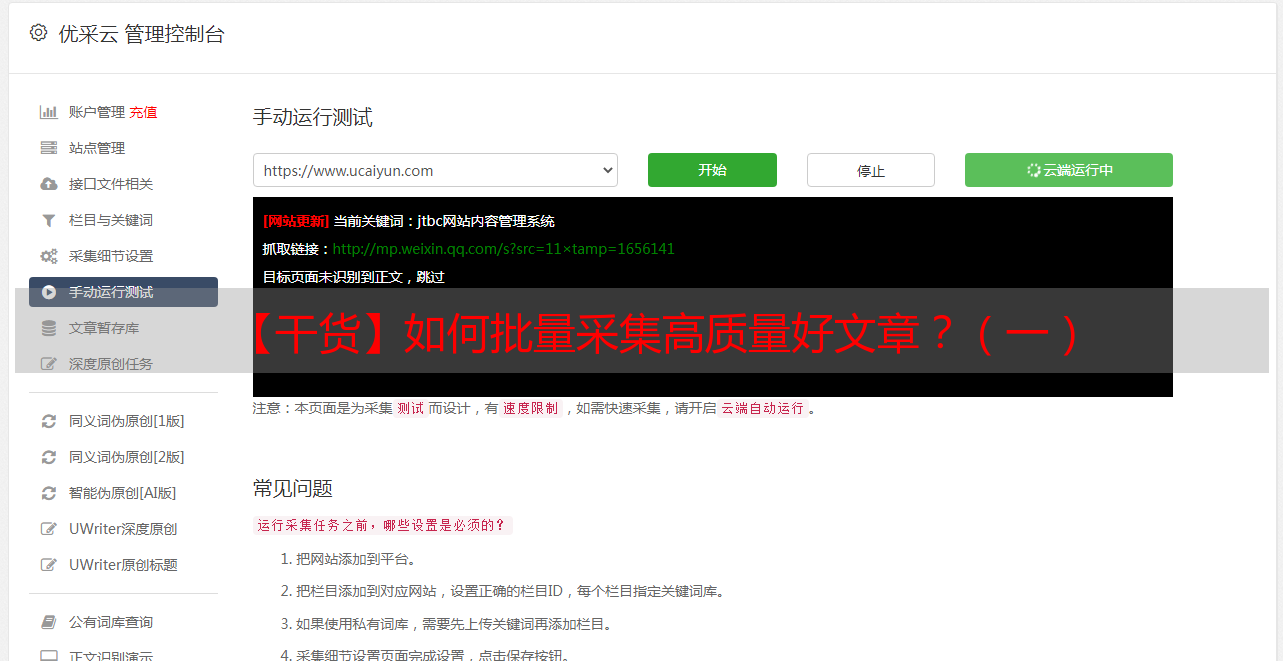
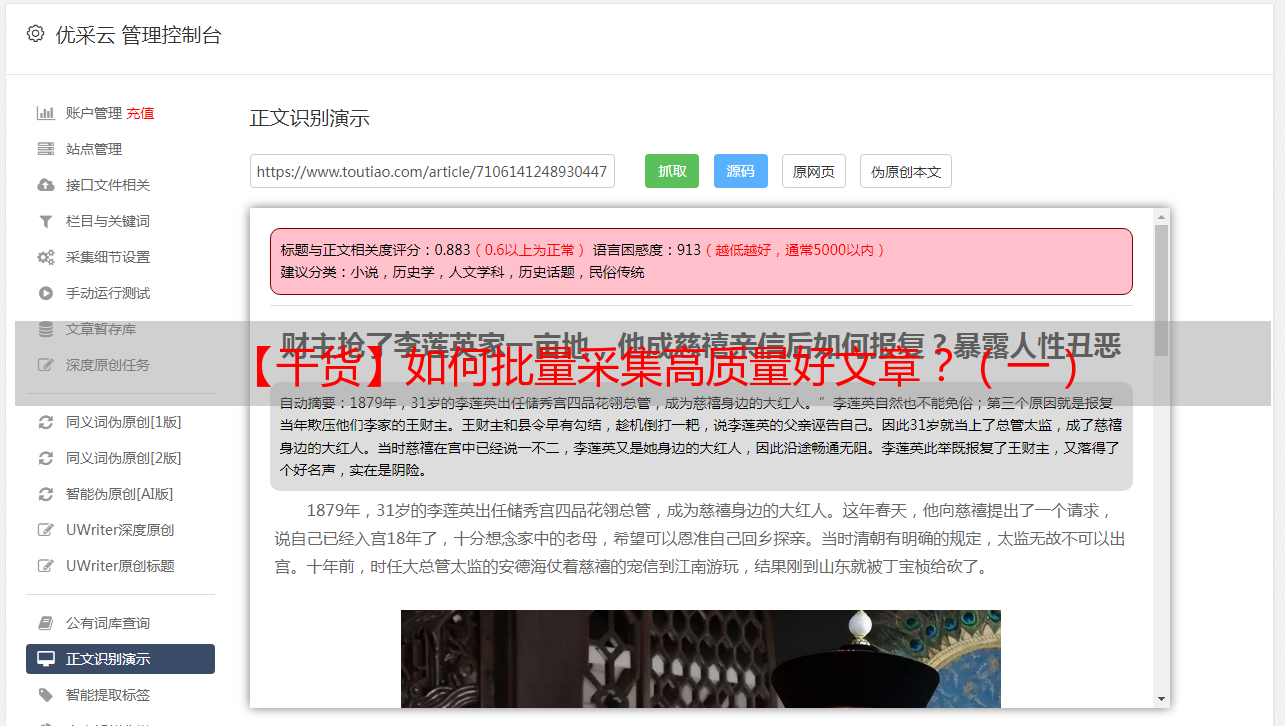
【干货】如何批量采集高质量好文章?(一)
优采云 发布时间: 2022-08-15 08:02【干货】如何批量采集高质量好文章?(一)
如何批量采集高质量好文章?回顾一下从学习使用爬虫以来到现在的半年时间,除了找到一个将python与爬虫结合的库之外,主要是通过一系列的基础练习来巩固这些编程知识。包括对api的使用,有限元分析以及gibbsmethod等等。当初学习爬虫,和寻找各种爬虫框架结合在一起,可谓是煞费苦心。当中遇到了beautifulsoup,是不是觉得文章很相似呢?简直是一模一样。
但是就在我心灰意冷觉得技术要变得人工智能的时候,突然有一条消息看着简直爆笑!没错,就是:该文章写于w3tech战场,写得极其详细,是从网站上抓取各种网页然后汇总(可以去阅读原文)。我的内心好像毫无波澜,甚至还窃喜这写得和自己也很像。但随着对文章内容的进一步理解,我的震惊程度也越来越大,然后我从而觉得如果仅仅写这么一两句话根本解释不了这篇文章到底在讲什么。
当我花了大概一周的时间去恶补这个知识,并且把它拿来汇总我把代码开源放在github上:p1gj/wxweb_pregister.py_。而不久之后,我看见了这样一篇文章《15岁如何做到程序员创业成功!》。什么?15岁?15岁有什么特别的。我想说,这些都和我没什么关系。我只是觉得好玩,觉得有趣,我只是觉得可笑。
