【】自带的urllib库就是自己写的
优采云 发布时间: 2022-08-01 09:00【】自带的urllib库就是自己写的
从网页抓取视频主要分两个方面,一是通过post将音频或视频提交给某站点的expireserver处理。二是通过抓取文件的方式抓取视频流,例如xmlhttprequest。
谢邀,lz首先要定义一下你这个爬虫,是不是自己写的,或者拿别人的code改装的,
详见:javascript技术栈-4.0.3modulevideoextraction
首先lz的问题如何在一个video文件中实现抓取不同的视频,你要清楚到底是哪种方式,可以你用的一个库或者是自己手动写xml,然后用libjs,pythonbs3,xml包(ts或者beautifulsoup2),javascript,etc.这些不同的实现方式。我能够给你的办法就是安装phantomjs,然后extractxml,flask我就不知道了,不用phantomjs的话,可以考虑用一个http请求用于python。
python自带的urllib库就是,
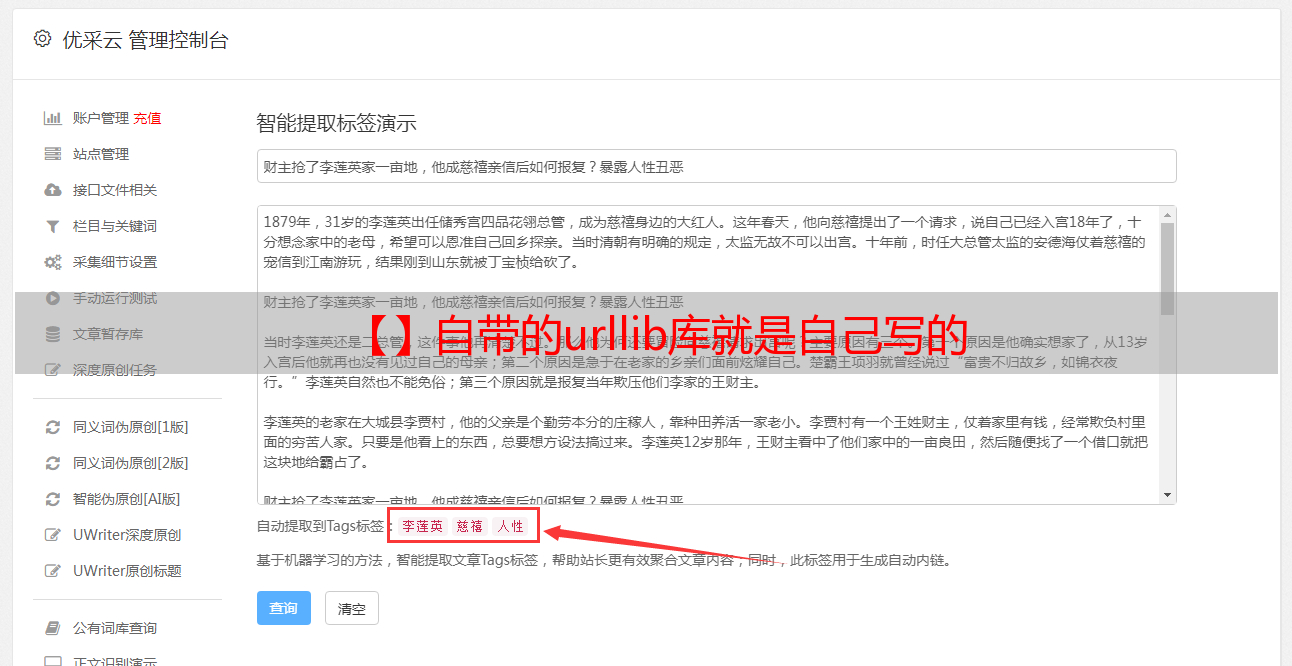
我对lz的问题描述有点糊涂,如果需要抓取的是视频,bs可以实现吧,如果是网页的格式,
好久不用python,我的直觉是lz自己写爬虫,一点一点爬吧。找一找相关网站的wiki。
这里教你一个办法,bs4就可以,
你可以自己写一个播放器,把要抓取的视频地址存储,然后一个个抓包然后写一个播放器对视频地址做遍历。这个爬虫和你自己写的比起来速度会快的很多。然后用bs4写一个播放器,抓取视频。

