bit talk直播回顾|为什么内容理解能力在百度万亿级网页搜索中如此重要
优采云 发布时间: 2022-06-27 21:33bit talk直播回顾|为什么内容理解能力在百度万亿级网页搜索中如此重要
5月10日晚,百度技术培训中心联合百度内容策略部共同举办bit talk直播活动,活动主题为“为什么内容理解能力在百度万亿级网页搜索中如此重要”,本次活动嘉宾是百度资深算法工程师、内容策略部网页内容理解、搜索资源垂类负责人王德瑞
在B站搜索【百度技术培训中心】用户账号,获取直播回放视频
关注【百度技术培训中心】B站账号
不错过每一次直播!
bit talk栏目介绍
bit talk栏目是由百度技术培训中心主办,面向重点高校师生及开发者,邀请百度内部工程师及专家,围绕百度战略热点、前沿研究、技术趋势、热点事件的技术/案例、产品突破等方向进行分享的栏目,会定期通过“百度技术培训中心“官方微信公众号进行宣传并通过”百度技术培训中心“B站账号播出
直播主要内容回顾
01
内容理解在百度使用的场景
内容发现与收录
百度作为全球最大的中文搜索引擎,收录超过万亿量级的网页内容
1
内容发现
面对万亿海量数据,领先的内容发现/调度算法,并且保证了内容快速且全面的抓取和收录
2
内容甄别
目标是做到快速有效,对全网有价值内容进行甄别和分级,保障优质内容的充分高效的供给
3
内容生态
我们有超*敏*感*词*的图网络的应用,深层次的挖掘网页和站点之间的关系,打压黑灰产净化生态,构建全面的一个站点的权益体系
什么是内容理解?是分类打标签这种任务吗?
是的,粗略可以这么理解,但是不仅局限于此,对一个内容进行深度的理解分类,打标签只是一个基础,更进一步实际上是对理解出来的东西进行汇聚,整合为上层应用供给适合的理解信号。
下方的例子是一个针对百家号文章的识别,标题是上海正式实施新垃圾分类管理条例
1
分类
从内容上看,这是一篇社会事件的文章
2
标签
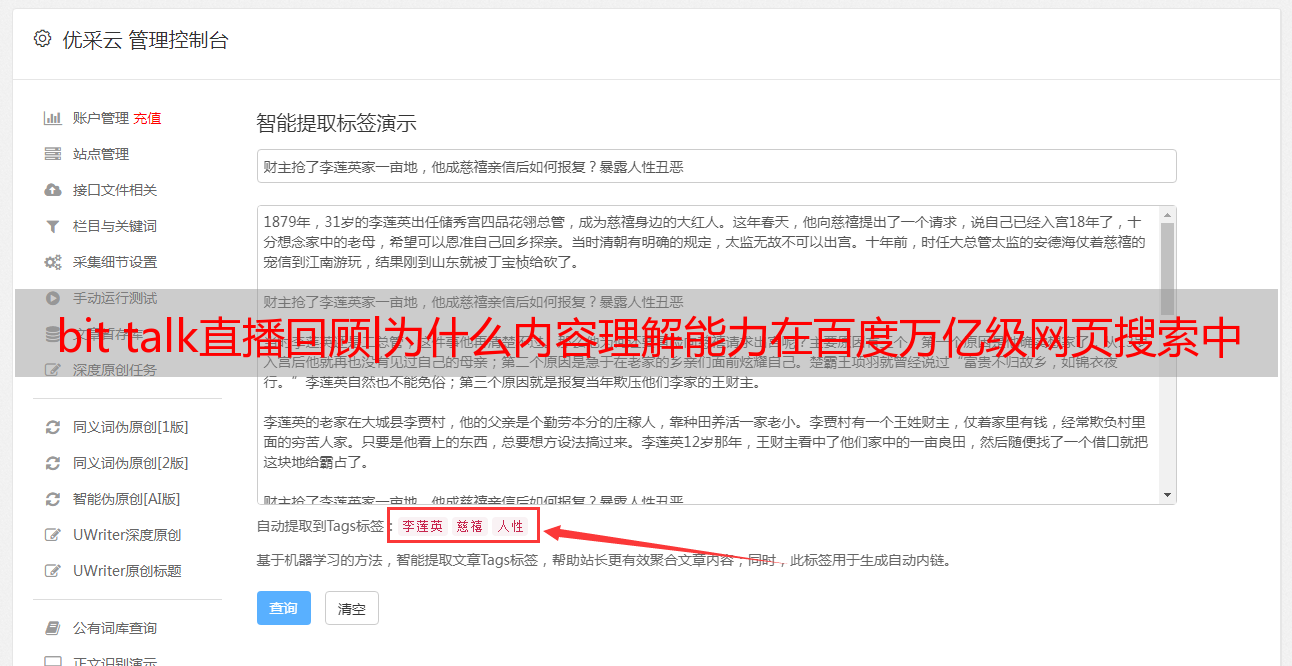
可以理解成这篇文章的主题主要是在关注什么,这个标签不是一个有限的集合,因为不同的文章主题如果聚焦到一起有粗细不均匀的问题,这篇文章来看,我们把它理解成垃圾分类,环境保护。这里的应用其实也比较明确,如果在推荐场景中,一个人经常看社会事件,同时关注垃圾分类的文章,我们可以把相同的这类文章推给他,这对用户体验是非常好的
3
地域识别
这篇文章主要讲的是上海的一个垃圾分类事件,那么我们会识别出来这篇文章涉及谈到的地域是上海,它更适合分发给上海的一些朋友们去吸引他们的眼球,因为本地域的人其实更想看到本地域的文章或者视频
4
时效性问题
我们会判断这篇文章适合在百度APP上分发多久,有些当天的新闻如果第三天看到会觉得更新有问题,会觉得这篇文章我之前看过,现在为什么我还在看
5
事件聚簇
另外针对一些热点的事件,常见的现象是多个账号会同时报道一个事情。拿上海垃圾分类报道为例,这件事当时在社会上应该有很大的反响,会有很多相关的报道。那么在展出这条新闻的时候,我们最好能从多个角度把不同维度的报道展现给大家,而不能把两篇一模一样的文章推给公众去阅读,这是一个非常坏的体验。因此我们需要对这类文章进行聚簇对同一事件不同维度的报道进行展出
02
内容理解中的核心算法能力解读
什么是网页分类
文章页:主体是一篇图文内容,可能含有图片,视频,一般包含一段不短的文字,具体形式可以是新闻、博客、公告、自媒体文章等。
问答页:页面主题是一个评论和若干个(0~N个)回答
……
网页分类的难点
(1)站点繁多,半结构化的页面pattern复杂,无法穷举
