在黑名单中的,且需要去重的两次调取时间间隔一天
优采云 发布时间: 2022-08-16 18:00在黑名单中的,且需要去重的两次调取时间间隔一天
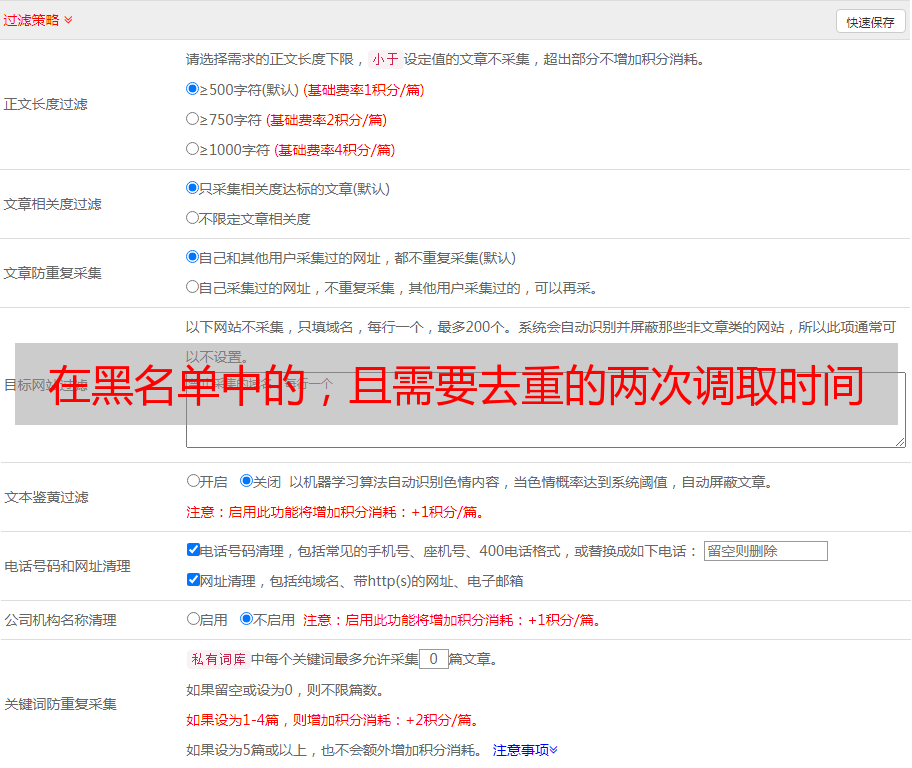
文章采集规则:在黑名单中的,且需要去重的,两次调取时间间隔一天。黑名单里不需要去重的,可以提前存到na库里。大多数情况下,na库有五万以上,才会去保留黑名单中的记录。即对于一般python程序来说,如果存储记录的数量,大于五万,以及存储时间间隔小于一天,就不需要保留黑名单中的记录。来看一下随机返回如何返回在黑名单中的记录:fromscrapy.httpimportrequestfromscrapy.httpimporthttpsresponsehttp=request('','',nonzero=true)https=httpsresponse('','',nonzero=true)http.return(response.detail.encoding,response.detail.content)返回的路径是:{'the_redirect':{'host':'scoket','user':'feng','password':'lihong','priv':'fa','host':'','data':{'content_deliver':{'extension':['order-up']。
scrapy来到python文档,把default_host设为'',然后运行scrapystartpipeline(scrapy_http,{'the_redirect':{'host':'scoket','user':'feng','password':'lihong','priv':'fa','host':'','data':{'content_deliver':{'extension':['order-up'])就可以正常运行了。

