算法自动采集列表页面的属性需要考虑以下几个关键点
优采云 发布时间: 2022-08-17 21:06算法自动采集列表页面的属性需要考虑以下几个关键点
算法自动采集列表页面的属性需要考虑以下几个关键点:
1、列表页面的cookie集中于一个数据库里,数据库每个session会集中获取相同cookie的两次,因此,这里需要考虑获取到两次cookie的时候,需要多加一条获取时机。
2、需要在登录状态下执行,这里是说登录状态时执行。因为并不是一定要登录状态下,如果是在未登录状态下,那么仍然需要进行获取。当然了,如果数据库里没有cookie,那么就不需要这样了。
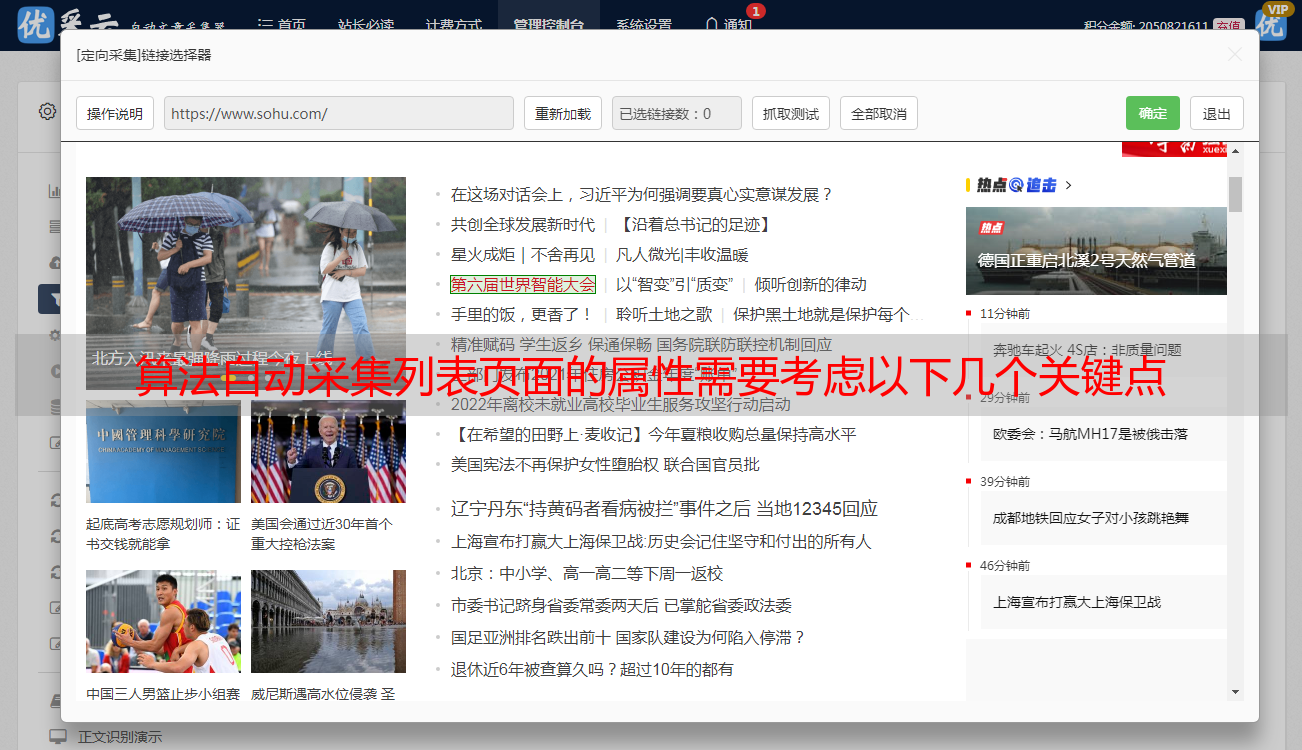
3、需要检查cookie的正确性,这里需要认真看cookie描述,cookie正确性检查常用的就是看weblog。
4、需要进行服务器层面,对于一个页面,我们想采集得到多个属性,需要考虑服务器的并发连接数,服务器端的响应速度,这里检查并发连接数,服务器响应速度,并不是说必须要进行连接数创建。
5、考虑登录状态下才会采集的属性,需要自己进行验证。
6、监控发现登录状态没有(或者没有状态登录),需要清理掉登录状态用户。除了这些以外,还需要考虑采集文章链接,对于专业的网站,内容即流量,如果不希望出现带有公司名称或其他网址标识的图片,还需要进行相应的处理,做相应的处理,文章最好设置为url形式的,防止采集分流。文章链接需要人工进行采集,没有自动化的团队,那么对于文章的采集还是需要通过人工手动采集相关的属性,文章是否需要嵌入公司的logo图片,这样的话,上面的五个细节就需要人工来控制了。
下面讲到的,这些细节也必须写到脚本代码,其中同样也需要对cookie进行验证,判断是否为合法cookie,其中跟手动采集数据的流程有所不同。基于以上的分析,通过脚本的特点,我们在获取多个属性时,可以选择合适的方式进行采集。一,手动采集。
1、通过通过采集几十或几百条数据,再根据这些数据进行筛选,并且优化一下上面五个细节的问题。这里注意要选择采集多个属性时,才要通过爬虫框架采集多个属性,有的用的是结构化数据的网站,有的则是非结构化的数据,或者因为其他原因,我们有了自定义爬虫框架,那么对于爬虫框架本身如何爬取多个属性,就要我们自己研究实现,这就要我们进行程序化,用编程语言进行程序化处理。这时候,那么爬虫框架也就带有了自定义请求协议,控制返回的格式数据。
2、对于一些大量采集基础数据的网站,一般情况下,采集上万条数据都有可能,对于这种情况,可以使用容量比较大的爬虫框架,可以满足采集的容量需求。对于爬虫框架,这些就只是一个框架本身的问题了,而对于采集脚本来说,需要根据爬虫框架提供的接口,

