网站自动采集文章的收获和不同类型爬取能力
优采云 发布时间: 2022-09-03 09:07网站自动采集文章的收获和不同类型爬取能力
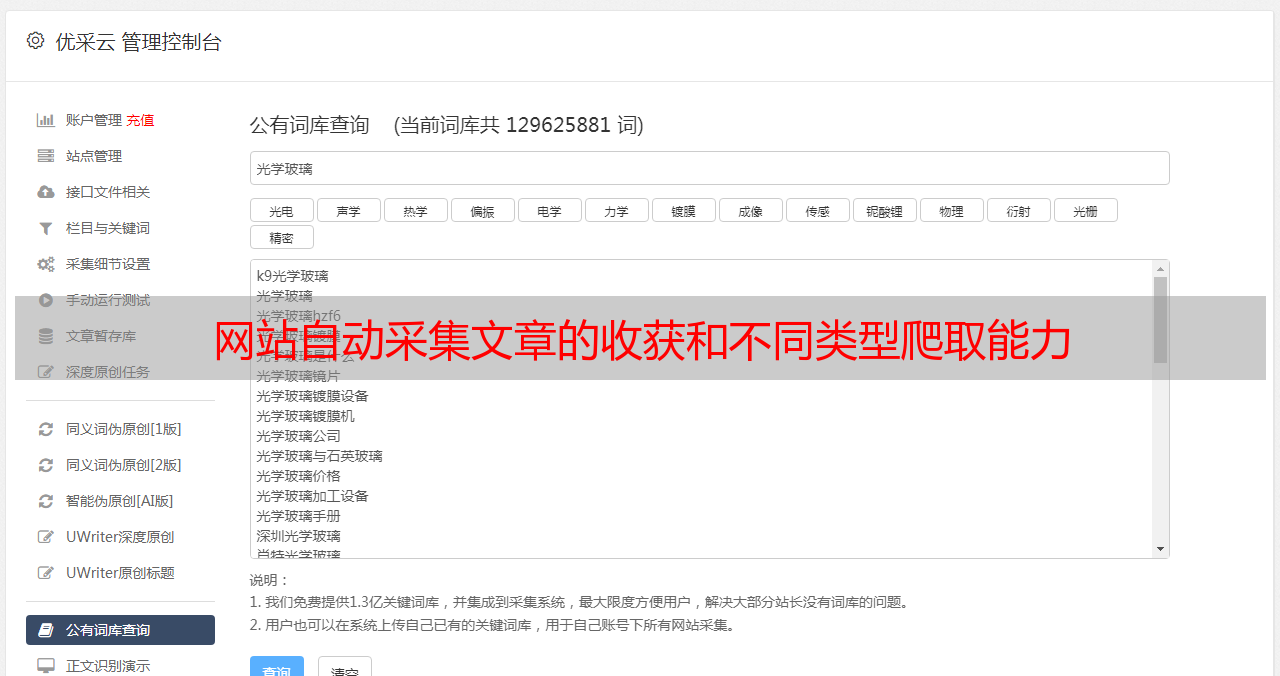
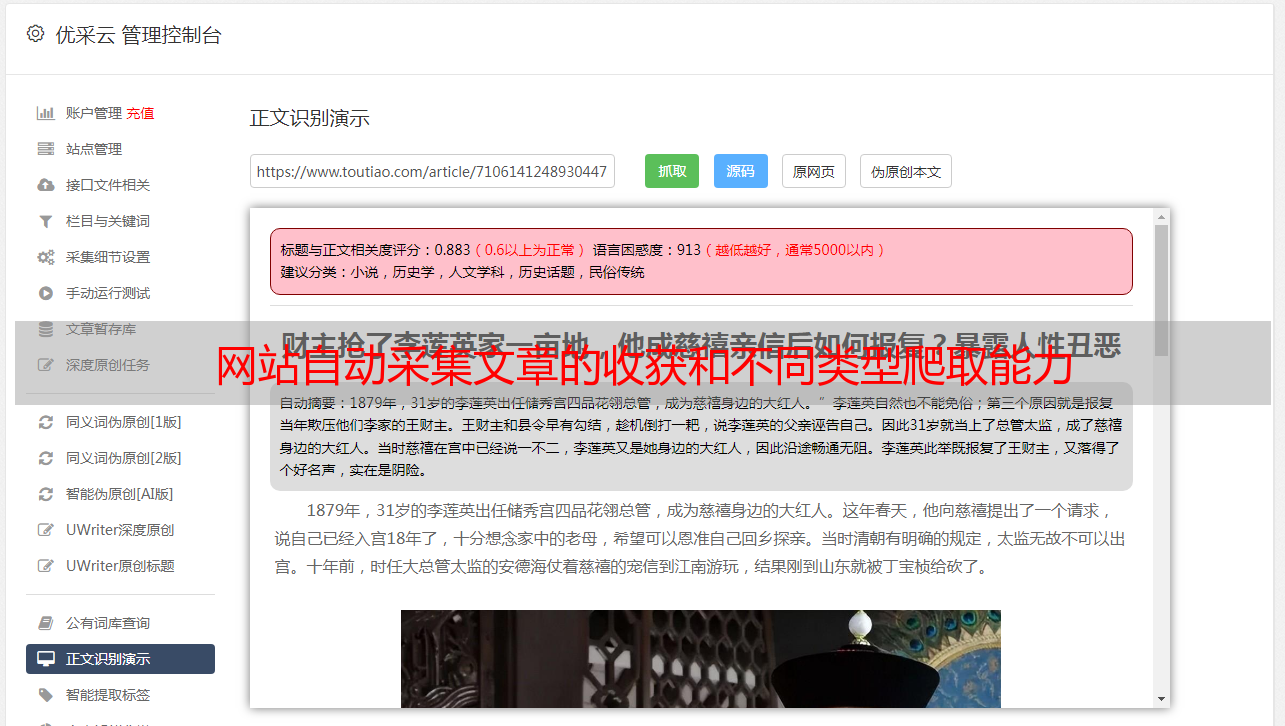
网站自动采集文章是一种用于快速获取大量网站、论坛、贴吧的文章资源的手段。这些网站资源多数来自于谷歌或者百度,然后迅速抓取页面内容,形成一个链接地址。一个网站上某一领域的文章,多数时候只会被一个网站采集到,网站虽然抓取了多个站,但是用户查看时会非常痛苦。相比于复制粘贴资源,全文编辑或者手动搜索并提取是更节省时间的方式。
而自动采集技术一直存在于网络上,从国内网站的seoer,到国外网站的seoer,甚至是人人皆可上手的数据采集软件。本文只是整理了最近几年网站采集技术研究的一些收获和不同类型的自动采集方式。一般网站自动采集分为autostarts和fairseek。autostarts一般用于检测是否存在有效的文章,而fairseek技术则是用于不同类型内容的页面抓取,有强大的文章搜索引擎源码爬取能力。
一、被搜索引擎长期爬取的网站fairseek本文只罗列一下最近一段时间爬取数据量巨大的被搜索引擎长期爬取的网站。1.“哈勃星网”这个网站自从2年前开始采集文章,并使用“过滤”技术,从front-end方向爬取,一直无法追踪被抓取的效果,直到今年6月份改用这个方式。