汇总:常用的大数据采集工具
优采云 发布时间: 2022-09-25 07:19汇总:常用的大数据采集工具
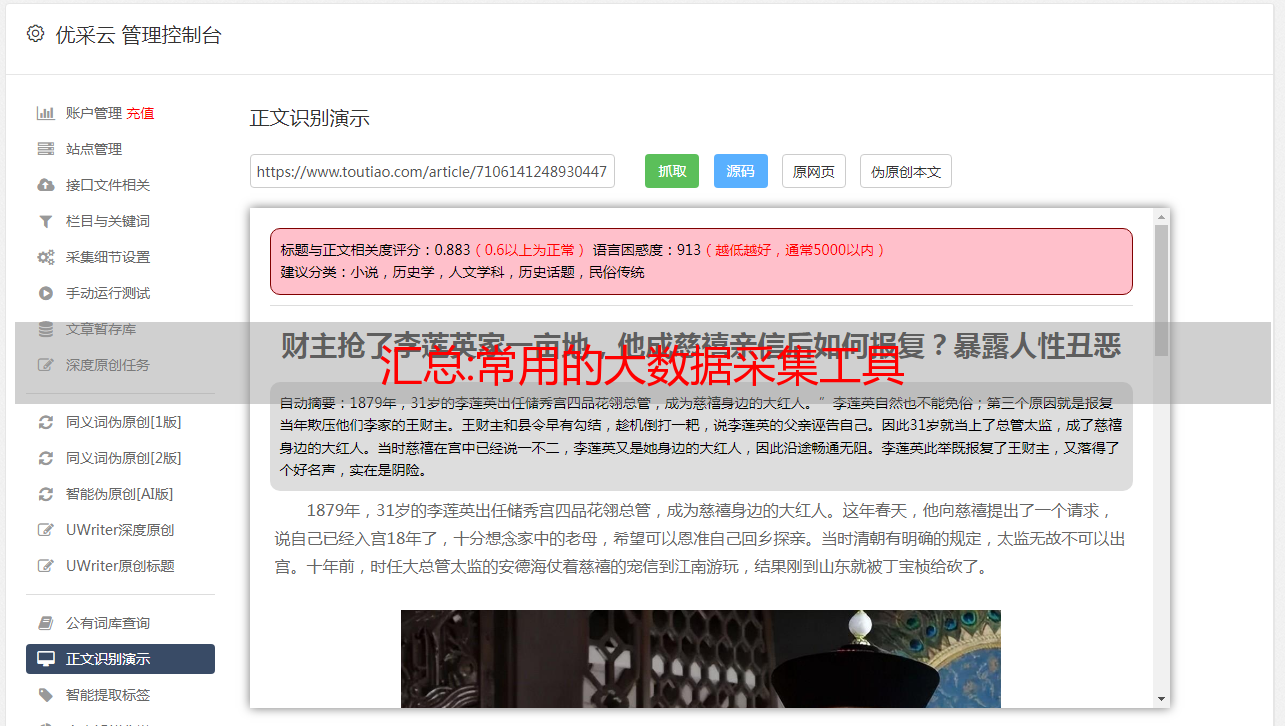
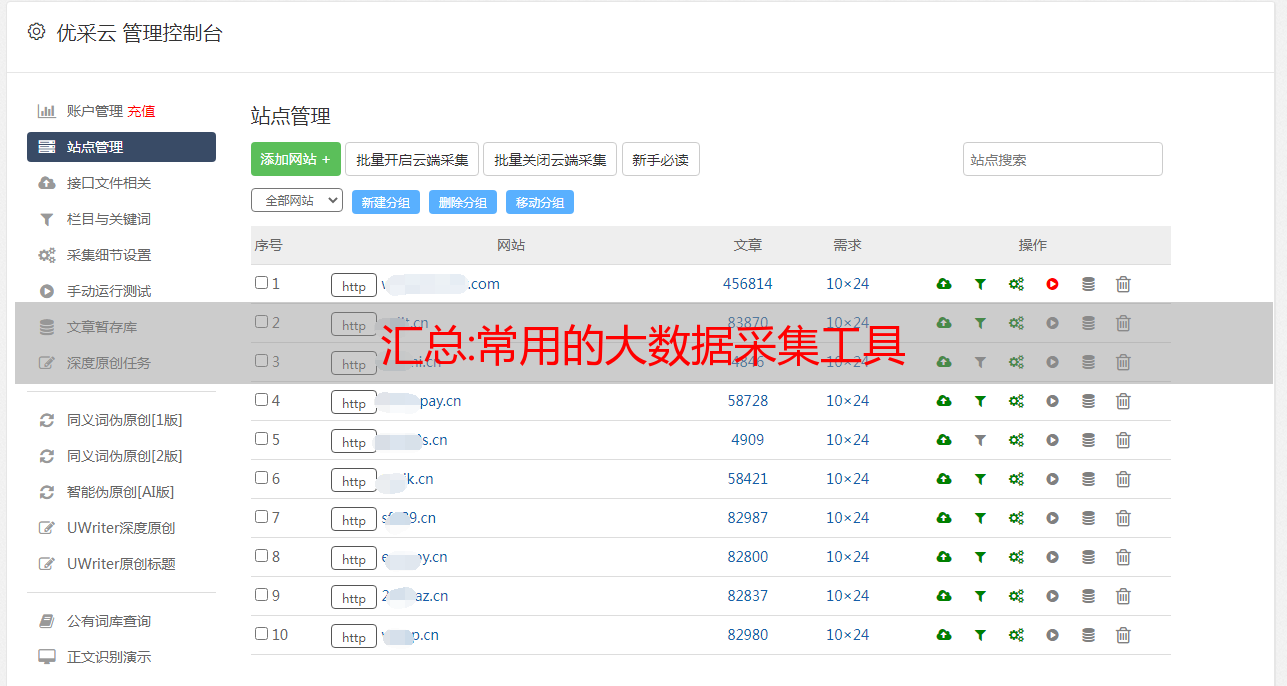
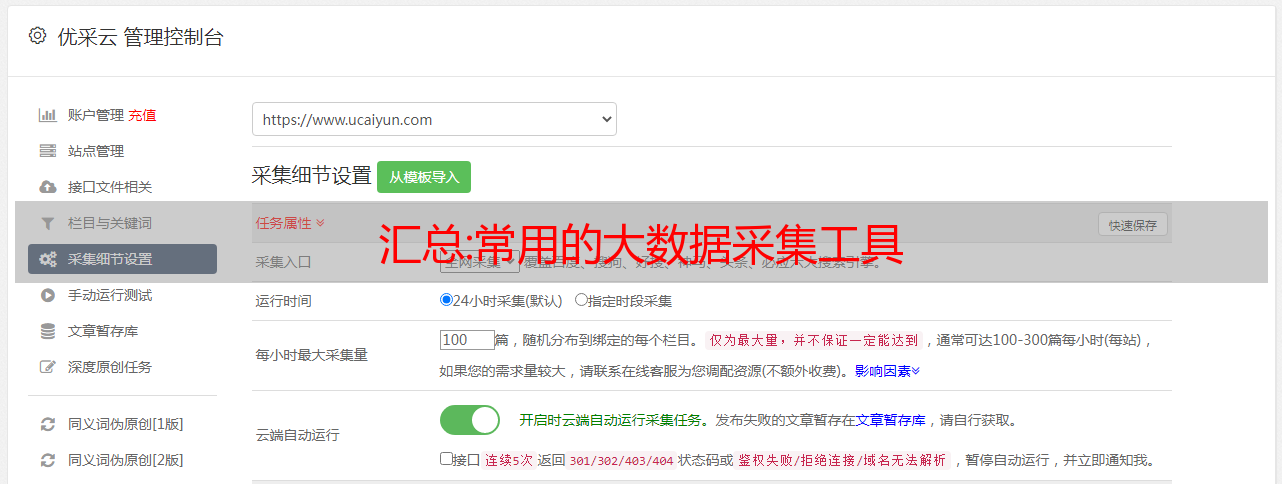
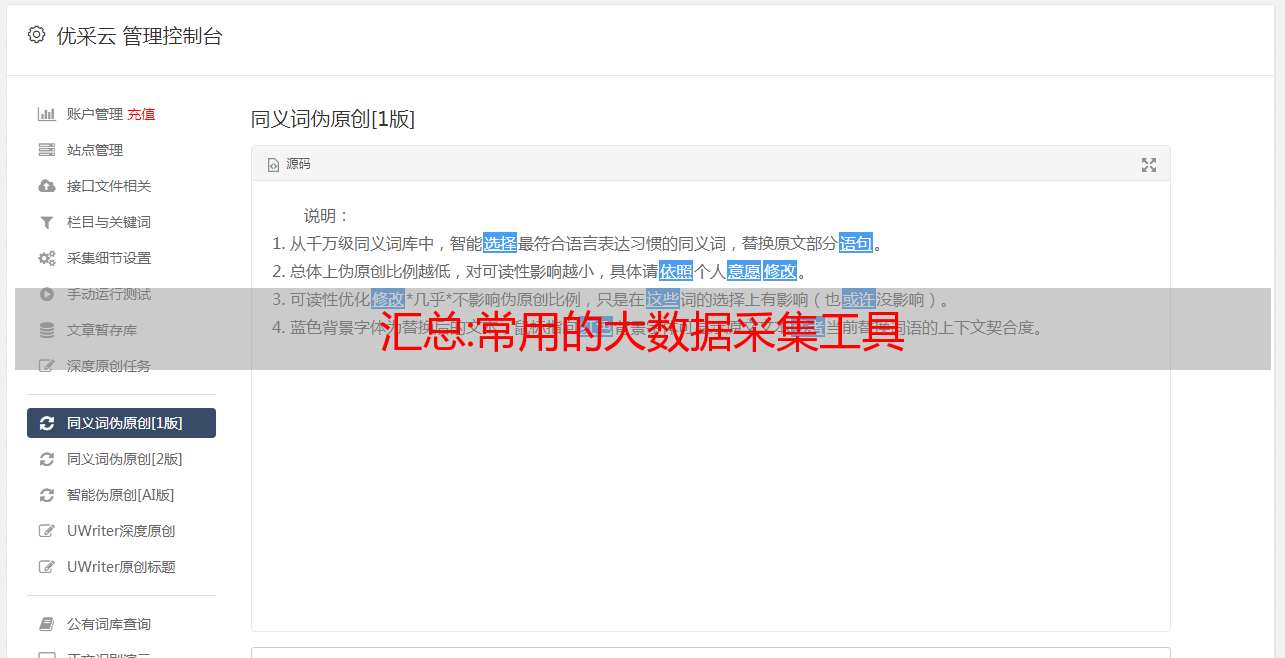
天津网站为了构建高效的采集大数据,关键是要根据采集环境和数据类型选择合适的大数据采集方法和平台下面介绍一些常用的大数据采集平台和工具。
1、水槽
Flume作为Hadoop的一个组件,是Cloudera专门开发的分布式日志采集系统。尤其是近年来,随着Flume的不断完善,用户在开发过程中的便利性有了很大的提升,Flume现已成为Apache Top项目之一。
Flume 提供了从 Console(控制台)、RPC(Thrift-RPC)、Text(文件)、Tail(UNIX Tail)、Syslog、Exec(命令执行)等数据源采集数据的能力。
Flume 采用多 Master 方式。为了保证配置数据的一致性,Flume 引入了 ZooKeeper 来保存配置数据。 ZooKeeper 本身保证了配置数据的一致性和高可用性。此外,ZooKeeper 可以在配置数据发生变化时通知 Flume Master 节点。 Flume Master 节点之间使用 Gossip 协议同步数据。
Flume对于特殊场景也有很好的自定义扩展能力,所以Flume适用于大部分日常数据采集场景。因为 Flume 是用 JRuby 构建的,所以它依赖于 Java 运行时环境。 Flume 设计为分布式管道架构,可以看作是数据源和目的地之间的代理网络,支持数据路由。
