文中心思想的重要词语。
本文采用基于词频的自动提取方法关键词,文章分词去除停用词后,统计词频和位置信息,最后根据词频,出现位置和分词距离顺序等影响因素,计算文章中每个词的权重,从权重中提取关键词。 2.1 中文分词技术 中文分词,顾名思义,就是对中文句子进行分词[9],其中计算机是处理工具。比如:在英文句子中,一般都是用空格来分隔单词的,所以我们中文分词就是使用分隔符来分隔中文单词,因为中文句子中除了标点符号外没有其他分隔符,而标点符号只是一个段落,一个字都没有。中文信息处理是自然语言处理的一个方向,而中文分词是中文信息处理的第一步,也是最基本、最关键的环节。中文分词是中文文本处理过程中的一项基础工作。分词结果的好坏直接影响机器对中文句子的理解。目前,中文自动分词的方法有很多。虽然名称不同,分词效果也不同,但根据其基本原理,大致可分为字典分词法、统计分析法、语义语法规则分词法和人工智能法。类[10]。 2.1.1 汉语词法分析系统ICTCLAS 汉语词法分析是汉语信息处理的基础和关键。本文采用中文词法分析系统ICTCLAS对文本进行预处理。为了便于提取词的特征,位置分析和分词顺序与分词同时进行。
ICTCLAS(Institute of Computing Technology, Chinese Lexical Analysis System),由中国科学院计算技术研究所开发,主要功能涵盖中文分词、词性标注、命名实体识别、生词识别,并支持用户词典 [11] ,已升级到 ICTCLAS3.0。 ICTCLAS的优势主要体现在以下四个方面:(1)综合性能最好的ICTCLAS应用了完善的PDAT*敏*感*词*知识库管理技术[53],在高速和高速之间取得了重大突破。精度,可管理百万级词典知识库,单机每秒吴冠良等:基于大数据的单文档关键词自动抽取系统73可查询100万条词条,内存消耗更少比知识库的大小1.5倍。基于该技术,ICTCLAS3.0单机分词速度为996KB/s,分词准确率为98.45% ,API不超过200KB,各种字典数据压缩小于3M,是目前世界上最好的中文词法分析器。(2)统一语言计算理论框架ICTCLAS采用Hierarchical Hidden Markov Model,它统一了所有将汉语词汇分析的各个方面分析成一个完整的理论框架在[53]的理论框架中,取得了最佳的整体效果,相关理论研究发表在国际顶级会议和期刊上,从理论上和实践上都印证了该模型的先进性。
(3)全方位支持各种环境下的应用开发ICTCLAS全部用C/C++编写,支持Linux、Free BSD和Windows系列操作系统,支持主流C/C++/C#/Delphi/ Java等开发语言[12]。(4)可按需更改,所有功能模块可拆装,用户可根据自己的需要定制自己的分词系统。2.1.2 插入用户词典对于文章的特定领域,如医疗领域、电力领域、地质领域等,必须收录该领域使用的一些专有名词。这些专有名词在分词系统中,可能会被分成几个词,比如“可再生能源”分为“可以”、“再生”和“能源”三个部分,与原词所表达的意思相差甚远. 对于这个问题,这篇文章允许插入一个用户字典。用户字典应该尝试收录一些pr相关领域的操作名词。用本词典分词时,专有名词不会被分词。2.1.3 去除停用词 停用词是指那些不反映主题的虚词,如“的”、“那就是说"、"so"等,虽然在文章中出现的频率很高,但是不能反映文献的主题,会干扰关键词的提取,所以是有必要将它们过滤掉[13]。将停用词确定为所有功能词和标点符号,并定义停用词列表基于这些表进行标记过滤是很好理解的。
那么词性过滤的目的是什么?在汉语中,往往是文本中的真实单词能够识别文本的特征。但是,文本中的一些功能词对识别文本的类别特征没有帮助。如果将这些对文本分类无意义的功能词作为文本特征词,会带来很大的误差,从而直接降低文本分类的效率和准确率。比如“非常”、“已经”等,它们在文本中频繁出现,会影响关键词提取的准确性。因此,在提取文本特征词时,首先考虑去除这些对文本分类没有用处的功能词。在文本预处理阶段,可以避免对提取结果的干扰,使提取结果更加准确。 2.2 词频统计在关键词提取过程中,主要通过计算关键词候选关键词的权重来确定。分析词的词频、词的相对词频、反文档频率因子、位置、词性、词本身的值、词长等信息[14],并引入一定的统计方法,如互信息、 TFIDF、最大熵等对词进行加权,最后根据权重对词进行排序,输出权重较大的词,也就是提取出来的关键词。为此,本文采用中科院汉语词法分析系统ICTCLAS和Word Count两种方法进行词频统计。并分析了两种方法的优缺点。 ICTCLAS 上面已经提到过,这里不再赘述。文本预处理后,继续调用本系统的词频统计模块统计每个词在文本中出现的次数(即词频),并在每个词后标注词频。
这种方法的优点是速度快、准确率高,在实际使用中可以节省大量时间,统计结果更准确。缺点是词频统计结果直接用在系统本身的关键词提取模块中,无法提取,给下一步带来困难。 Word Count 是使用 Hadoop 平台的 map-reduce 编写的用于统计文本单词出现频率的程序。在实验中,这种统计方法运行速度较慢,统计结果的准确性比中科院的ICTCLAS差,所以在实际使用中,在对准确性要求不是很高的情况下可以使用这种方法。其优点是可以将统计结果提取出来,用于系统其他模块的分析计算。 3 关键词提取算法TFLD 3.1 特征项 对于单个文本,有多个特征项可以反映单词对文本的重要性。除了常用的词频TF,词出现的位置、词长、词性和分词距离顺序等特征在反映文章[15]的主题方面也有一定的价值。文本分词和停用词过滤后的词集,为了提取文本的关键词,本文选取以下三个特征项计算每个词的权重值。 (1)词频tf:是关键词提取中最常用的参数之一,是词的最简单度量。本文中,词频通过非线性函数计算:(< @1) 其中是每个词在文本中出现的次数。非线性处理的优点如下: 1)词频的特征值随着出现次数的增加而增加。并且增加,词频收敛为1,表示该词出现的次数较多。2)当一个词出现的次数比较多时,后面的词频特征值不会随着该词的出现次数继续增加幅度变化,使得单词被用作关键词的概率不会随着出现次数的不断增加而明显增加,更符合实际语言。(2)位置...

