全自动文章采集网源码2020.09.28(图)
优采云 发布时间: 2022-09-01 14:04全自动文章采集网源码2020.09.28(图)
全自动文章采集网源码2020.09.28有小伙伴私信问:什么是采集?采集其实就是把别人网站里面的文章采集过来!上周给大家分享的三种上网源码,今天在做采集同时,顺便给大家分享几种常用的采集方法。如何把别人网站里面的文章采集过来呢?通过excel就能达到,不仅采集到的文章数量多、又带价值,文章还很直观、视觉,只要懂一点程序设计的,用excel就能上手,这里所说的懂程序设计,都是懂数据库建设,一个简单的数据库,功能就能实现大部分数据采集!而下面的源码,不仅有源码,还有内部文章的批量抓取方法。
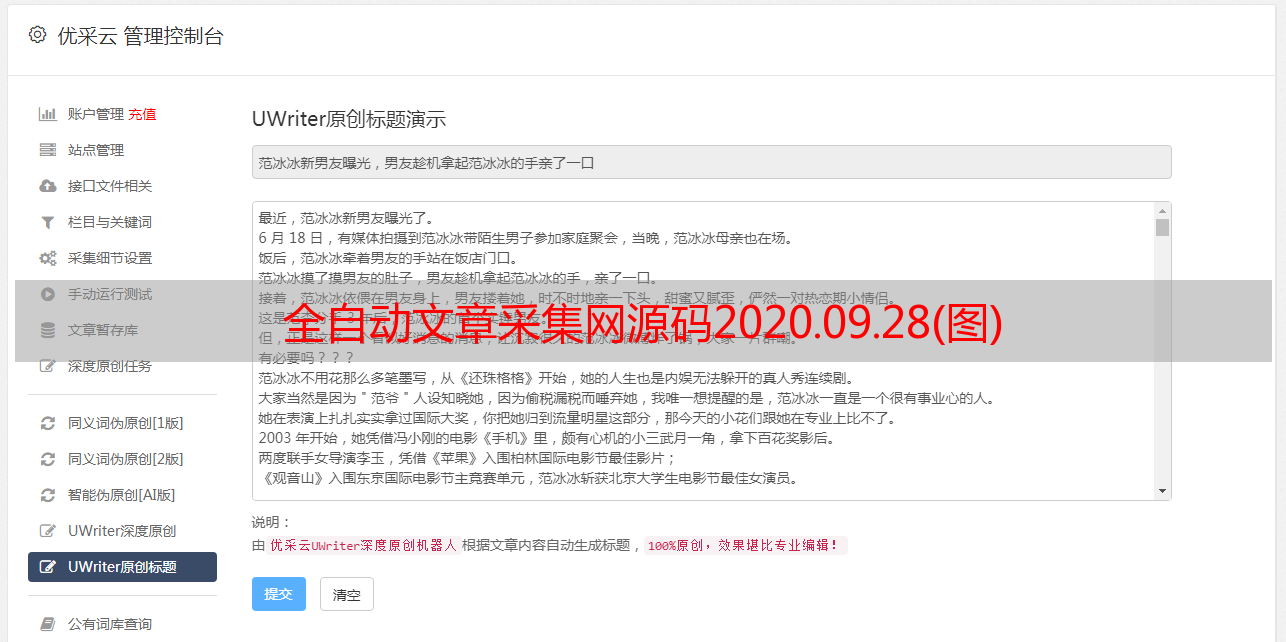
如果你是做seo的,或许你在大街上看到一篇美女,已经会用php爬虫去抓取下来!抓取过来的数据再利用excel文件进行处理!我们知道,批量操作php很简单,但对于爬虫抓取还没涉及,但因为经常要打开大量网站,而网站每天的内容不断更新,又不愿意手动去添加批量抓取规则,怕重复抓取。所以有些网站的网页是每天都会更新的,抓取规则一个采集不完,一个也抓取不到,而批量抓取到的数据就不一样了,这样数据清洗就方便多了!网站内容直接就能进行*敏*感*词*抓取,对数据挖掘、seo来说是最好的选择!所以下面将源码拆分一下,给大家讲解怎么进行批量抓取!