Flume 支持设置 Sink 的 Failover 和负载均衡,以保证在一个 Agent 故障时整个系统仍能正常采集数据。 Flume中传输的内容被定义为一个事件,一个事件由Headers(包括元数据,即Meta Data)和Payload组成。
Flume 提供 SDK,可以支持自定义开发。 Flume 客户端负责将事件发送到事件源的 Flume 代理。客户端通常与生成数据源的应用程序位于同一进程空间中。常见的 Flume 客户端有 Avro、Log4J、Syslog 和 HTTP Post。
2、流利的
Fluentd 是另一种开源数据采集架构,如图 1 所示。Fluentd 使用 C/Ruby 开发,使用 JSON 文件来统一日志数据。通过丰富的插件,您可以采集各种系统或应用程序的日志,然后根据用户定义对日志进行分类。使用 Fluentd,跟踪日志文件、过滤它们并将它们转储到 MongoDB 等操作非常容易。 Fluentd 可以将人们从繁琐的日志处理中彻底解放出来。
图 1 Fluentd 架构
Fluentd 具有多种特性:安装方便、占用空间小、半结构化数据记录、灵活的插件机制、可靠的缓冲、日志转发。 Treasure Data 为本产品提供支持和维护。此外,使用 JSON 统一的数据/日志格式是它的另一个特点。相比 Flume,Fluentd 的配置相对简单。
Fluentd 的可扩展性很强,客户可以自定义(Ruby)输入/缓冲区/输出。 Fluentd 存在跨平台问题,不支持 Windows 平台。
Fluentd 的 Input/Buffer/Output 与 Flume 的 Source/Channel/Sink 非常相似。 Fluentd 架构如图 2 所示。
图 2 Fluentd 架构
3、Logstash
