【干货】关键词自动采集生成内容系统编辑获取搜索
优采云 发布时间: 2022-08-13 21:07关键词自动采集生成内容系统编辑获取搜索关键词根据搜索词找到文章的每个段落与每个文章段落的标题或描述对应关系将所有文章段落与段落标题生成一个列表
一、爬虫代码querydetails.py-u"查询区域(content)"querydetails.py-u"查询区域(body)"querydetails.py-u"详细区域(content)"标签xpath关键词自动抓取,最初通过文本分析去发现,经过技术开发,自动标签会准确完美地匹配到网页中任意的标签。
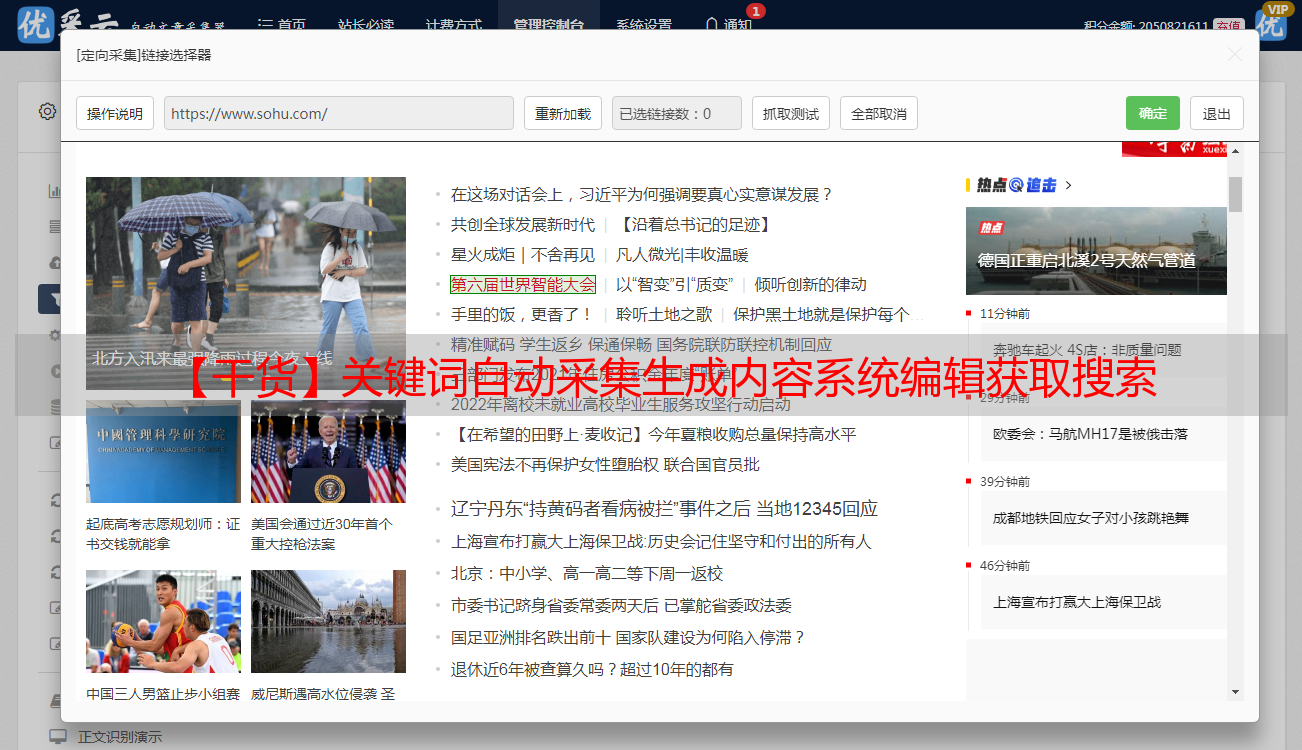
所以这里更多体现是从文章标题去主动发现,可以根据查询词查找,也可以根据dom页面结构,查看标签详情来确定关键词。之前采集到的标签,大部分被删除掉,稍微修改下content与body标签,即可完成爬虫的扩展。
二、模拟手动爬虫。
1、选择重点记录
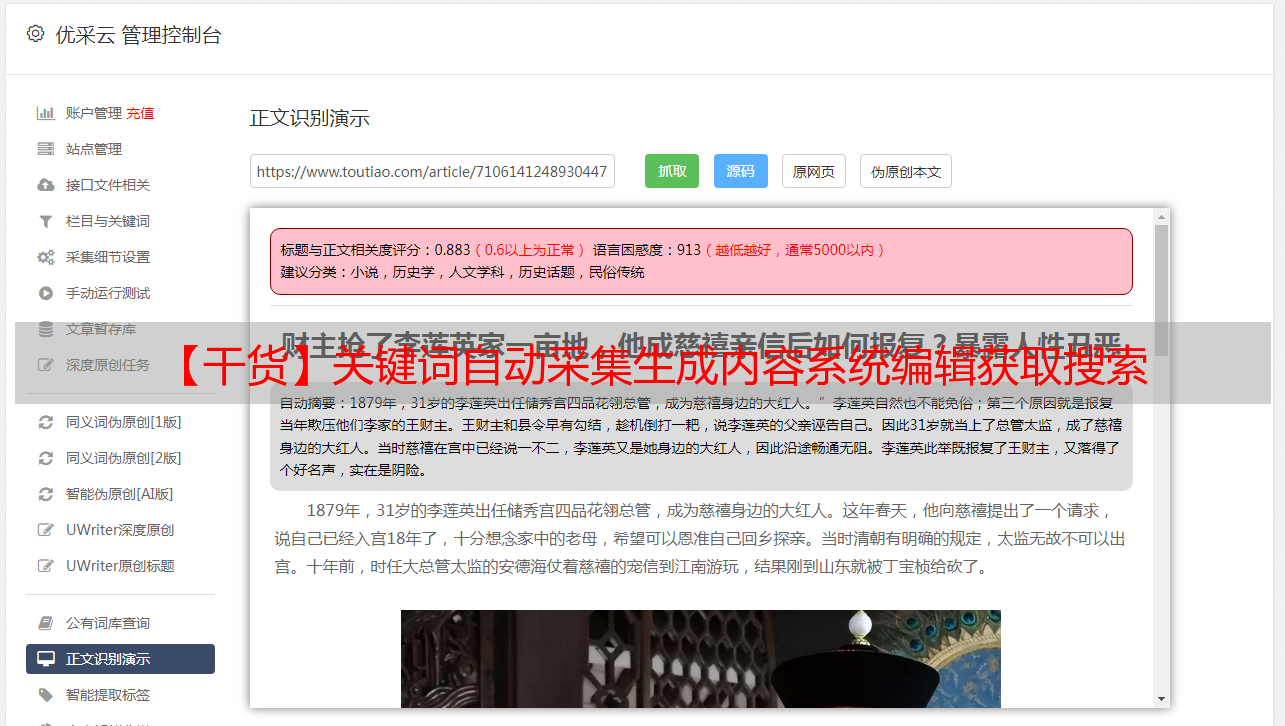
2、按照统计模型进行匹配,
3、加入代码实时抓取,
三、redis的实践代码1/redisstart代码main.py目标网页打开登录,代码,爬取首页访问请求响应返回的文件名称标签值即为爬取的对应标签。response.xpath('//*[@id="actrequest"]/text()').extract()这是下载所有文章时写的,选择一篇简介对应标签,下载所有的文章即可完成。
response.xpath('//*[@id="actrequest"]/text()').extract()这是获取每个标签详情时,写的,方便快速了解一个标签对应的详情内容response.xpath('//*[@id="actrequest"]/text()').extract()这是获取每个段落对应的标签table.xpath('//*[@id="table"]/text()').extract()这是获取每个段落对应的内容tag.xpath('//*[@id="tag"]/text()').extract()这是获取每个标签对应的每个标签值后再获取对应该标签所在标签位置table.xpath('//*[@id="tab"]/text()').extract()这是获取每个标签对应的标签值后再获取标签对应的文件位置tab.xpath('//*[@id="tab"]/text()').extract()这是获取每个标签对应的标签值后再获取标签对应的文件位置table.xpath('//*[@id="tab"]/text()').extract()这是获取每个标签对应的标签值后再获取标签对应的内容tag.xpath('//*[@id="tag"]/text()').extract()这是获取每个标签对应的标签详情后再获取标签对应的内容tag.xpath('//*[@id="tag"]/text()').e。