2.panbymerainwolfrainwolf采集了包括facebook,twitter,username,wikipedia等很多平台上的文章内容,后来为了追踪爬取效果,改用multi-link(也就是多链接技术)爬取。但是,应用了上面说的fairsee技术,基本没有得到明显的提升,甚至已经比原始采集数据更糟糕。
二、精心采集的网站百度在新版本中专门提供了文章下拉框、不知道在哪里的文章推荐、关注、评论区、rssreader等服务,但仍然因为采集效果不佳而无法被搜索引擎采集。
三、精心采集的网站谷歌只提供了搜索关键词无限个链接的搜索服务,而大部分网站,即使是花费了大量精力采集,也收效甚微。
四、另类自动采集方式有些网站采集的方式比较奇特,还没有合适的自动采集工具,那么用另外一个部件实现自动化的采集,也许也许效果会好些。我将采集网站分为这么几类:1.图片采集。谷歌会采集类似piccurl和png,base64,png+xml,base64+eif等格式的图片。但是,谷歌的爬虫会把这些图片都和记录相应属性。
这样的图片采集,因为文章内容已经采集了,因此只需要再次手动处理图片,进行比较丰富的内容填充。2.新闻、博客采集。国内国外的新闻博客网站很多,比如《环球网》、《中国日报》等,他们的网站爬虫爬取相关新闻和评论。为了追踪爬取效果,可以定期参与爬取相关页面的监控,并根据采集效果进行调整。3.视频录制。那么就没必要采集视频,他会。

