解决方案:怎样精准搜索关键词-批量精准关键词采集-自动关键词挖掘
优采云 发布时间: 2022-09-22 06:06解决方案:怎样精准搜索关键词-批量精准关键词采集-自动关键词挖掘
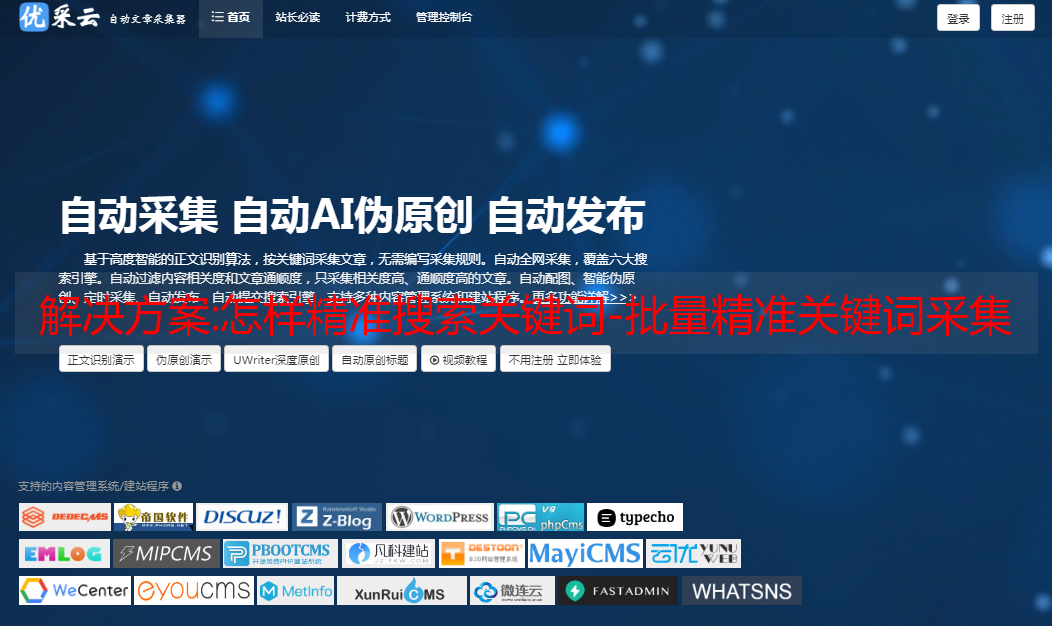
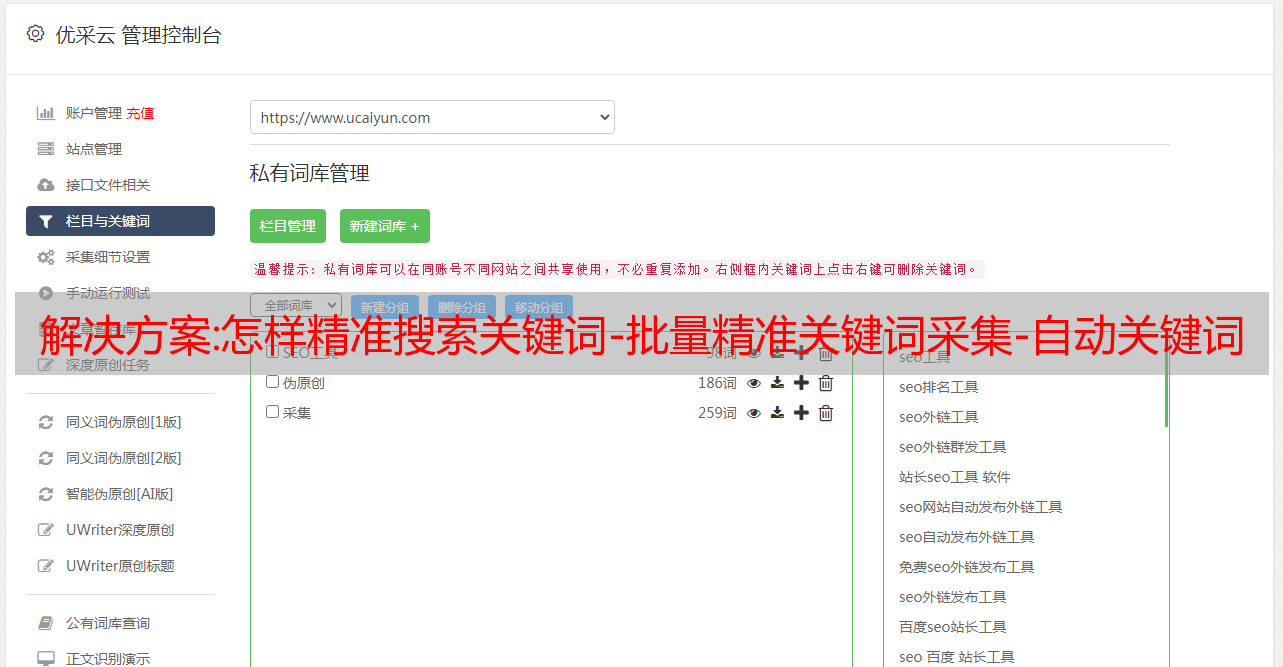
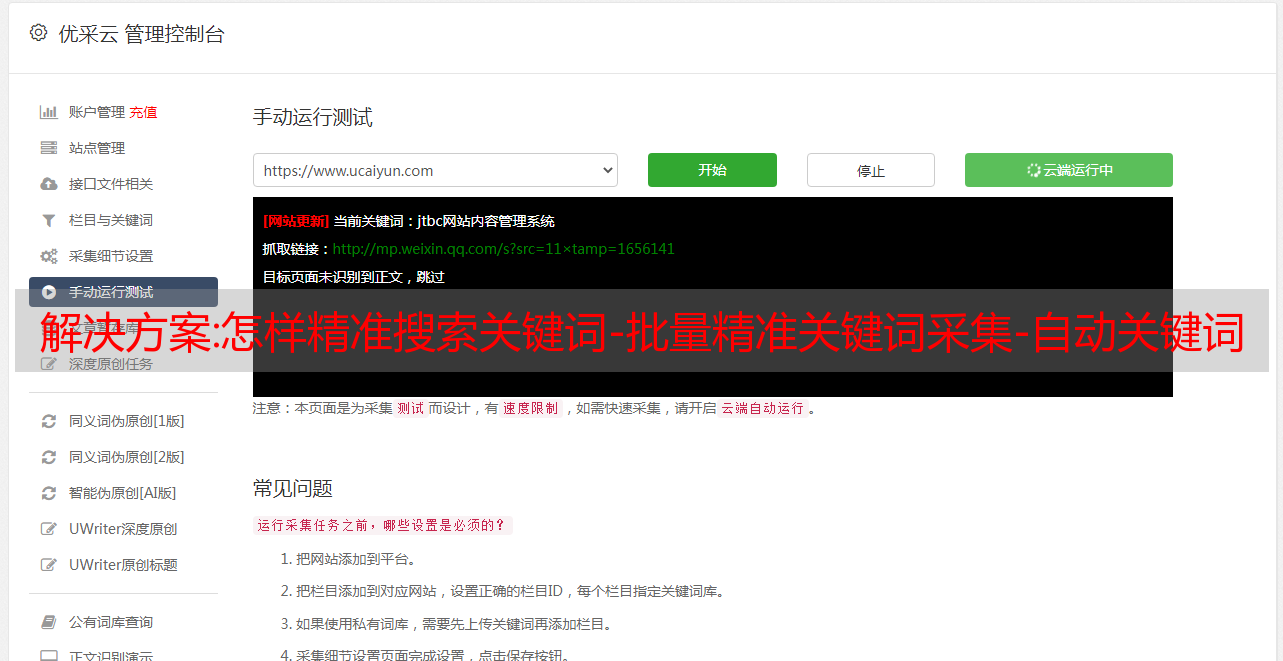
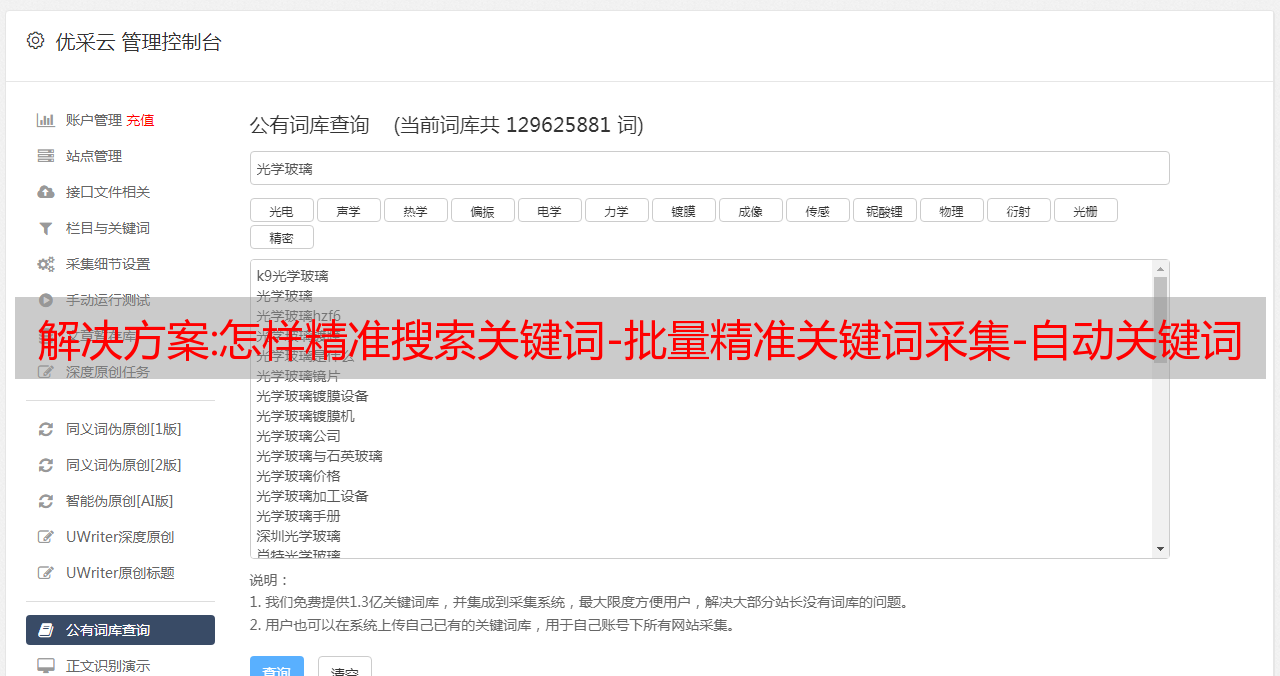
如何精确搜索关键词,为什么要搜索精确关键词,有没有精确搜索的工具关键词?相信大家都知道关键词这个以关键词为代表的方向这个用户群的重要性,但是市面上很多免费的关键词工具挖出来的话都不是很准确,不能批量挖矿,挖矿关键词也是杂项。今天给大家分享一款免费准确的关键词挖矿工具。包括核心词的挖掘,优先挖掘用户正在搜索的关键词,实时挖掘最新最热的关键词。具体请参考图一、图二、图三、图四、图五、图6
关于SEO优化,应该很多朋友都听说过,很多朋友都了解它的功能,但是还是要了解它的概念。其实简单来说,搜索引擎优化,也叫SEO,是一种分析搜索引擎排名规则的技术,了解各种搜索引擎是如何进行搜索的,如何爬取互联网页面,如何确定网站的排名。特定的 关键词 搜索结果。搜索引擎采用易于搜索引擎使用的方法,对网站进行针对性优化,提高网站在搜索引擎中的自然排名,吸引更多用户访问网站,提高网站的流量,提高网站的销售和宣传能力,从而提升网站的品牌效应,就是这个概念。
1、我们要制定一个合理的seo学习周期和目的
可能很多seo自学者会问:为什么要给自己设定一个合理的seo学习期限和目的? ,其实很简单。你必须对你所做的每一件事都有一个计划和目标。如果没有目标和学习计划,那么简单的事情就近在咫尺,你永远无法取胜。所以,给自己设置一个seo学习期是学好seo的前提。 , 初学者的学习期可以设置为两个月或三个月。然后我给自己定了一个seo学习期,我要好好想想这个时间段是否合理,为什么合理,因为很多同学对seo的理解和seo的基础知识把控不一样。有的同学2个月就学会了,有的同学3个月就学不下去了,心不强的同学可能会觉得受挫,开始厌学,最后很快放弃,所以给自己。设定合理的 seo 学习期限是胜利的第一步。
