实时抓取网页数据,就像抓小偷一样的..
优采云 发布时间: 2022-07-28 20:04实时抓取网页数据,就像抓小偷一样的..
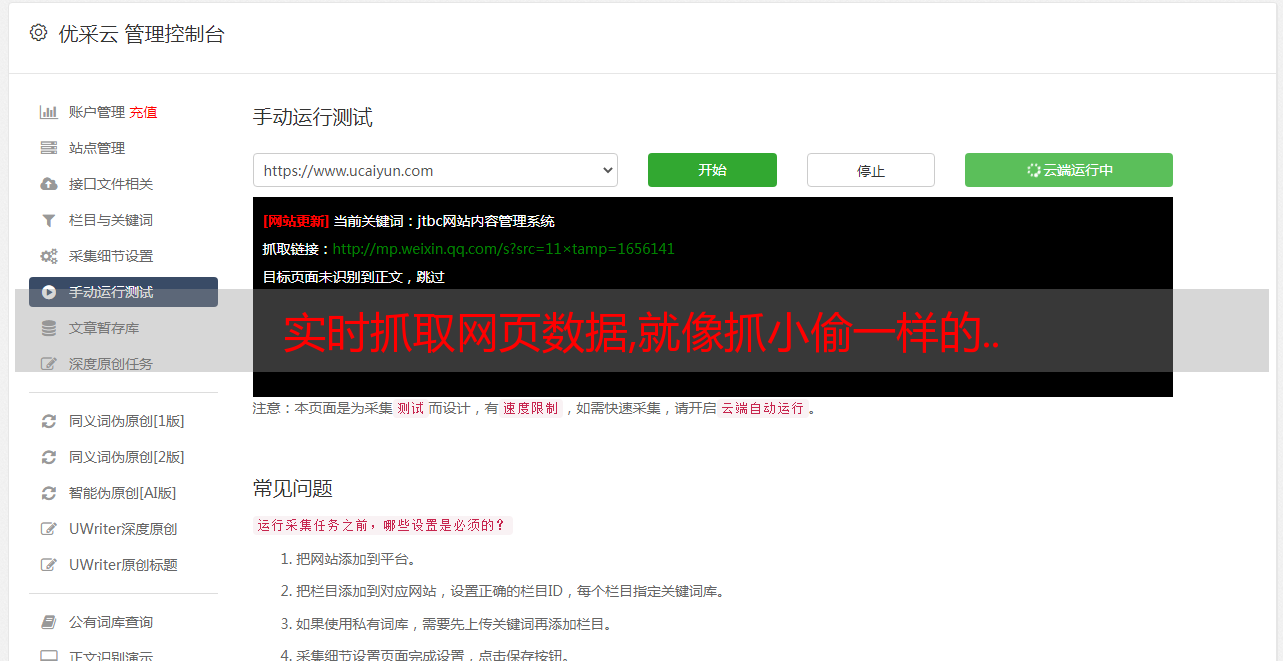
实时抓取网页数据,就像抓小偷一样...1.useragent注册(网页请求数据的标识)2.headers传递给服务器(用户端发送内容)3.dom结构树生成(浏览器发送请求)4.get请求创建dom节点(抓取网页数据)5.post请求获取数据(模拟发送请求)欢迎补充!
人工采集(关键要求:*敏*感*词*,驾照号,邮箱地址等实体信息),现在fiddler抓包功能已经非常强大,一般的爬虫应用或网页访问我觉得都可以应付。国内的话,现在的很多抓包工具对方面都有对应的提供,有数据库的sqlite.js,或网页抓包app,很多的。
楼上说的不错。现在爬虫市场上还有很多没有很好的抓包工具,之前用过一个broadcastbot。它实现了fiddler的功能,
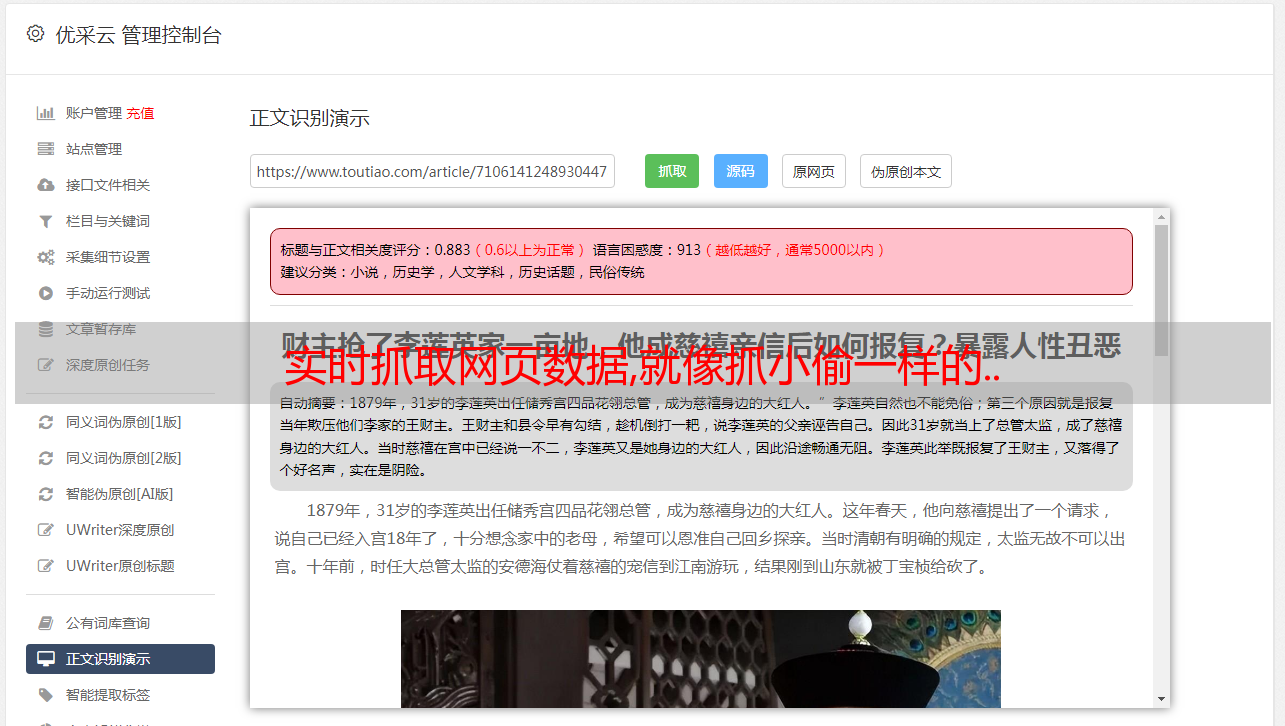
最近在写一个数据爬虫爬取网站内容加上自己的一些体会希望可以帮到你
不需要保存到数据库。抓完请求,在网页上看一下数据就知道是哪几个页面的了。
普通的网页加载速度是很快的,比较慢的有登录页,注册页等,再慢的有用户名或密码验证页面,这时抓取数据就要全部下来,分页下。如果对速度要求不高的话建议抓简单的数据,比如新闻发布会的节目单数据,再大一点就抓博客数据吧,

