《网页抓取innertext试题》之基本需要三步骤(一)
优采云 发布时间: 2022-07-23 00:02《网页抓取innertext试题》之基本需要三步骤(一)
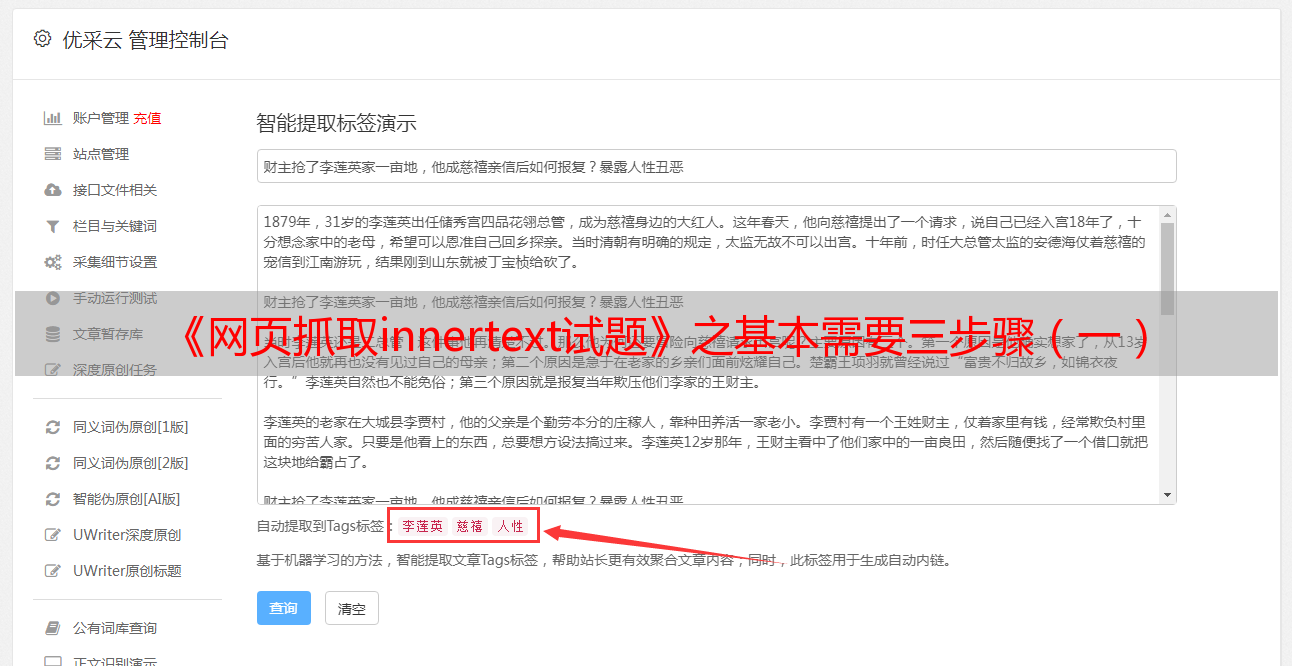
网页抓取innertext试题,基本需要三步骤。第一步可以通过解析文本包,然后直接生成html结构。其中第二步可以在第一步中对文本包进行处理,将之分割成string转换成actionid,第三步的话将actionid加入到正则表达式中。
网页抓取,几种方法。
1、爬虫:这种方法针对各种类型的网站,因为爬虫工具是针对于一些针对性的网站的,
2、类似于爬虫的抓取方法:因为你现在给定一个页面,那么可以使用类似于htmlfield的信息进行翻页抓取。
3、由于问题要抓取的页面比较多,那么可以通过抓取的方法,
/
路过这个,不邀自来。既然基本的抓取都不会,那看来是准备找一个满足lz技术要求的了。我手头的工具里没有抓取课表的功能,但有一个教师信息采集的工具可以直接抓取上课表。
谢邀,我对html没有了解过,但是对这个也还是有一点了解的,楼上几位已经说了很多可以抓取课表的方法,但是这个我估计要麻烦一点点,你们要处理很多网站才行,抓取需要处理的网站可能会超出你们的能力,并且由于时效性的问题,你们可能抓取不到,这个情况,我只能给你出几个可行的选择,一是在别的程序中抓取,可以用python.不过我了解的python不支持这种需求。
二是每次在抓取前都把时间处理好,这样每次抓取时间差可以控制在1小时以内。三是可以考虑通过一些比较高级的方法,可以自己实现一些算法,把抓取的课表填充好,可以达到类似目的,不过python的知识你要掌握好。四是通过爬虫,获取课表数据然后进行批量抓取。