如何批量抓取网页呢?下面就一步步给大家分析怎么操作!第一步:获取网页标题或者网址,用excel就能轻松搞定,一行代码就能搞定:打开网页源码可以看到,源码一共有1570544行,网址大家可以去通过上网查询找到。
第二步:打开代码为红色方框标识的“网页源码页”,这个地方也是重点,我们主要说一下“源码页”和“源码页”对应的“三级标题”和“每天更新”对应的“每个小格”,一共95837行。具体为:spider源码页url列表|python|c#|爬虫/汇总|技术交流/面试/经验/通信/实习/招聘。每一行都有对应的代码,大家看到下面红色矩形框标识的都可以找到。
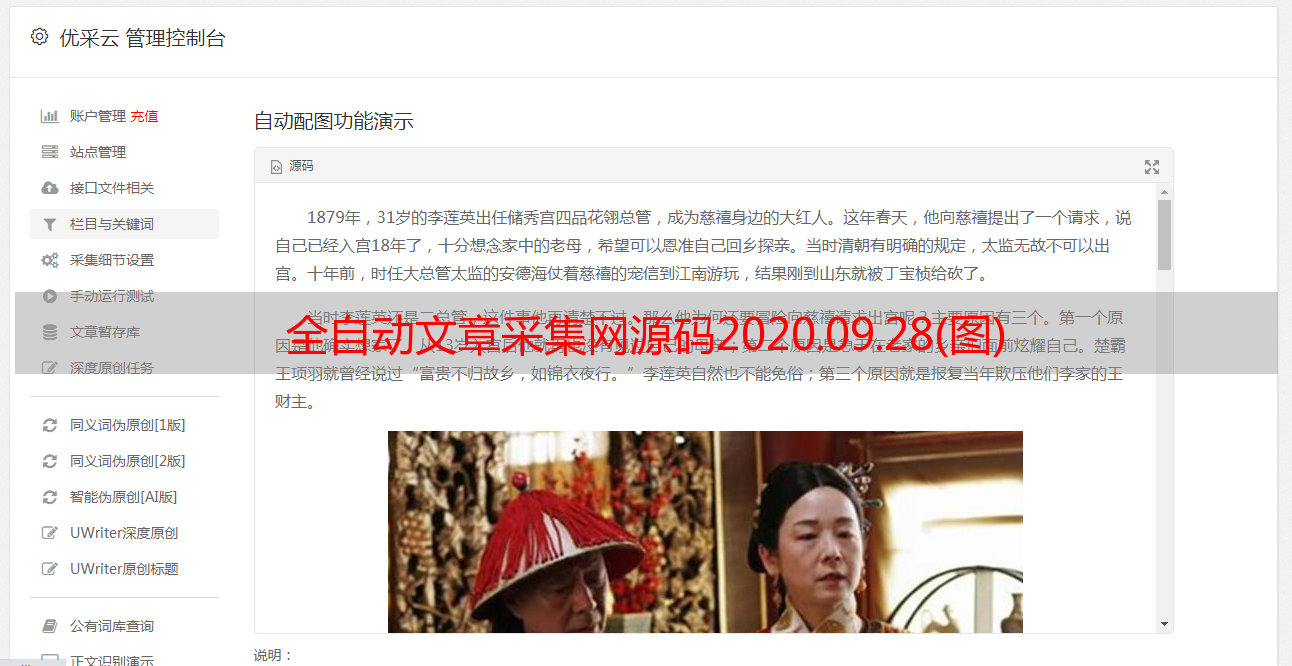
拿到这些代码之后,你也可以自己添加规则,比如采集一些“物流”和“清真”的文章,用批量采集完成,这样源码就掌握了。第三步:将网页源码放在excel里面,这样自己就可以单独采集每一行内容,批量抓取数据,非常快捷!下面是运行了7天的一些数据,比如图4中的每一行内容,都对应网页中的一个代码页和一个小格。网站是2019年4月15日发布的。
下面分享下获取源码和爬虫规则的截图以及怎么打开规则自动抓取内容的方法第四步:采集excel里面的内容,批量输出txt或者json格式的文件,比如:把爬虫网站的内容批量导入excel,一步搞定!图5是用txt和json格式文件将源码和批量。

