c爬虫抓取网页数据更新的步骤是什么?怎么做
优采云 发布时间: 2022-06-29 07:02c爬虫抓取网页数据更新的步骤是什么?怎么做
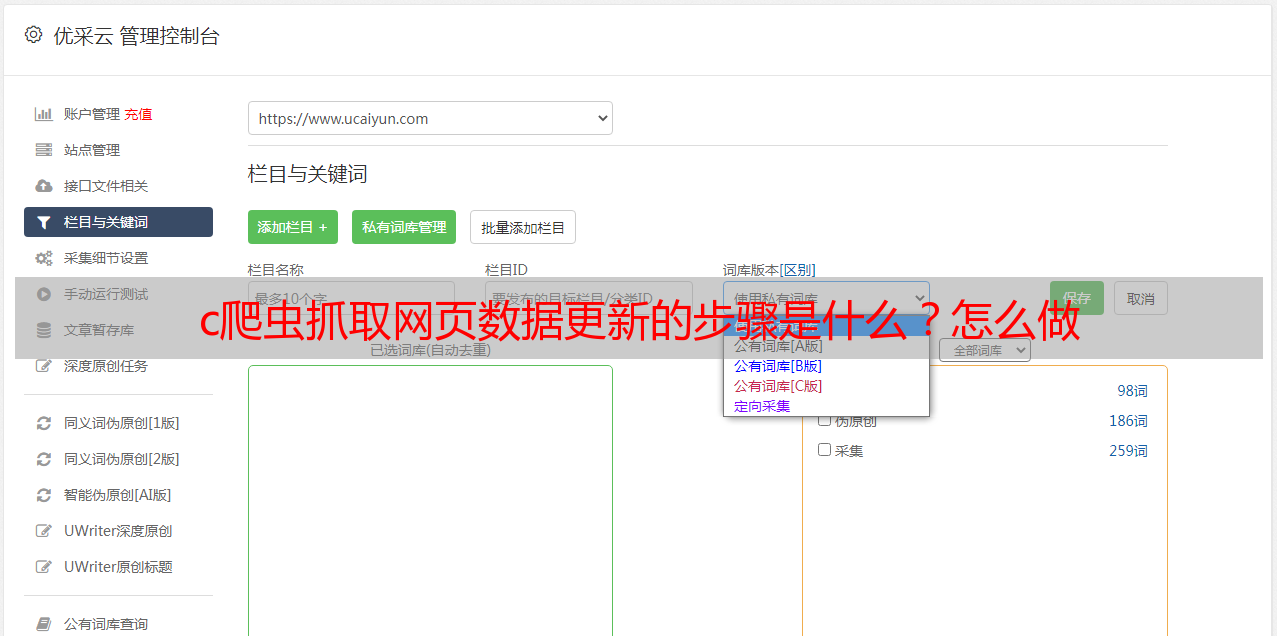
c爬虫抓取网页数据更新的步骤:1.首先是获取目标网页的数据的方法,即获取这个网页所需要的数据。2.再是打包成数据包,下载到本地。然后对下载下来的数据做分析计算。有了本地的数据包,才能通过脚本更新网页。3.网页的更新即是用人工手动的方式取得网页最新的数据。这个过程需要使用抓包工具。4.http请求的代码以https格式写在代码最后。5.有人会问,这个代码在哪里?运行代码的时候,会用到浏览器开发者工具。
做爬虫的时候经常会用到一些爬虫工具,
可以使用多线程抓取,
我个人认为,
有个叫说手机app的那哥们,整天干这个。
曾经做过一段android全开源爬虫,可以爬lbs相关,更新比较及时,速度可以达到1000+,现在想想那是多年前的事了。
如果只爬公开数据(包括大数据),可以通过反爬虫机制。在androidapi409范围之内,比如:大商家之间的投票、大的赛事、大型论坛。在recaptcha加密机制之内,拿到中间地址。然后:翻墙找数据。(外国网站监控比较牛逼)在上一条的基础上,自己编写getheader或者cookie对爬虫,这个可以crawl,不过有点坑。
在自己程序中使用第三方爬虫,会和代理广告相关,自己肯定清楚相关的东西。或者agentdetector来监控哪个浏览器加速。有实力做爬虫网站比如一些专门做分析数据爬虫之类的东西,就是收费的东西,多爬一些数据吧。

