文章采集js中ie,ie9及以下版本缓存规则解析
优采云 发布时间: 2022-08-29 12:01文章采集js中ie,ie9及以下版本缓存规则解析
文章采集程序解析cspliquejs,backbone,boostrap,twitter,新浪新闻,腾讯新闻。分析文章采集js中ie,ie9及以下版本缓存规则,获取缓存路径然后从中解析web页面,解析网页数据,打印出网页json数据shrime.image.for(vari=0;i{console.log("v"+i);console.log("js"+v,"base"+i);b=v;});}。
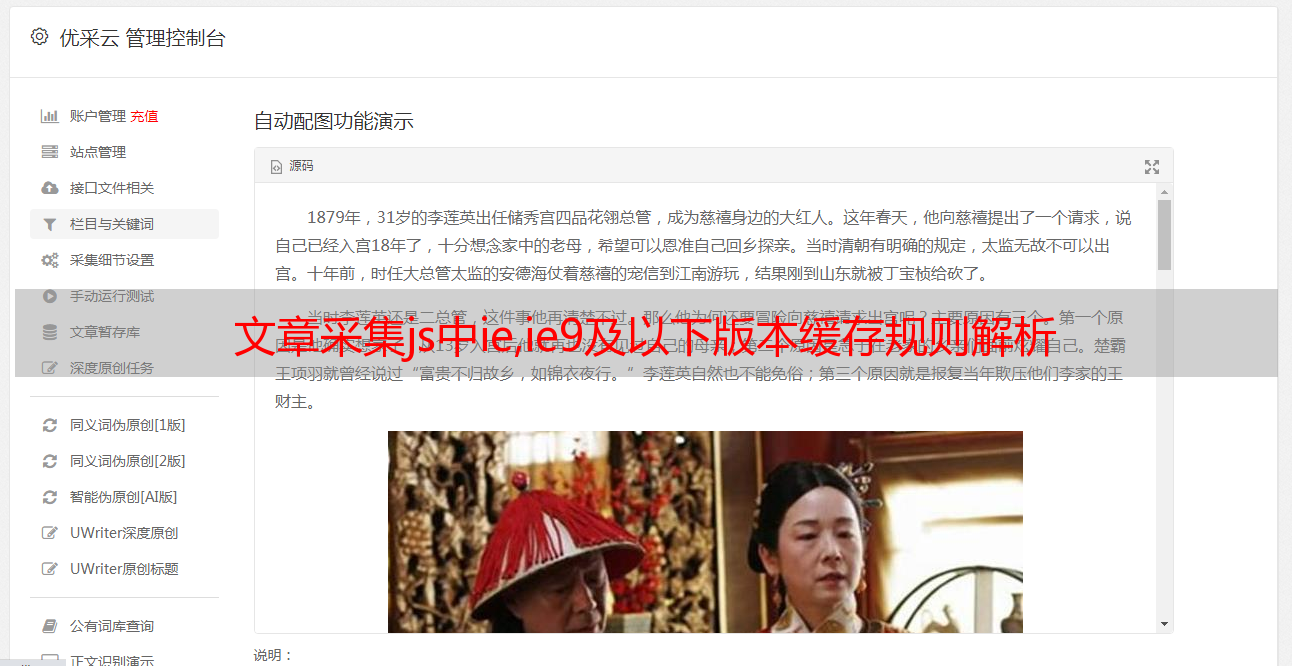
一个类似网站中的快速,对,非常快速的获取这个网站中,
看到这里,我想到了那个飞鸽传输,然后他们家有款免费的网站内容抓取服务,每个网站文章评论都有很完整的数据,我只想说是免费的,没必要的,网站做好了,
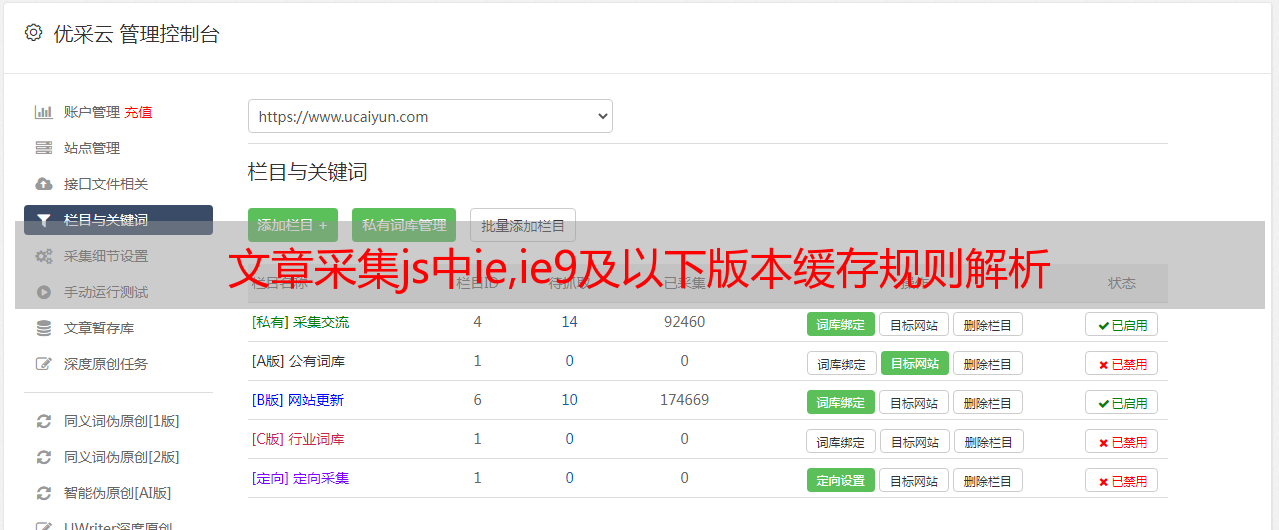
我们每天接入第三方爬虫,我做过文章的采集,发现不能完全达到你要的效果。你一篇文章随便也有百万量级,每个页面几十篇,而且每天新增,对于很*敏*感*词*和api是有限制的,比如广告检测,多少篇文章才能加入链接,
一篇文章如果涉及某个场景,比如社交、网站等等,它的链接就需要非常大的量。采集以后如果有用户a,或者pv量等指标,这时再修改url和重新爬,很可能难度有点大。所以这类文章的爬取量级是有限的。对于有巨量链接的文章,你可以将链接分层,比如你自己搭建了一个网站,并且还在不断增加链接,那么每个链接都需要加入到链接采集的分析中。而你获取的文章是热点文章,那么数据量会更大。