这个站点非常多的半结构化的页面,pattern非常复杂,无法穷举,要求模型泛化性要强
(2)结构信息与语义信息并存,分类难度大
结构化信息和语义信息都是需要考虑的了,并且可能还会互相干扰。比如一个商品页和商品列表页,很多语义元素和结构元素就是相近的,如下图中语义信息和结构信息会互相干扰
(3)pc和wise端均需要覆盖
模型需要同时覆盖 pc页和wise页,这里指的就是电脑端和手机端,同一个URL在不同的网页下,然后可能会差异很大,指的是内容和结构。如下图相同url在不同agent(pc/wise)下显示效果不同
(4)存在大量未渲染页面
可以看到我们正常一个网页是有 css和js的布局信息,通过css和js会有一个具体的网页的展示,但是由于一些网页不能进行渲染,它首先会丢掉一些布局信息,然后这在我们网页分类中造成了一定的困难。如下图中非渲染页面css/js布局信息丢失
网页区域分类
网页区域分类前面我说的分块,我们是将网页拆解成各个区域,如图所示分别是问题回答、相关推荐、提问功能等等。网页最上面是通常的一个导航区域,问题区域一般是在回答区域之前,所以可以想到这类问题和网页分类属于同样的结构,语义混合分类问题,两者其实是有异曲同工之妙的
进一步细粒度信息抽取
可以看上方图中这个例子是截取的一个中华消化病与影像杂志的这样一篇论文,它的题目是多层螺旋CT在女性盆腔非生殖源性肿瘤定位诊断中的应用价值,可以感受到缺乏相关专业知识的话对句子的划分还是有很大难度的。那么如果在搜索结果展现上,我们一定要对这个垂类进行更精细的理解,才能进行精准的匹配,满足广大用户在百度搜索相关知识时的需求

下图中我们列举了我们对文字的信息抽取的结果。当一段话被切分的如此细碎之后,之后的应用应该是十分便捷的,不管是去提取知识或者是想做细粒度的匹配,我们都有足量的信息和理解信号,能够提供给任何业务去使用,这也是我们内容理解的一个核心价值
03
自然语言处理在内容理解中存在什么样的经验和问题
对信息抽取的理解
是从自然语言文本中抽取指定类型的实体、关系、事件等信息
命名实体识别
传统的命名实体识别主要是识别人名地名和机构名,但由于传统命名实体识别是类别优先,不能完全满足自然语言处理领域其他任务的需求
细粒度命名实体识别 我们可以多定义一些专门类型,例如就一篇简历中,我们可以识别出细粒度的学校专业毕业时间、项目名称、技能点等
开放域的命名实体识别 具备类别更多且不固定,类别更细且有层次这样一个要求,也导致这一个任务的复杂度显著提升。它面临着的问题可能是没有足量的标注的序列语料,同一个命名实体属于多个不同粒度的类别,这些挑战就是无法用传统的这样一个序列标注的问题来解决
04
基于知识图谱的优质文章识别
在移动互联网大数据的时代背景下,各类的自媒体文章呈爆发式的增长,在搜索和推荐信息流分发场景下,甄别出优质文章,并分发给用户,具有重要的研究意义和实际的应用价值
任务发布
我们将任务发布在CCKS2022上,要求参赛者利用文章的知识图谱进行建模,实现优质文章分类。除了文章本身的写作质量以外,我们将把任务聚焦在两个点上,一个是文章的深度,另外是文章的新颖性。扫描下方二维码,获取活动信息
丰厚奖励等你来拿!
第一名:*敏*感*词*10000元
第二名:*敏*感*词*3000元
第三名:*敏*感*词*2000元
技术创新奖:*敏*感*词*5000元
备注:技术创新奖和前三名可以兼得
任务组织者:
曹自强 (苏州大学)
王德瑞 (百度内容策略部)
徐扬 (百度内容策略部)
谢文睿 (百度内容策略部)
任务联系人:
QQ群:471919965
曹自强:
王德瑞:
徐扬:

