操作方法:小旋风蜘蛛池如何写采集规则教程?
优采云 发布时间: 2022-09-25 11:12操作方法:小旋风蜘蛛池如何写采集规则教程?
本文是小旋风蜘蛛池编写后台采集规则的一套完整教程。如果您可以使用 优采云采集器 或 优采云采集器,请跳过本教程。简单易用。
本文仅以X6版小旋风蜘蛛池为例。有任何问题可以在文末留言。
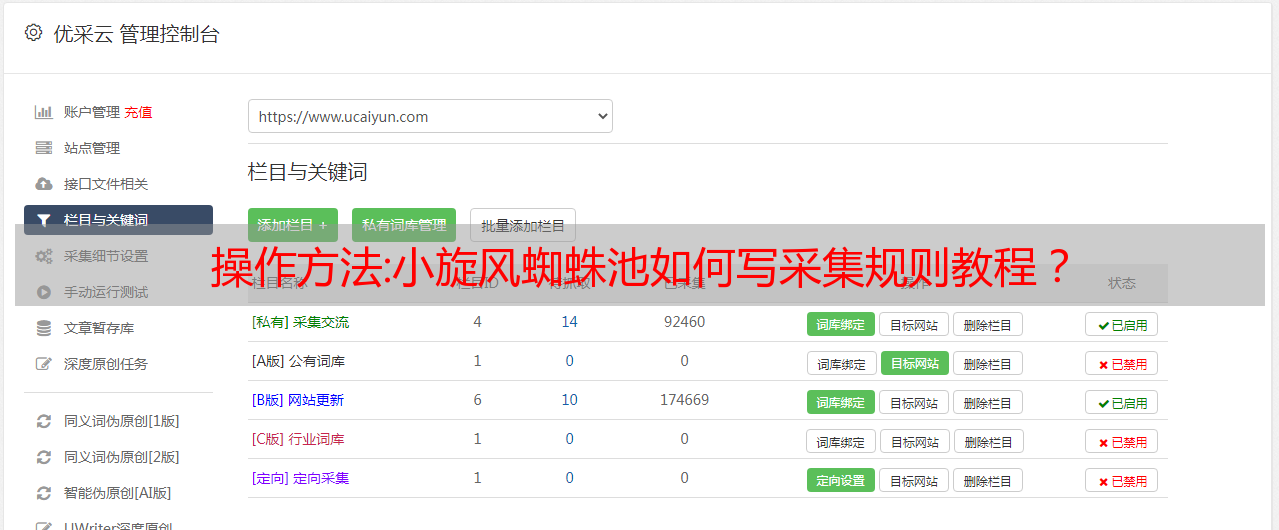
一、小旋风蜘蛛池怎么弄采集标题
题库采集还是很简单的,只需要设置源采集的地址即可。
首先添加 采集 规则,选择 文章 标题。
分页书写:
标记
http://roll.news.sina.com.cn/news/gnxw/gdxw1/index_{p,1,9,1}.shtml
{p,1,5,1}表示分页,参数:p后面的数字代表开始、结束、递增/递减值,即{p,start,end,递增/递减值}
标记
http://roll.news.sina.com.cn/news/gnxw/gdxw1/index_1.shtml
http://roll.news.sina.com.cn/news/gnxw/gdxw1/index_2.shtml
http://roll.news.sina.com.cn/news/gnxw/gdxw1/index_3.shtml
<p>
http://roll.news.sina.com.cn/news/gnxw/gdxw1/index_4.shtml
http://roll.news.sina.com.cn/news/gnxw/gdxw1/index_5.shtml
http://roll.news.sina.com.cn/news/gnxw/gdxw1/index_6.shtml
http://roll.news.sina.com.cn/news/gnxw/gdxw1/index_7.shtml
http://roll.news.sina.com.cn/news/gnxw/gdxw1/index_8.shtml
http://roll.news.sina.com.cn/news/gnxw/gdxw1/index_9.shtml</p>
测试规则时可以从 URL 匹配中看到。添加后,测试看看效果:
二、小旋风蜘蛛池怎么样采集句子和文章
添加规则:选择整个内容或句子段落
比如我们要采集新浪新闻,地址是:,只需在列表配置选项的匹配URL中填写上述地址即可。
打开 采集 来源的地址并选择一条新闻。复制其链接地址。
这是地址:
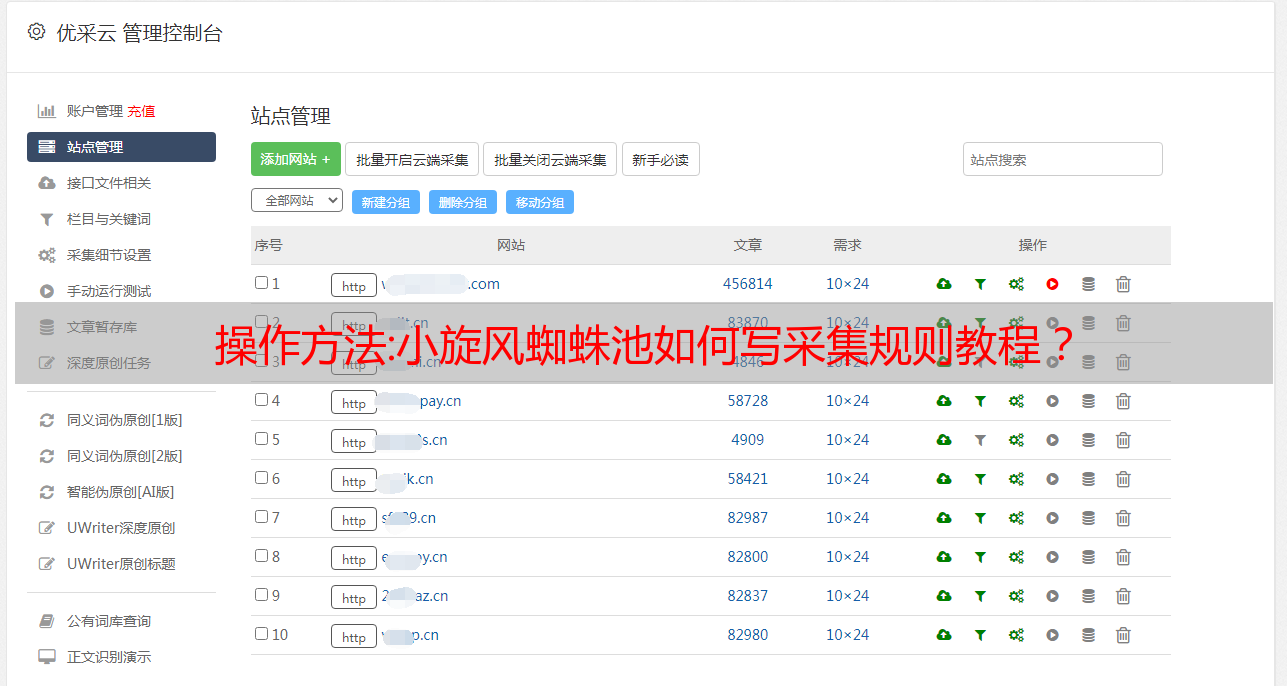
那么,内容匹配规则可以这样写
标记
https://news.sina.com.cn/(w)/(d)-(d)-(d)/(w)-(w).shtml
内容拦截规则:
打开内容地址。右键查看源代码,找到内容区。
那么内容拦截规则可以这样写:
对于像新浪这样的大型网站,它的内容页面有些不同,我们可以写更多的匹配。
保存后,看看效果。
注意:您的 采集 句子和 文章 将自动 采集 链接到图片,所以不用担心您的内容库中没有图片!