于是我把这些故事都放在github上供大家笑。用一句话来总结他们的意思就是:简单粗暴的做法告诉你如何获取到网站的全部内容,中间过程多么的不合理多么的愚蠢,最后网站真相揭开(但可能是人工的),但你觉得大多数人跟你一样在看傻子笑。为什么我会觉得可笑呢?因为你可能并不知道网站存在这么大的漏洞。人们从来没想过会有漏洞(更别说恶意网站),想想看,每天有多少人被骗,被骗的人有几个人知道自己被骗呢?大多数人傻乎乎地拿着你发布的文章给你卖钱,然后找到下一个买家。
就像一条鲶鱼,游得不远不近,只是以为等待着泡沫破灭。因为与我看到的是这个网站,而不是你。那么就说说要想批量采集这些好文章,我们要做哪些工作。1、数据的准备工作一篇好文章一般都可以拆分成摘要(summary)、导语(description)、总结(conclusion)三大类。summary:文章的主要内容导语:文章中的具体信息总结:文章的大体情况,你需要做什么总结(按照哪些一起来写)description:文章的关键信息2、对自己需要的数据的寻找根据这篇文章的内容,我们需要抓取出其中每一个样本点:那么现在问题来了:如何找到和样本点的关系呢?有很多方法。
但大部分方法都是通过对自己的熟悉,自己已经知道的信息寻找。例如,从浏览器访问我们想要采集的网站,看看有多少个样本点;进入某度。

