从互联网上抓取网页建立索引数据库的全文搜索引擎
优采云 发布时间: 2021-05-21 18:29从互联网上抓取网页建立索引数据库的全文搜索引擎
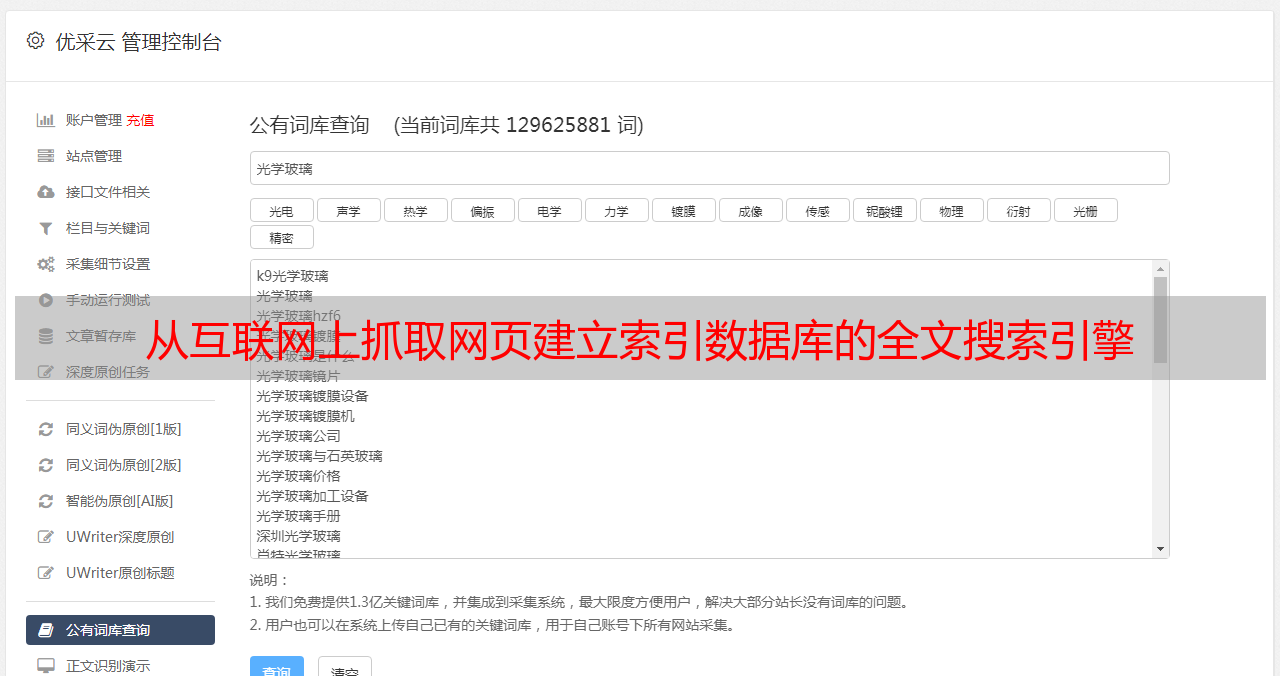
搜索引擎无法真正理解网页上的内容,只能机械地匹配网页上的文本。
真正意义上的搜索引擎通常是指在Internet上采集数千万至数十亿个网页,并对网页中的每个文本(即关键词)建立索引以建立索引数据
图书馆的全文本搜索引擎。当用户搜索某个关键词时,页面内容中收录关键词的所有网页都将被搜索出来作为搜索结果。经过复杂的算法
排序后,将根据与搜索关键词的相关程度对这些结果进行排序。
当前的搜索引擎通常使用超链接分析技术。除了分析被索引网页本身的文本之外,它还分析URL,AnchorText,甚至所有链接到网页的链接。
连接周围的文字。因此,有时,即使在某个网页A中没有诸如“ devil Satan”之类的词,如果存在另一个链接为“ devil Satan”的网页B指向该网页A,则使用
当用户搜索“魔鬼撒旦”时,他们也可以找到页面A。此外,如果还有更多页面(C,D,E,F ...)带有指向该页面的链接“魔鬼撒旦” A,或提供此链接
源页面越好
(B,C,D,E,F ...),当用户搜索“魔鬼撒旦”时,页面A的相关性越高,排名就越高。
搜索引擎的原理可以看作是三个步骤:从Internet上爬行网页→建立索引数据库→在索引数据库中进行搜索和排序。
1.从Internet上爬行网页
使用Spider系统程序,该程序可以自动从Internet采集网页,自动访问Internet并沿任何网页中的所有URL爬网到其他网页,重复此过程并进行爬网
所有已采集的网页都被采集回。
2.创建索引数据库
通过分析索引系统程序分析采集到的网页,并提取相关的网页信息(包括网页所在的网址,编码类型以及页面内容中收录的所有关键词,关键词)
位置,生成时间,大小,与其他网页的链接关系等),根据某种相关算法进行大量复杂的计算,并为文本和超链接中的每个页面计算每个网页
具有关键词相关性(或重要性),然后使用此相关信息来构建Web索引数据库。
3.在索引数据库中搜索和排序
当用户输入关键词进行搜索时,搜索系统程序将从Web索引数据库中找到与关键词匹配的所有相关网页。因为所有相关页面都与此关键词
相关
该程度已经计算出来,因此只需按现有的相关性值进行排序即可。相关性越高,排名越高。最后,页面生成系统总结搜索结果和页面内容的链接地址
内容被组织并返回给用户。
搜索引擎的蜘蛛通常会定期重新访问所有网页(每个搜索引擎的周期是不同的,可能是几天,几周或几个月,或者可能具有不同重要性的不同网页
更新频率),更新网页索引数据库以反映网页文本的更新,添加新的网页信息,删除无效链接,然后根据网页文本和链接关系的变化重新启动
排序。这样,网页的特定文本更改将反映在用户的查询结果中。
尽管只有一个Internet,但各种搜索引擎的功能和偏好是不同的,因此爬网的网页也不同,并且排序算法也不同。大型搜索引擎的数据库存储相互的
Internet上有数千万至数十亿个网页索引,并且数据量达到了数千GB甚至数万GB。但是,即使最大的搜索引擎建立了超过20亿个网页的索引数据库,也只能说明相互的
Internet上的普通网页少于30%,并且不同搜索引擎之间的网页数据重叠率通常低于70%。我们使用不同的搜索引擎的重要原因是因为它们可以分开
搜索了不同的网页。在Internet上,有很多网页无法被搜索引擎抓取并建立索引,而我们无法在搜索引擎中找到它们。
您应该牢记这个概念:搜索引擎只能找到存储在其Web索引数据库中的网页文本信息。您还应该有一个概念:如果搜索引擎Web索引数据
应该在库中,但是您没有找到它。那是你能力的问题。学习搜索技巧可以大大提高您的搜索能力。

