自学爬虫过程中的想法和实践感悟-文章实时采集
优采云 发布时间: 2022-08-02 17:01自学爬虫过程中的想法和实践感悟-文章实时采集
文章实时采集:引言本项目是我最近一年多自学爬虫过程中做的读书笔记,记录下学习过程中的想法和实践感悟,借此欢迎各位一起互相交流。什么是爬虫?问了度娘,他给的定义如下:爬虫指能够自动地抓取网络信息并自动重复利用这些信息去完成某些特定任务的程序。简单地说,爬虫主要利用网络爬虫工具(如python的requests,java的scrapy,php的scrapy)来采集网站信息,然后就能做到自动重复利用这些信息,去完成一些特定的任务。
也就是说爬虫就是“接收信息-解析信息-存储信息”的一个过程。可能有人会认为,用这么复杂的程序工具,必须要有很强的编程基础,不然连自己爬取到什么信息都不知道,那还谈个毛的爬虫。但是我不这么认为,爬虫代码是我不断修改和提高工作效率的武器。从刚开始刚接触python的html来处理,然后一步步修改并不断优化,最终爬取到想要的结果。
为什么要写本文章?目前在开源的项目里面,也开始接触了一些商业项目,比如字节跳动,airbnb,今日头条,有道词典等,除了他们自身项目本身的热点产品外,社区当中也有非常多大牛参与,从程序员向产品经理,架构师到设计师等角色,在产品的各个环节均有比较深入的分享和讨论。但是有很多的项目当中,产品的规模在上万甚至上十万,几十万,开源框架和商业化产品的复杂度都很高,这些项目对于初学者来说,并不容易快速上手并进行深入分析和探讨。
所以我开始重新设计规模不大,对我个人开发来说门槛也不高的爬虫项目,比如《javascript之罗生门》这本书。在过去一年多的时间里,我在学习程序员的爬虫项目开发方法,也在github上收获了2000个star,来着已有3000人,基本每天会有1篇文章+读书笔记出来分享,也就是说我的一周更新了50篇文章,每篇文章的更新频率就是一周一篇,我希望通过这样的过程来建立我的知识体系,也希望能够分享给大家。
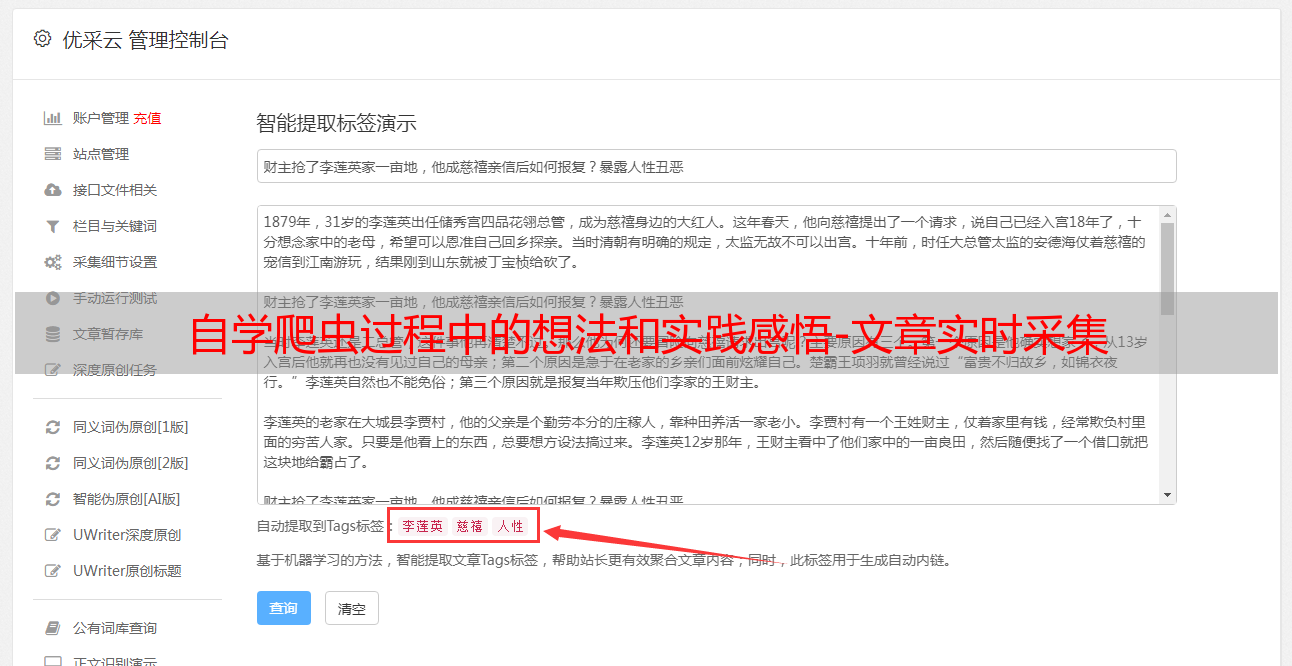
为什么要使用beautifulsoup?beautifulsoup是python中最常用,也是相对最为优秀的文档解析库,有可能是爬虫项目中最常用的框架。这个工具能提供非常快速和高效的爬取页面(尤其是模拟请求),非常方便,对于初学者的爬虫写起来会非常方便。beautifulsoup已经不只局限于html了,我们将会介绍他的其他方面使用。
我为什么要对爬虫有所了解?对于初学者来说,爬虫入门以及在中小型爬虫项目当中应用都还是比较困难的,这个主要体现在两个方面,首先在人员管理方面,如果人员交叉,沟通不畅或者是人员不足,再配合上新人培训的话,肯定是有很多问题出现,再者就是在获取数据方。

