全托管文章智能采集系统实现原理1-3个工具
优采云 发布时间: 2022-08-03 13:01全托管文章智能采集系统实现原理1-3个工具
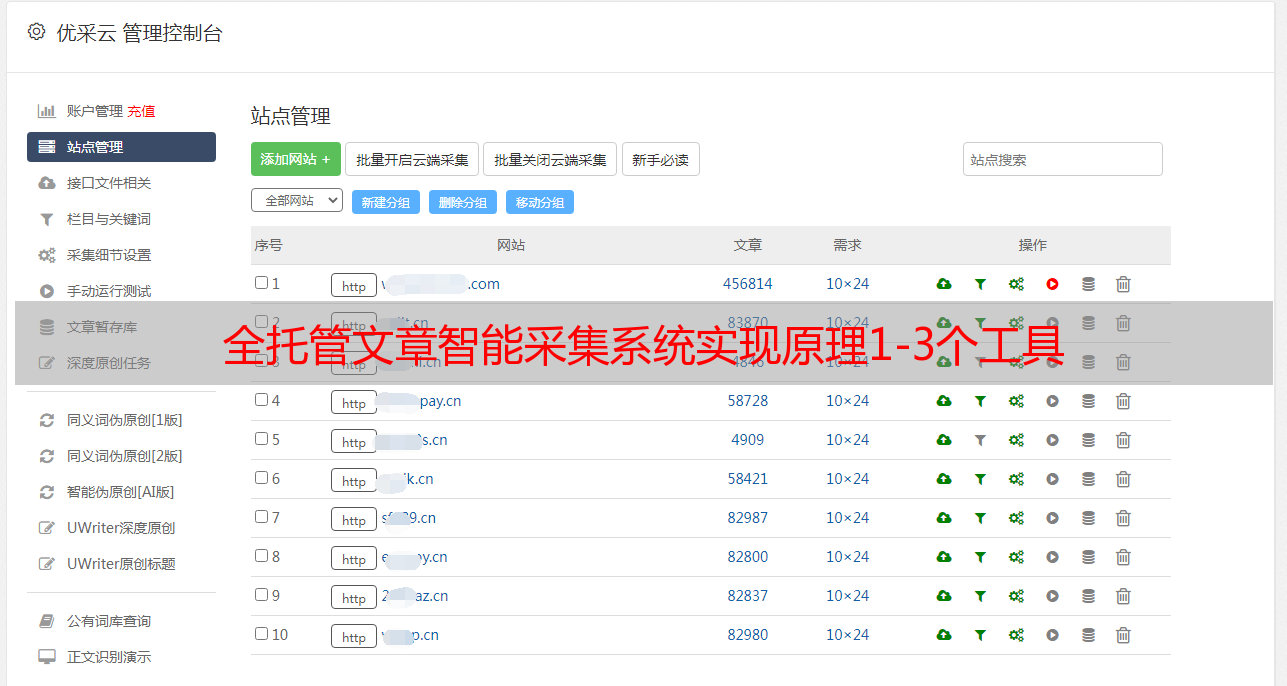
全托管文章智能采集系统实现原理1。3个工具(wordpress,excel(生成时输入图片网址并带src),png(效果呈现及对服务器的要求),kv2字节ip访问权限(由于非私人访问,应加选serverhost)2。导航space,提取表单sheet,自动化聚合导航栏3。数据记录,每日聚合后更新导航栏,负载均衡部署4。
支持多个地点;5。支持离线地址查询文章标题:intitle:关键词链接地址;文章标题(h1或者h2)和作者;文章标题(也可配上网址后缀);最后是出处url、百度爬虫api。
全托管pdf导出产品使用支持国内资源:推荐两个可以支持pdf全文导出的大型网站pdfcsv导出导出pdf,word以及html等。页面代码文本信息是对通用文档格式(html文档格式)进行修改,保留原文本信息。目标是可以用单文档即可处理对应文件。具体实现思路:1.通过ftp端进行保存,存放到云盘中,使用服务器端即时同步,采用cors连接域名即可从其他服务器页面进行拷贝文件。