如果你想知道自己学过的seo内容,通常可以通过这些方式获得。首先,可以在网上搜集seo相关的资料和书籍,或者zhaoseo的学习资料。在这里我建议大家关注视频和书籍。由于最好的学习方式是看视频,而不是看书,这样可以少走很多弯路,快速掌握核心知识。
网站的不同时段如何停止优化?这个关于网站优化的问题相信是大部分站长朋友关心的问题,所以我们先从一个简单的开始更好的理解,大家应该都知道网站的开发过程离不开三个阶段,即网站建站的初期、中期和后期,而网站的每个阶段在不同的阶段,我们应该有不同的优化思路来优化 网站。从网站上线初期,做好网站的基础优化,提高网站的综合得分,抓住最佳优化机会,避免网站以后的优化开发过程中走了很多弯路,从而使网站的优化开发更加高效网站在不同时期的成功如何止步优化细节。
2、网站未来发展方向的定位
网站在建站初期(这里说的是上线前的网站),一定要规划好网站未来的发展方向。这是一件非常重要的事情。如果你网站想变大。那么,我们应该如何规划网站未来的发展方向呢?这里我就跟大家说一下,比如:你网站未来会去什么发展领域,发展空间有多大,潜力有多大?预计受众是多少?能不能吸够足够的观众,有多少观众,这些问题要引起重视,要按计划去执行。再好网站,没人看就一文不值。所以,一定要好好规划网站的发展方向。这是做到网站最根本、最关键的一步。
3、网站关键词选择与规划
规划完网站,下一步就是停止选择规划网站关键词,那么,我们该怎么办呢?我们在选择网站关键词,一定要符合网站的开发内容,还要选择一些能吸引用户,有用户搜索索引的关键词,因为这是确保您这样做的唯一方法 This 关键词 有用户需求。我们可以使用百度下拉框和百度索引选择网站中的关键词。详情可点击阅读文章:如何分析和选择SEO关键词。
选择关键词时,这意味着停止计划网站 关键词,那么,如何计划网站 关键词? ?这里漳州实现网站给大家解释一下,我们可以在网站的首页规划一个比较主要的关键词,规划一些子关键词到网站在@>的栏目页面,这样可以让网站在不失用户体验的情况下突出重点。而且对于网站的优化,这样的规划关键词可以让你网站的关键词获得更好的排名,也可以让你网站@ > 分数越高,权重越高。
4、网站文章内容填充
