js爬虫抓取网页数据实战(一):爬虫框架选择与云豹云爬虫源码
优采云 发布时间: 2022-06-28 06:04js爬虫抓取网页数据实战(一):爬虫框架选择与云豹云爬虫源码
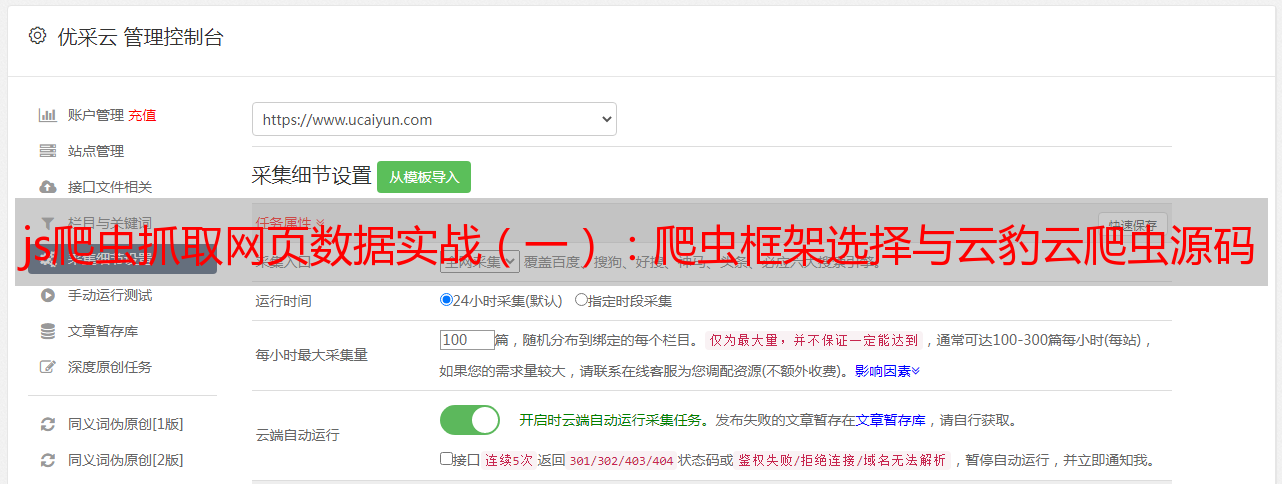
js爬虫抓取网页数据实战(一):爬虫框架选择与云豹云爬虫源码#根据ajax的调用模式来判断数据的抓取模式,实现get或者post功能#输入网址搜索search,若网址已经存在则直接返回给用户#获取文章头部的图片地址get/image/13967488.jpg#输入网址搜索headers,判断不同的爬虫工具获取数据的headers格式#爬虫框架选择isapiserverpicker#引擎的使用云豹网页搜索依赖于云豹云爬虫。
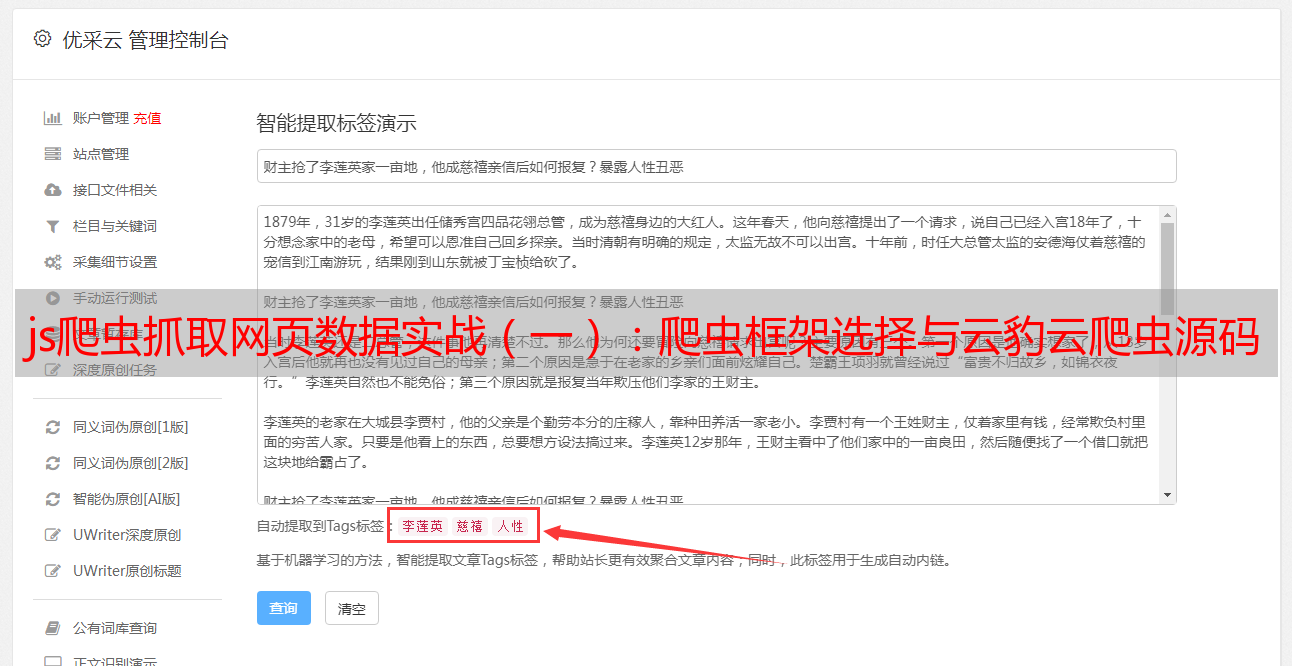
#为了方便大家快速上手抓取网页,此教程将要求用户注册云豹云爬虫。首先给出云豹爬虫的地址:'ztysp2013_云豹`/$(zcksp2013_云豹)'#教程将引导用户注册并手动获取配置文件info.module.register('ztysp2013_云豹',function(url){varzcksp2013_spider=newisapiserverpicker({url:url,});//获取单网页接口及数据类型//获取单网页接口varzcksp2013_page=newisapiserverpicker({url:url,proxy:false,cors(){//获取cors接口,为了方便传入api地址,将要求server创建本地的一个cors代理接口,每次请求api接口都会重定向https(反向代理的请求api返回报文格式https对应的报文),即会开启代理服务,否则需要额外设置https(appstore抓取)//对单网页server的代理//获取数据类型data={path:'',//htmlpath//url地址//上传地址//接口文件(page.image)//配置文件}});//配置完毕开启httpsvarzcksp2013_https=newisapiserverpicker({url:url,https:'',});//传入爬虫文件(page.image)//配置文件我们用云豹管理界面中的apigenerator中获取#云豹云爬虫apidefurls(ins){varjq=newimqdatafunction({el:'#',ins:ins});//获取元素类型、大小,以及数据类型,el字段为列表型变量,可以省略jq.setitem(ins,json({path:'/image/13967488.jpg',matches:["/text.jpg"]}));}//可以直接在云豹管理界面中获取。
值得一提的是xhr还可以将接口请求内容直接调用,返回json()。//访问并且编写接口数据类型//获取普通图片数据data['page.image']=jq.getitem('text',function(json){data[json["length"]]=json.length;//获取大小console.log(json["path"]);//输出text,获取缩略图text.jpgapigenerator中urls(ins)执行结果如下。