Logstash 是著名的开源数据栈 ELK(ElasticSearch、Logstash、Kibana)中的 L。因为 Logstash 是用 JRuby 开发的,所以运行时依赖于 JVM。 Logstash的部署架构如图3所示。当然,这只是一个部署选项。
图 3 Logstash 部署架构
一个典型的Logstash配置如下,包括Input和Filter的Output的设置。
复制
input {
file {
type =>"Apache-access"
path =>"/var/log/Apache2/other_vhosts_access.log"
}
file {
type =>"pache-error"
path =>"/var/log/Apache2/error.log"
<p>
}
}
filter {
grok {
match => {"message"=>"%(COMBINEDApacheLOG)"}
}
date {
match => {"timestamp"=>"dd/MMM/yyyy:HH:mm:ss Z"}
}
}
output {
stdout {}
Redis {
host=>"192.168.1.289"
data_type => "list"
key => "Logstash"
}
}</p>
几乎在大多数情况下,ELK 同时用作堆栈。如果您的数据系统使用 ElasticSearch,Logstash 是首选。
4、楚夸
Chukwa 是 Apache 拥有的另一个开源数据采集平台,其知名度远不如其他平台。 Chukwa 建立在 Hadoop 的 HDFS 和 MapReduce(用 Java 实现)之上,以提供可扩展性和可靠性。它提供了许多模块来支持 Hadoop 集群日志分析。 Chukwa 还提供数据展示、分析和监控。该项目目前处于非活动状态。
