完整的采集神器教程(1)-web-app-ping9442cf5
优采云 发布时间: 2022-07-04 22:00完整的采集神器教程(1)-web-app-ping9442cf5
完整的采集神器教程:
1)下载工具:mozillafirefox
2)
3)
4)-web-app-ping9442cf
5)
6)抓取json字符串、bean等
7)
8)抓取class文件
9)(1
0)获取微信指定文件的路径和扩展名(1
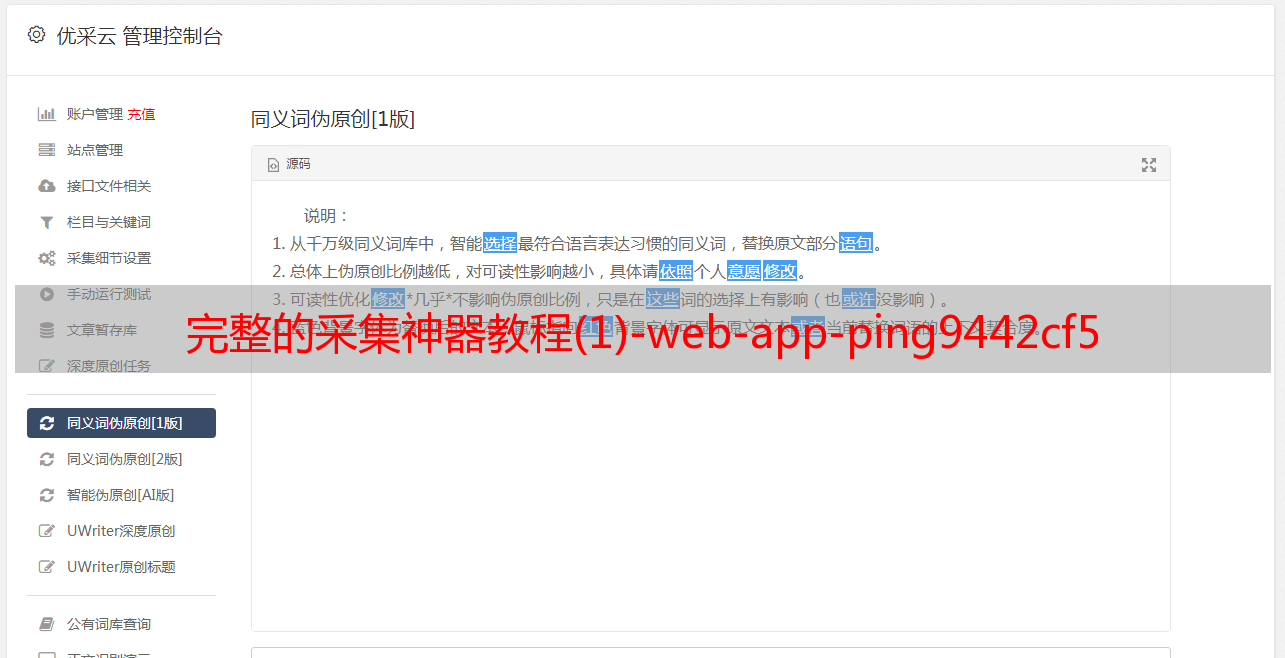
1)iexploreroll.js1.下载工具打开腾讯网站,输入网址,点击打开。注意:同一个网站,不同页面的表现可能不一样,此时请注意点击右上角的“三”点,进行修改后再尝试打开。2.工具说明①mozillafirefox是一款firefox插件,可以抓取所有的网站内容。它可以抓取除百度和谷歌之外的网站的内容,无需跳转。
1)抓取json字符串、bean等。
2)抓取class文件。
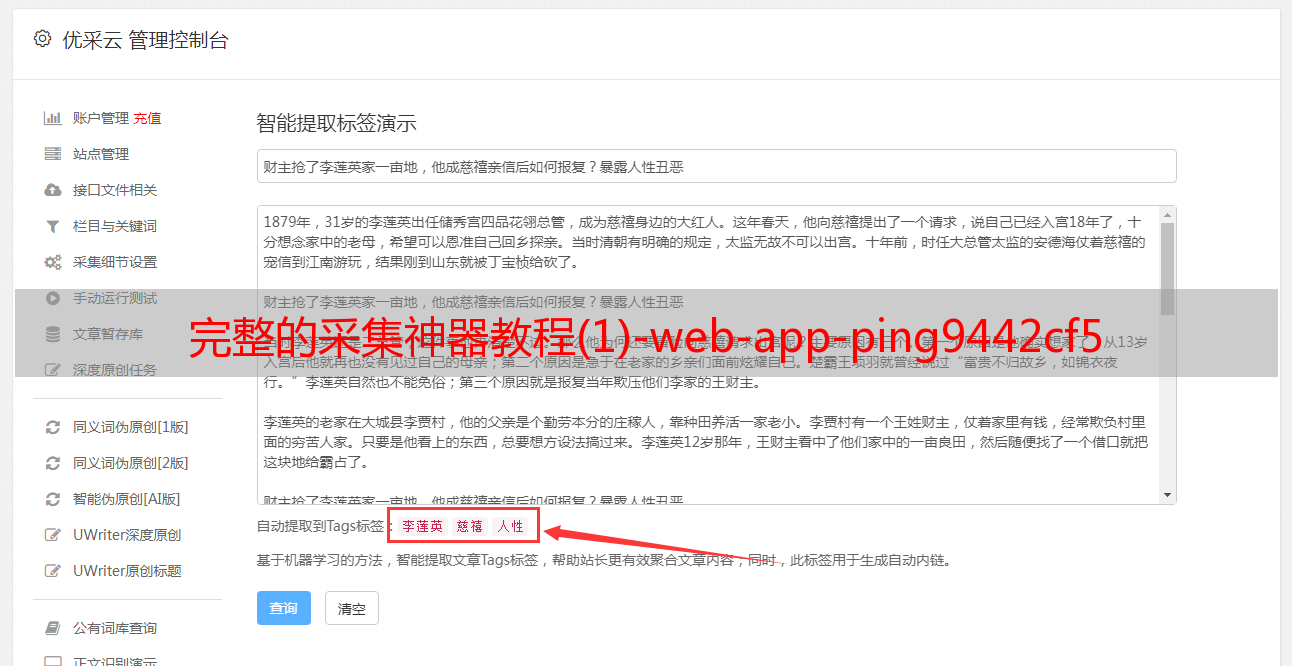
3)抓取微信指定文件的路径和扩展名。3.点击右上角的三使用命令管理它。
如图所示:④cmgryloader.exe3.修改代码,
1)iexploreroll.js我们先用python语言下载网站内容,再使用python抓取,如果代码书写过于简洁,可以输入requests库使用inspect库解析,使用cssx.select=cssx.select_offset选择下载的内容。同时需要写上刚才的iexploreroll.js文件。
修改完代码后,并调整一下部署配置,给代码的生存环境命名为“thecrawler.js”,这个文件被称作“网站后端管理服务器”,别问我叫什么。
importrequestsimportpymongoimportjsonfromurllib。parseimportquotefromurllib。parseimportrequestsimportreimportrandomimporttime#firefox扩展中心安装程序requests,json,pymongoimporturllibimporttimedefdownload_site(url):"""下载网站数据"""url_list=[]json=json。
loads(url_list)。decode('utf-8')ifnotos。path。exists(url_list):print"下载成功",""else:print"failed:",""req=requests。get(url_list)url_origin_path=req。urlopen(url_origin_path)print"下载成功",""else:print"failed:",""req。
read()json。extract(json。decode('utf-8'))time。sleep(100。
0)withopen("./js/0.3.0.js","wb")asf:f.write(json.decode('utf-8'))#windows下扩展程序安装程序安装和配置#我这里安装了firefox插件iexploreroll#在ie的选项-管理工具-查看配置...中添加一个json.serialize方法,后台*敏*感*词*下载链接#ie扩展这里则是*敏*感*词*thunder插件的firefox插件。然后手动添加pip安装程。

