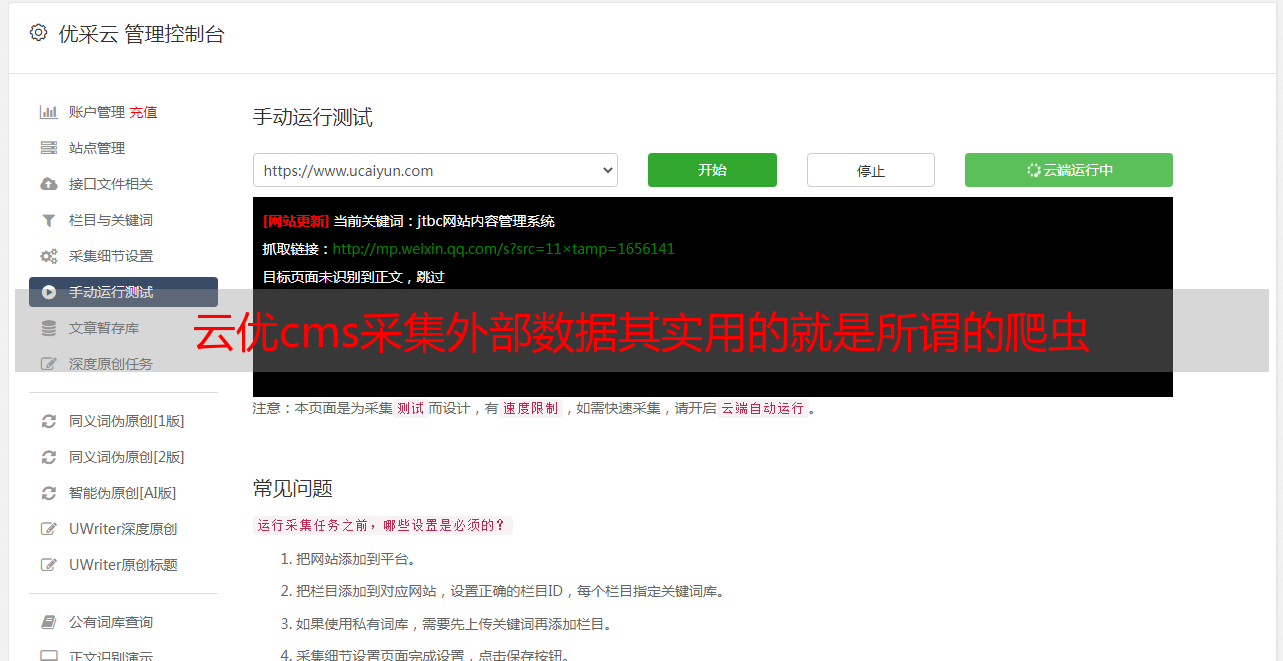
云优cms采集外部数据其实用的就是所谓的爬虫
优采云 发布时间: 2022-07-31 05:09云优cms采集外部数据其实用的就是所谓的爬虫
云优cms采集外部数据其实用的就是所谓的爬虫,
update:爬虫下面写了一个cli爬虫,限制每天随机一个固定ip,可以试一下,并可以爬下载的分享一下。/#/proxy/ch_proxy以及你可以关注下我的博客,里面有详细介绍yoyoyo的博客主页,
这是云优开源机器学习平台,基于cloudnative引擎,从数据入库、数据清洗、数据预处理、数据建模、数据展示,一步到位。你需要什么样的模型,拉什么数据,包含什么数据,可以从这里找到。这里面也有slack的场景开发,tushare数据抓取就是从这里抓的。你需要的是简单安全开源爬虫,可以参考里面的东西。机器学习已经挺成熟了,可以从配置文件中看到是从哪里过来的。比如:nmeaak.json。
爬虫的话,有现成的很多,爬虫学习可以看:requests博客,
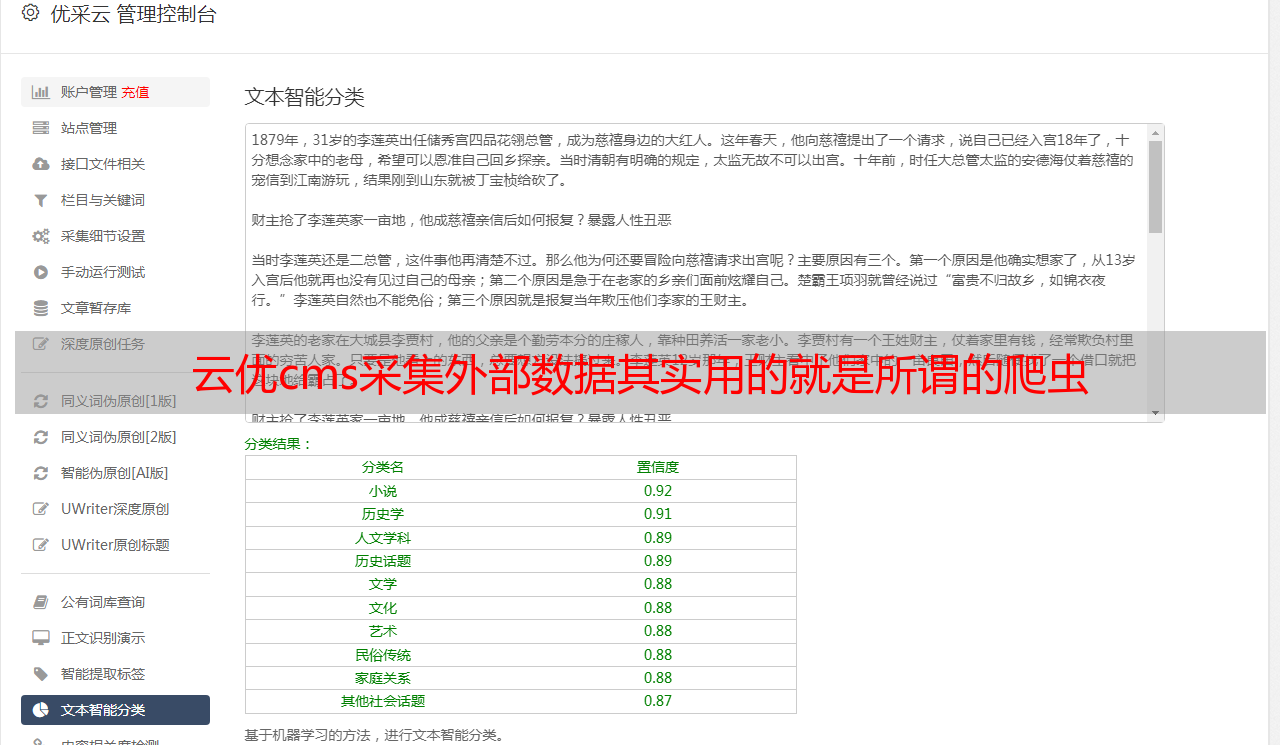
我感觉这个真的不错,不仅可以爬外链,还能抓取带电链接,
如果你需要检索多个论坛文章,并可以通过网站爬虫多次登录。是个不错的选择。
你可以试试日臻爬虫管理系统,站长免费使用中的,后台功能齐全,包括网站数据采集、网站爬虫管理、网站标题爬虫、网站文章爬虫等等各类爬虫,