完成以上两步后,站点文章中网站的内容就停止了。友情提示:网站在刚刚上线没有内容的情况下,不要急着去各大搜索引擎提交词条提交我们的网站,因为你的网站还没有内容,一方面不能处理用户需求,另一方面影响网站文章内容的收录速度。因此,网站上线后,我们必须在提交前填写文章的内容。正常情况下,网站站点中文章的内容要占满内容的80%以上,也就是要保证网站的每个栏目页面必须有文章,如果没有,一定要保证我们要做的主栏页必须有文章内容。对于网站收录的问题,我们可以在填写文章的内容后制作网站的地图,辅助搜索引擎蜘蛛的爬取,提高网站 @网站 的 收录 速度。
安全解决方案:【Flume采集业务日志写入Hadoop】
使用Flume采集将业务日志写入Hadoop目录
需求
在大数据开发中,经常会涉及到非结构化数据的业务需求采集。其中,对业务日志的需求最为普遍。需要将生成的新日志 采集 传输到 HDFS。业务流程图如下。
开发步骤部署flume
将Flume安装包上传到数据源所在节点,并解压
tar -zxvf apache-flume-1.7.0-bin.tar.gz -C /opt/soft_installed/
进入flume目录,修改conf下的flume-env.sh,在里面配置JAVA_HOME
cd /opt/soft_installed/apache-flume-1.7.0-bin
cp flume-env.sh.template flume-env.sh
vim flume-env.sh
export JAVA_HOME=/opt/soft_installed/jdk1.8.0_171
准备测试数据
配置 Flume
flume 配置文件
[root@master conf]# cat spooldir-hdfs.conf
#定义三大组件的名称
agent1.sources = source1
agent1.sinks = sink1
agent1.channels = channel1
# 配置source组件
agent1.sources.source1.type = spooldir
<p>
agent1.sources.source1.spoolDir = /home/lh/hadooptest/logs/
agent1.sources.source1.fileHeader = false