Chukwa 满足以下需求:
(1)灵活、动态可控的数据源。
(2)高性能、高度可扩展的存储系统。
(3)适用于分析采集的*敏*感*词*数据的架构。
Chukwa 架构如图 4 所示。
图 4 Chukwa 架构
5、抄写员
Scribe 是 Facebook 开发的数据(日志)采集系统。其官网多年未维护。 Scribe 为日志的“分布式采集、统一处理”提供了可扩展和容错的解决方案。当中央存储系统的网络或机器出现故障时,Scribe 会将日志转储到本地或其他位置;当中央存储系统恢复时,Scribe 会将转储的日志重新传输到中央存储系统。 Scribe 通常与 HADOOP 结合使用,将日志推送(push)到 HDFS,而 Hadoop 通过 MapReduce 作业进行定期处理。
Scribe 架构如图 5 所示。
图 5Scribe 架构
Scribe的结构比较简单,主要包括Scribe代理、Scribe和存储系统三部分。
6、Splunk
在商用大数据平台产品中,Splunk提供完整的数据采集、数据存储、数据分析处理、数据呈现能力。 Splunk 是一个分布式机器数据平台,具有三个主要角色。 Splunk 架构如图 6 所示。
图 6 Splunk 架构
搜索:负责数据的搜索和处理,在搜索过程中提供信息提取功能。
Indexer:负责数据的存储和索引。
Forwarder:负责数据的采集、清洗、变形、发送到Indexer。
Splunk 内置了对 Syslog、TCP/UDP 和 Spooling 的支持。同时,用户可以通过开发 Input 和 Modular Input 来获取特定的数据。 Splunk提供的软件仓库中有很多成熟的数据采集应用,比如AWS、数据库(DBConnect)等,可以很方便的从云端或者数据库中获取数据,输入到Splunk的数据平台进行分析.