本文由网友投稿或由“jucode源码网”整理自互联网。如需转载,请注明出处:
如果本站发布的内容侵犯了您的权益,请联系zhangqy2022#删除,我们会及时处理!
技巧:爬虫与反爬虫技术简介
随着互联网大数据时代的到来,网络爬虫也成为了互联网的重要产业。它是一个自动获取网页数据和信息的爬虫程序,是网站搜索引擎的重要组成部分。通过爬虫,您可以获得您想要的相关数据信息,让爬虫辅助您的工作,从而降低成本,提高业务成功率,提高业务效率。
本文一方面从爬虫和反反爬虫的角度解释了如何高效爬取网络上的开放数据。采集提供一些关于数据处理服务器过载的建议。
爬虫是指按照一定的规则自动从万维网上抓取信息的程序。本次主要介绍爬虫、反爬虫、反爬虫的技术原理和实现。对于安全研究和学习,它不会做很多爬虫或商业应用。
一、爬虫技术原理及实现
1.1 爬虫的定义
爬虫分为两类:一般爬虫和重点爬虫。前者的目标是爬取尽可能多的网站,同时保持一定的内容质量。比如百度等搜索引擎就是这类爬虫,如图1是一般搜索引擎的基础架构:
首先选择互联网中的一部分网页,将这些网页的链接地址作为*敏*感*词*URL;
将这些*敏*感*词*URL放入待爬取的URL队列中,爬虫从待爬取的URL队列中依次读取;
通过DNS解析URL,并将链接地址转换为网站服务器对应的IP地址;
网页下载器通过网站服务器下载网页,下载的网页是网页文档的形式;
提取网页文档中的网址,过滤掉已抓取的网址;
继续抓取没有被抓取的网址,直到待抓取的网址队列为空。
图1.通用搜索引擎的基础架构
爬虫通常从一个或多个URL开始,在爬取过程中不断将符合要求的新URL放入待爬队列中,直到满足程序的停止条件。
我们日常看到的爬虫基本都是后者。目标是在抓取少量网站的同时尽可能保持准确的内容质量。一个典型的例子如图2所示,抢票软件,利用爬虫登录票务网络,爬取信息辅助业务。
了解了爬虫的定义之后,我们应该如何编写爬虫程序来爬取我们想要的数据。我们可以先了解一下目前常用的爬虫框架,因为它可以写一些常用爬虫功能的实现代码,然后留下一些接口。在做不同爬虫项目时,我们只需要根据实际情况编写少量改动即可。 ,并根据需要调用这些接口,即可以实现爬虫项目。
1.2 爬虫框架介绍
常用的搜索引擎爬虫框架如图3所示。首先,Nutch是专门为搜索引擎设计的爬虫,不适合精准爬取。 Pyspider和Scrapy都是用python语言编写的爬虫框架,都支持分布式爬虫。另外,由于其可视化的操作界面,Pyspider比Scrapy的全命令行操作更加人性化,但功能不如Scrapy强大。
图3.爬虫框架对比
1.爬虫3个简单例子
除了使用爬虫框架进行爬取外,还可以从零开始编写爬虫程序。步骤如图4:
图4.爬虫基本原理
接下来,我们将通过一个简单的示例来实际演示上述步骤。我们要爬取的是某个应用市场的列表。我们以此为例,因为这个网站没有任何反爬的手段。通过以上步骤,我们可以轻松抓取内容。
图5.网页及其对应的源码
网页及其对应的源码如图5所示。对于网页上的数据,假设我们要爬取排行榜上每个应用的名称及其分类。
我们先分析网页的源码发现可以直接在网页的源码中搜索“抖音”等app的名字,然后看到名字应用程序的类别、应用程序的类别等都合二为一