# 配置*敏*感*词*
agent1.sources.source1.interceptors = i1
agent1.sources.source1.interceptors.i1.type = host
agent1.sources.source1.interceptors.i1.hostHeader = hostname
# 配置sink组件
agent1.sinks.sink1.type = hdfs
agent1.sinks.sink1.hdfs.path =hdfs://node1:9000/weblog/flume-collection/%Y%m%d/%H-%M
agent1.sinks.sink1.hdfs.filePrefix = access_log
agent1.sinks.sink1.hdfs.maxOpenFiles = 5000
agent1.sinks.sink1.hdfs.batchSize= 100
agent1.sinks.sink1.hdfs.fileType = DataStream
agent1.sinks.sink1.hdfs.writeFormat =Text
agent1.sinks.sink1.hdfs.rollSize = 102400
agent1.sinks.sink1.hdfs.rollCount = 1000000
agent1.sinks.sink1.hdfs.rollInterval = 60
#agent1.sinks.sink1.hdfs.round = true
#agent1.sinks.sink1.hdfs.roundValue = 10
#agent1.sinks.sink1.hdfs.roundUnit = minute
agent1.sinks.sink1.hdfs.useLocalTimeStamp = true
# Use a channel which buffers events in memory
agent1.channels.channel1.type = memory
agent1.channels.channel1.keep-alive = 120
agent1.channels.channel1.capacity = 500000