Search Head和Indexer都支持Cluster配置,即高可用和高扩展,但是Splunk还没有Forwarder的Cluster功能。也就是说,如果一台Forwarder机器发生故障,数据采集将中断,正在运行的数据采集任务无法故障转移到其他Forwarder。
7、Scrapy
python 的爬虫架构叫做 Scrapy。 Scrapy 是一个使用 Python 语言开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。 Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于,它是一种任何人都可以轻松修改以满足其需求的架构。还提供了各种爬虫的基类,如BaseSpider、Sitemap爬虫等。最新版本提供了对Web2.0爬虫的支持。
Scrapy的工作原理如图7所示。
图7 Scrapy运行原理
Scrapy 的整个数据处理流程由 Scrapy 引擎控制。 Scrapy 运行如下:
(1)当Scrapy引擎打开一个域名时,爬虫对域名进行处理,让爬虫获取第一个爬取的URL。
(2)Scrapy引擎首先从爬虫中获取第一个需要爬取的URL,然后在调度中作为请求调度。
(3)Scrapy 引擎从调度器获取要抓取的下一页。
(4)调度将下一次爬取的url返回给引擎,引擎通过下载中间件发送给下载器。
(5)下载器下载网页时,通过下载器中间件将响应内容发送给Scrapy引擎。
(6)Scrapy引擎收到下载器的响应,通过爬虫中间件发送给爬虫处理。
(7)爬虫处理响应并返回爬取的物品,然后向Scrapy引擎发送新的请求。
(8)Scrapy 引擎将抓取的项目放入项目管道,并向调度程序发送请求。
(9)系统重复(2)之后的操作,直到调度器中没有请求,然后断开Scrapy引擎与域的连接。
免费的:数据采集-免费实时数据自动采集软件
数据采集,网上的网络数据大致分为文字图片数据、音频数据、视频数据,我们怎样才能快速采集这些数据供我们使用呢?今天给大家分享一款免费的网络数据采集软件。整个可视化过程基于0采集,具体请看图。
SEO技术经过多年的行业培训,经历了很多SEO优化行业精英,但是太多的行业精英不愿意分享SEO,很多人,尤其是学者,都非常清楚。
一、符合网站结构
网站架构的主要目的是解决收录问题,简化代码,在实际站点中应用关键标签,设计插件,融合交互思想从用户体验的角度, 网站更重要只要用技术解决网站收录的问题,用户体验的美感更重要。因此,过去缺乏网站程序员和网络艺术家采集指的是懂搜索引擎优化的设计师。该框架不仅要解决链接级别的问题,还要解决关键页面和列链接的分配问题。总结了四点:结构解决链接层次; 网站模板解决用户体验问题;模板设计解决了收录问题;链接分配解决了用户粘性问题。
二、网站复制
只要解决网站收录的问题,文案比其他环节更重要网站排名的核心问题是原创的性和合规性文章用户的利益无论你推广什么产品,数据采集都需要解决用户的利益。用户无论是来网站阅读知识还是购买产品,都需要根据网站的数据准确定位和购买产品。针对用户群,分析编写文章的关键词更有利于网站的粘性和网站的质量。
三、外链质量问题
SEO比赛分为站内SEO和站外SEO。不同的方法将决定SEO的方向关键词白帽SEO和黑猫SEO的并存也将决定网站的质量和权重。站内SEO总结如上,站内编辑、链接分配、用户体验要求等。站外SEO主要指SEO外链,分为好友链接、数据采集、好友链接分为相关链接和非相关链接;至于其他外链,主要是现场宣传,即场外公众投票在网站上,投票数与外链的质量密切相关,而外链的质量和数量不能获胜的环节将是决定性的。
四、网站内部问题
文章的及时更新与用户需要的时间息息相关,主要是对用户来说,实用性和时效性很重要通过实践测试可以更符合大众的要求,无论你的网站@ > 质量很受欢迎。
首先,外部链接总是指向主页。提前规划好外链来支持一套实施方案有用吗,但是很少有SEO会拼命的放出首页连接,数据采集为了快速提高关键词排名上另一方面,公司老板们也强烈要求从今天开始优化排名,明天的网站将登上百度引擎首页。主页,
不想在内容页的外链上花功夫如何安装自己的外链8:2的首页和内容页有外链比例有人会说,数据采集早期,我们应该已经做了网站的首页链,等首页排名上升,再把内容链做合适。小编想说目前没有问题,但是从长远来看,这样的外链搭建方式并不适合科学自然的外链,更别说在网站一开始的推出,还是很优化的,有必要根据这样的分享做外链。
第二,如何优化主链词和长尾链词的排名。每个老板都知道并了解SEO。采集对方认为主打伤害成本会高于长尾,赚的更多,导致更多的公司选择主关键词,失去长尾关键词的优势。长尾关键词有什么优势?首先,长尾关键词的优化排名一般是由公司网站的产品页面来支持的。当潜在客户通过长尾关键词进入页面时,产品页面将直接显示给他们,而不是首页,
需要自己找资料二、数据采集长尾关键词优化简单,流量转化率特别高,鼓励SEO做一次部署二次部署像往常一样关键词选择,数据采集这样不仅有利于网站的长期增长,还可以减少SEOER的工作量,简化网站优化。
三要重点政策关键词做网站内容百度越来越重视网站内容质量可以提升排名,这是永恒的真理即便如此,数据采集很多SEO还是把重点放在自己的内容上,不管更新的内容是否和网站话题有关,比如网站的话题是火信息,但是更新的网站内容就是信息这样的知识,不提倡围绕网站关键词创建内容格式,不仅用户不需要,我们更新的时候seo搜索引擎也不喜欢内容,