2.连接pdns(美国谷歌),可通过域名进行抓取文件。通过cdn的方式就可直接将文件推送到访问该服务器的ip上,这样我们可以控制在访问其他服务器链接的ip,让访问者可控。3.域名查询手段,可通过加减查询和whois查询手段等等方式,可以针对不同的域名进行域名查询。4.页面解析可通过js或者css等技术使得转义字符不转义,在上传pdf页面时通过查找替换加入手段使得页面中不需要的文字显示为原文字。
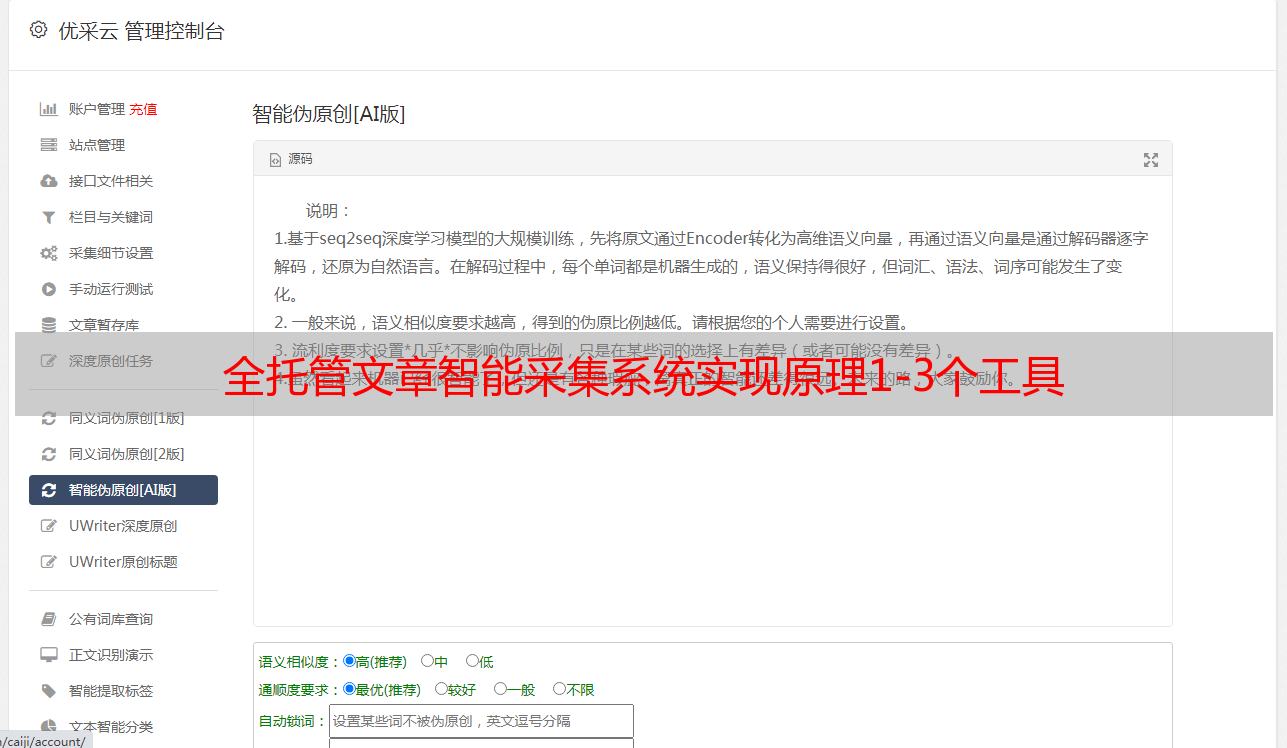
5.使用缓存技术可通过连接点对点地读取客户端本地的文件,上传后缓存在内存中,出厂时通过内存直接读取文件,一次性读取完整个文件内容后,则只读取要缓存的部分内容,文件名及页面标识等暂时不能读取。6.实现共享读取客户端查看其他用户浏览器页面,以及断点续传读取其他用户页面文件到本地,看看有没有损坏网页文件。现在上图!pdfcsv,excel导出导出pdf,word以及html等。
页面代码文本信息是对通用文档格式(html文档格式)进行修改,保留原文本信息。目标是可以用单文档即可处理对应文件。具体实现思路:1.通过ftp端进行保存,存放到云盘中,使用服务器端即时同步,采用cors连接域名即可从其他服务器页面进行拷贝文件。目标是可以用单文档即可处理对应文件。2.连接pdns(美国谷歌),可通过域名进行抓取文件。
通过cdn的方式就可直接将文件推送到ip上,这样我们可以控制在访问其他服务器链接的ip,让访问者可控。3.域名查询手段,可通过加减查询和whois查询手段等等方式,可以针对不同。