agent1.channels.channel1.transactionCapacity = 600
# Bind the source and sink to the channel
agent1.sources.source1.channels = channel1
agent1.sinks.sink1.channel = channel1
</p>
水槽采集日志数据
[root@master scripts]# cat flume_spooldir_logs.sh
#! /bin/bash
/opt/soft_installed/apache-flume-1.7.0-bin/bin/flume-ng agent -c /opt/soft_installed/apache-flume-1.7.0-bin/conf -f /opt/soft_installed/apache-flume-1.7.0-bin/conf/spooldir-hdfs.conf -n agent1 -Dflume.root.logger=INFO,console
[root@master scripts]#./flume_spooldir_logs.sh
[lh@master hadooptest]$ ls
access_log_01 access_log_02 access_log_03 input logs
[lh@master hadooptest]$ mv access_log_01 logs/
hadoop 检查采集结果
异常解决
问题描述: 当使用flume-ng进行日志采集的时候,如果日志文件很大,容易导致flume出现:
java.lang.OutOfMemoryError: Java heap space
解决方法: 调整flume相应的jvm启动参数。修改 flume下的conf/flume-env.sh文件:
```shell
export JAVA_OPTS="-Xms100m -Xmx256m -Dcom.sun.management.jmxremote"
思考题
在企业中,hdfs集群一般不存储小文件。目前,flume 配置存储了很多小文件。在这种情况下,公司将如何解决这个问题?给出你的解决方案。

