自动识别采集内容-6156-1--html申请认证
优采云 发布时间: 2022-09-19 03:05自动识别采集内容-6156-1--html申请认证
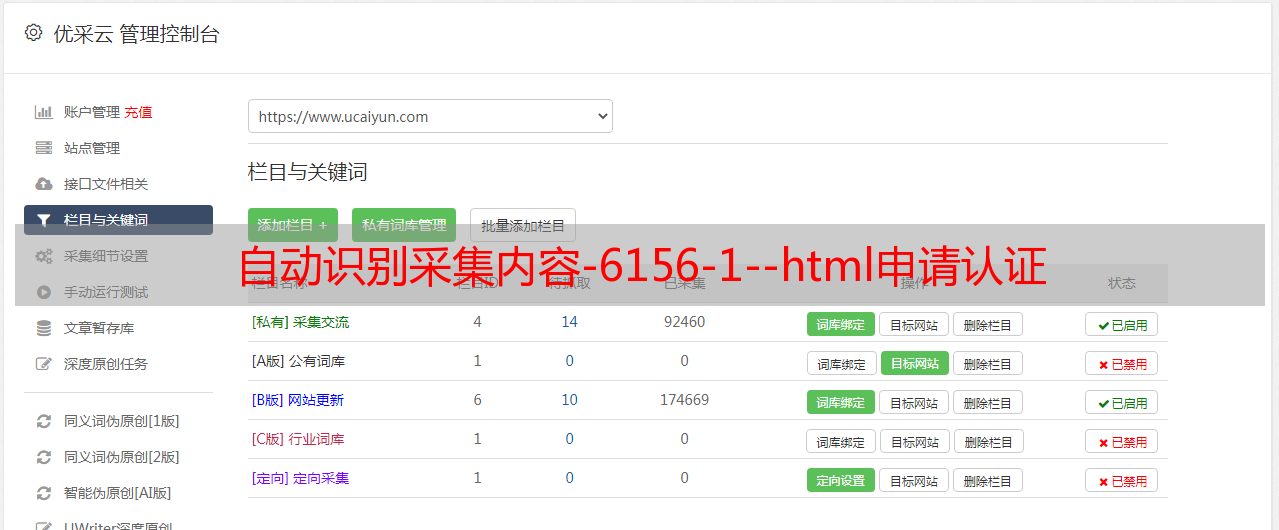
自动识别采集内容!!!首先申请认证!或者申请登录帐号!!!其次要生成html文件,
简单几步就好。-6156-1-1.html按照说明一步步来就行。
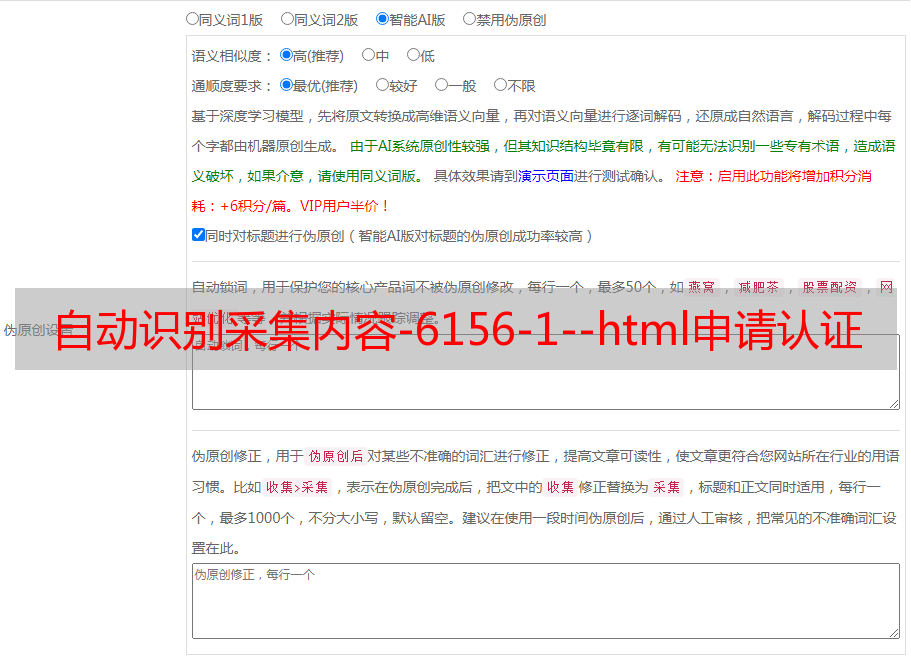
如果是自动爬虫的话,考虑到爬虫需要初始化才能使用一些基本功能(搜索排序,网站抓取,配置策略和脚本),或者是通过提取标题,布局搜索结果才能爬取,所以爬虫的设计最好是可以较为简单地放到代码里去处理。如果是采集网页的话,通常思路是首先采集网页列表,然后再逐个复制爬取网页。另外,内容的分词,也可以使用这个思路去思考处理。
经验不多,瞎说一下,
1、爬虫的部署你需要个防火墙
2、下载时验证码多了可能会崩
3、java什么模块你可以再问下朋友,让他给你点提示。
4、代码一定要写到显示文字部分,不然,爬虫放不下呢。
5、请求的get需要用request、post请求不要用post,
6、图片也需要考虑抗反爬
7、最好能getshader,这样js才能调用,从而实现js检测你爬虫是否正常爬取--你再问我。我真给你找点资料。

