Newspaper:新闻类爬虫必知!
优采云 发布时间: 2022-05-02 13:21Newspaper:新闻类爬虫必知!
Newspaper框架是适合抓取新闻网页。它的操作非常简单易学,即使对完全没了解过爬虫的初学者也非常的友好,简单学习就能轻易上手,使用它不需要考虑header、IP代理,也不需要考虑网页解析,网页源代码架构等问题。这个是它的优点,但也是它的缺点,不考虑这些会导致它访问网页时会有被直接拒绝的可能。
1 newspaper安装
需要安装的是newspaper3k而不是newspaper,因为newspaper是python 2的安装包,pip install newspaper 无法正常安装,请用python 3对应的 pip install newspaper3k正确安装。
pip install newspaper3k<br />
2 直接实操上手
用一个国务院新闻的例子
# 用Article爬取单条新闻<br />from newspaper import Article<br /># 国务院某新闻网站<br />url = 'http://www.gov.cn/zhengce/content/2022-04/26/content_5687325.htm'<br /><br />news = Article(url, language='zh')<br />#第一个参数是网址,第二个常用参数是语言language,中文是以字符串'ch'表示<br />news.download() # 加载网页<br />news.parse() # 解析网页<br />print('题目:',news.title) # 新闻题目<br />print('正文:\n',news.text) # 正文内容<br />
效果如下:
识别的还可以
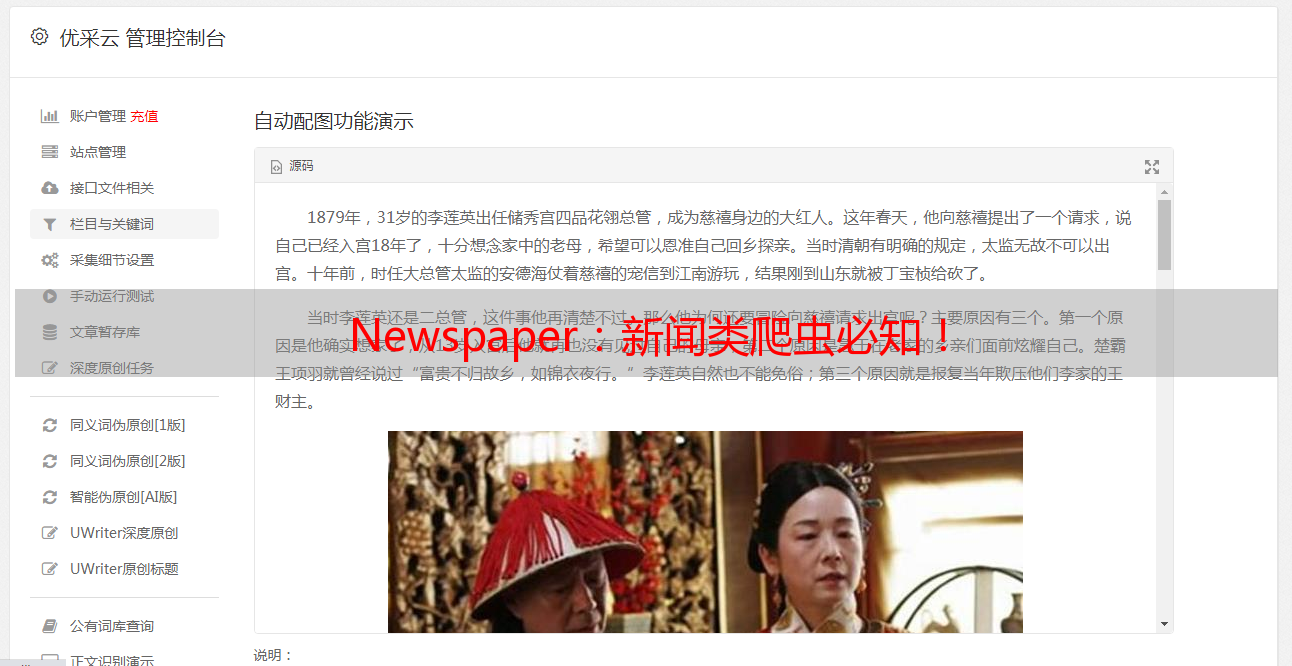
除此之外,还可以获取新闻的作者、发布时间、摘要、关键词、图片链接、视频链接等等,但是并不能100%识别,很多新闻的作者,关键词和文章摘要都无法识别出来,发布时间,图片、视频链接就基本能识别出来。
print("作者", news.authors)<br />print("发布日期", news.publish_date)<br />print("配图地址", news.top_image)<br />print("视频地址", news.movies)<br />print("新闻摘要", news.summary)<br />print("新闻关键词", news.keywords)<br />
通过newspaper.languages(),可以查看newspaper库支持的语言及其对应参数输入
3 提取网站下的新闻链接
还可以查看整个新闻源下的所有新闻链接及其数量,通过for循环,可以一一列出所有对应的新闻网页。
依某政府官方网站!
import newspaper<br />url = 'http://www.xizang.gov.cn/xwzx_406/' <br />south_paper = newspaper.build(url, language='zh')<br /># 查看新闻源下面的所有新闻链接<br />for article in south_paper.articles:<br /> print(article.url)<br />len(south_paper.articles) <br /># 查看新闻链接的数量,或者south_paper.size()
4 写入docx
首先安装docx库
pip install python-docx<br />
这里简单的基本用法就是写入标题再写入正文代码也非常简单
from docx import Document<br />document = Document()<br />document.add_heading(news.title)#写入标题<br />document.add_paragraph(news.text)#写入段落<br />document.save(f'./{news.title}.docx')#最后根据title保存<br />
docx库比较简单的用法,如果想要看其他的用法,那就点个赞吧
体验更多的功能
这个库还有其他更多的功能,大家可以参考它的官方文档:
#
也可以查看它的官方源代码:

